| Home | Papers | Reports | Projects | Code Fragments | Dissertations | Presentations | Posters | Proposals | Lectures given | Course notes |
|
|
FlowDb - getting rid of SQLWerner Van Belle1 - werner@yellowcouch.org, werner.van.belle@gmail.com Abstract : This article focuses on the creation of FlowDb, an object oriented database that replaced SQL as backend in BpmDj. The database supports a transactional memory, virtual paging, garbage collection, garbage compaction, change listeners and petri-nets.
Keywords:
object oriented databases, petri-nets, change listeners, transactional memory |
Table Of Contents
Introduction
BpmDj is a program that allows the user to mix music visually. It was initially written for Linux. In 2013 we started to create a version for Android, thereby recoding the entire codebase. BpmDj keeps track of all songs on a device, including meta data such as beatgraphs, rhythm information and tempo information. On Linux this data was saved as .index files, leading to ridiculous long loading times of 15 minutes on song collections of 80'000 songs. With the android implementation we resorted to actually using a database (miracle), yet we did not want to write our own. Therefore we relied on the SQLite implementation on Android.
Although it is always a good plan to store data in a robust, well tested database, interfacing an object oriented programming language such as Java with an SQL like interface is painful. And indeed it was. In order to get various operations working sufficiently fast, we had to batch them together in transactions that would deal with multiple objects at the same time. E.g: 10 transactions each dealing with 1 object is unreasonable slow. 1 transaction dealing with those 10 objects however was somewhat faster. The result was that the entire data processing back-end of BpmDj worked in a procedural, batch processing style. We would for instance scan the file system, sort all directory names, then assign to each directory all the files that belonged to them, then map a chunk of directory names to internal directory-ids, after which we would associate the file names with these directories, again in batch. And that is just the beginning.
After a year or so we figured this was no longer maintainable.
- the code was hard to read and hard to write
- the SQLite back-end had various disk error issues which are known but which I could not solve
- it was impossible to use the android SQLite java interface under Linux, so we could not simply port the code back to Linux.
To solve these problems once and forever we created our own database (yes another one). Goal thereby was to have the same performance as the SQLite backend, but without all the hassle. In the future this should allow us then to insert efficient reverse indices (substring matches) and it will allow us to integrate multi-dimensional nearest neigbors.
Results
Before explaining how it is done, let's first dive into the results. After moving all SQL interfacing out of the code and replacing it with FlowDB code, thereby still honoring the same batch processing as we originally wrote to satisfy SQL, thereby thus staying as close as possible to the original code, we were able to compare speed, code and size of the two BpmDj versions.
Code BpmDj with SQLite interface is 47012 lines of code. BpmDj with FlowDb is 43798 lines of code. FlowDb thus reduced the amount of code we had to write with about 3000 lines, or 93% of the original size.
Size Loading SQLite BpmDj with all data on the phone resulted in a database that was 1094378 bytes. Loading the same data in the FlowDb BpmDj resulted in 782340 bytes. This is about 70% of the original size.
Speed comparing speed between the SQLite implementation and the FlowDB implementation is tricky because SQLite is exceedingly slow in opening transactions, something which FlowDB does not have a problem with. However, once a transaction is opened SQLite appears to be slightly faster. However, that could also be related to the fact that SQLite is native C, while FlowDB is fully written in Java. Another extra complication is that everything in BpmDj has been written to make SQLite work fast, there are still many intermediate steps that are essentially unnecessary when working with our own database. So comparing the inherent strengths/weaknesses here is difficult. Generally BpmDj did not see much of a speed difference.
Given that the speed is mostly the same, yet the database size is smaller and the code is more readable/smaller, we believe FlowDb has potential to be used in other projects as well.
How is it done ?
Transaction Memory
The deepest layer of FlowDb is a transactional memory. It makes sure that changes to its memory are or are not on disk. There can never be a state in between. This is achieved using a two phased commit. First a journal is written to disk, then the journal is applied. If at any point the program crashes (or Android decides that it is fine to kill the app), then either the journal is incomplete and discarded, or complete and it can be applied. When the app crashes during application of the journal, then the journal is still complete and the changes are again applied, until they are all successfully pushed through. At that point the journal is cleared. This straightforward method guarantees atomicity
Id to Address Barrier
All objects in the database have a global id which is mapped to an address in the transactional memory. So, contrary to using direct addresses, we have an intermediate 'id to address' map. This allows us to reposition any object whenever we want, without needing to update all its referents. This is later useful for garbage collection as well as bringing objects that are accessed in the same context to the same pages.
The id to address mapping is itself (of course) in a transactional memory. Each id has 8 bytes. 1 bit for the garbage collector. 40 bits for the address in a file (allowing files of 1 TB). 8 bits to refer to the applicable file (so we can address 127 different files) and 15 bits for the type of the object.
Persistency
Objects are sequentially stored in a virtual (again transactional) memory. Every time an object changes, it is written at the end of the memory. Objects are written as their object id, the size of the object and then the content of the object, which is serialized through a compiled data model.
Loading objects happens similarly: the object is allocated in Java, then the id is mapped to the address, and the Java object filled with the content from memory by means of the compiled data model.
The wire format is similar to protocol buffers, except that some unnecessary tags have been removed. In particular, we only serialize 4 types. 1. fixed 4 bytes, 2. fixed 8 bytes, 3. variable length sections and 4. variable integers
Compaction
With the above strategy in mind, in which objects are never overwritten, and left dangling, it is necessary to occasionally compact the memory, otherwise the many holes left by objects that have been modified would hit performance by forcing us to read too many pages for too few objects. Aside from that, it is also a waste of disk space. To solve that, a straightforward compacter incrementally runs through the memory and moves all existing objects such that they touch each other again. Thereby empty space bubbles upward until the next-free pointer can be moved back again. This is easily done because we have an id/address barrier in place.
Paging: virtual to actual
When we investigated the above overall strategy, we found a major performance problem. Whenever we saved something, we would first write the object to the journal, after which we would apply it on disk. That was a waste of time because we had to write each object 2 times instead of once.
To realize an immediate write to the actual file, we reinvented a virtual page mapping, which would map virtual pages to actual pages in the file. E.g: virtual page 553 could be mapped to actual page 0 in the file. At a later point the same virtual page could map to another actual page. By allowing such indirection, we were able to merge to journalling into the transactional memory. The idea is as follows: the object data is directly written into pages that we know are empty (so even if the write process fails, those pages are not supposed to be read anyway, so there is no problem). Then, those pages are marked as the new actual pages for a specific virtual page. That meta information (which is a lot less data), is then written to the journal, thereby still guaranteeing atomicity.
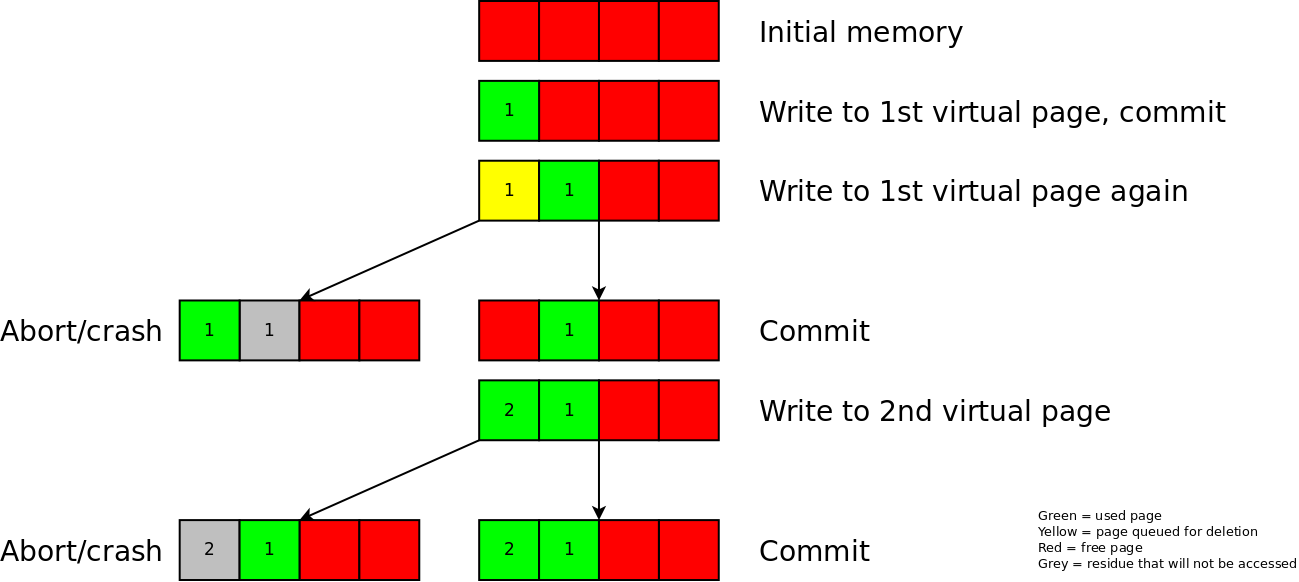
|
Deleting virtual pages is a tricky operation though. If we were to delete a virtual page and directly allow the program to write in it, then we would not be able to guarantee a rollback because as far as the committed memory was concerned, that page would still be used. Therefore, it is important to mark a virtual page as 'queued for deletion', and only after the next commit mark it as 'truly deleted'.
An advantage of this system is also that we can release pages during the compaction stage. As soon as the compaction-write pointer and read pointer span more than 1 page, that page can be marked as 'deleted'.
Object change notification
A typical problem with databases is that it would be nice to know which objects changed, and have that information present in a persistent and reliable manner. In FlowDb this problem is solved by attaching to each factory a set of changes. That change set simply tracks the objects that changed. Next to this direct change set, there are various listeners, each with their own name. Occasionally, the direct changes are propagated through to the various listeners.
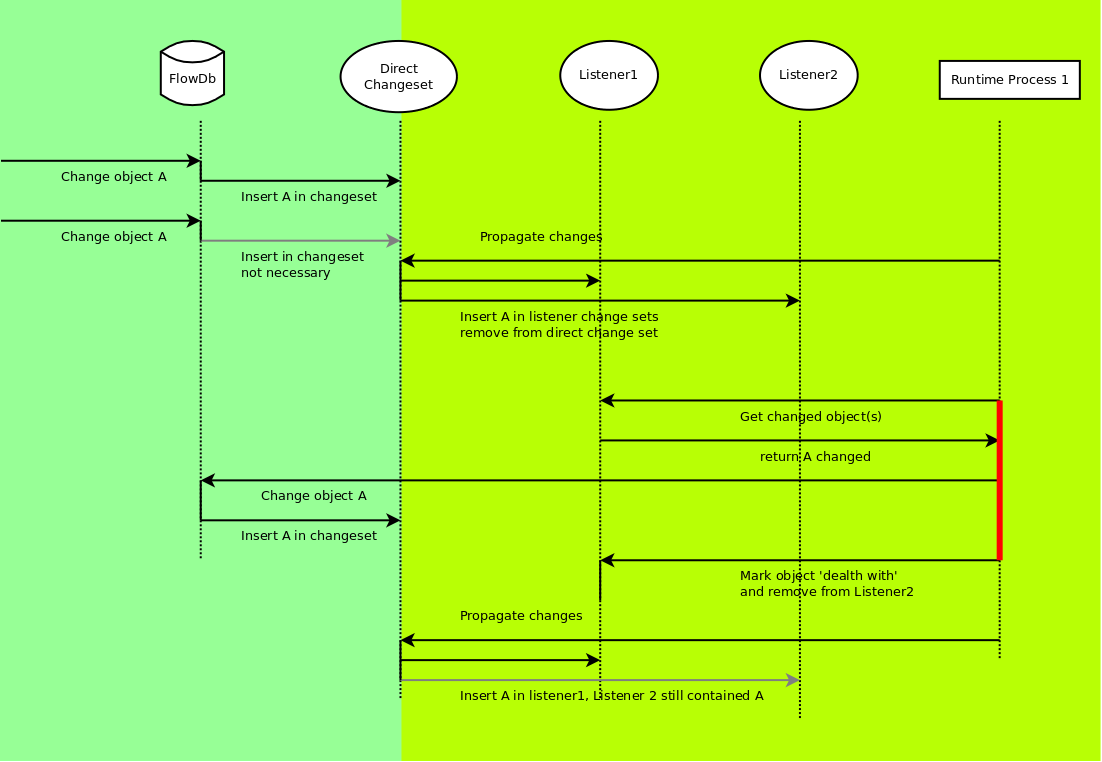
|
The above picture illustrates how this works. The green section is the area that works fast and is, from a bandwidth perspective, totally independent from the lime section. If updates comes in faster than the runtime can process them, they mainly end up in the direct changeset. The lime section on the other hand has a type of 'transactional' approach to dealing with changes. A change is peeked first from the listeners changeset. The program can then react to those changes, and only after the change has successfully been dealt with, will the changes be removed from the listener. During the peeking of a change and removing the change, no change propagation to the listeners can take place (The red line indicates a lock on the relevant listeners)
This setup ensures that the runtime will always see an object change, even if we are currently dealing with and removing it from the listener. E.g: object A changes. It is placed in the direct change list. Then it is moved to the listeners named L1 and L2. If L1 now processes A, it can modify A again, triggering an insert into the direct change list. After that L1 can remove A, however in the next iteration it will again receive a notification that A changed.
Indices & iterators
FlowDb comes with an implementation of a blocktree, that can accept any comparator. Each index can be traversed forward and backward, and partial keys can be used to locate elements that are 'close enough'. That is important because it allows us to use 1 index to solve two problems. E.g: we have an object with 'title' and 'author' fields. If we create an index on title and author, then we can use that index to find all objects that match a specific title and author combination, but we can also use it to find the first object that matches a specific title. Fewer indices => faster update speeds.
Indices are always updated when the object changes. There is no reason to delay this process since we would merely delay the work we have to do anyway. And delaying updates could make it also somewhat tricky to load an object that was modified, yet was not indexed, not to speak of the problem of actually finding the objects that have not yet been reindexed. The code to deal with such delay is difficult and not worth it.
The database does not compile queries. Initially we thought to need some form of langauge support (LINQ) or other language like features to traverse the DB, but in the end it just turned out to be much easier using iterators over the blocktree.
Compiler
Objects have two representations. One at runtime and one in persistent memory. Objects are loaded through a factory, which guarantees that each object id maps uniquely to a runtime object. The runtime object needs to know how to load and save itself. Objects are annotated with a type. That is necessary because the garbage collector needs some method to retrieve the referenced object from file. The runtime representation of objects is compiled from a datamodel. It specifies for each object
- Required: its name
- Optional: its implementation class
- Whether it has a factory
- Optional: the factory implementation class
- The fields in the object. These can include strings, integers, floats, object references, internal objects and repetitions of the beforementioned types.
- Field combinations that should have an index
- Field combinations that require a setter
The compiler generates code to save/load the objects and to change the objects. When objects are changed, the various indices are automatically updated.
Concurrency
Transactions as such, do not exist in the system. The state is either committed or not, there is no possibility to roll back (except from crashing the program and restarting). There is however a concurrency strategy in place which exists solely of a global lock. Whenever the lock is fully released it will check whether a commit is sensible. There are multiple factors that come into this decission
- how long ago did a commit take place ? It makes no sense to commit data 1000 times a second.
- Is there sufficient data to have a commit that will fill at least a page ? If not, there is an unnecessary overhead by committing.
- Is it necessary that the data is now on disk (this can be notified to the DB). E.g: whenever an analysis of a song starts, it is necessary that the db on disk is updated. If it isn't and the song analysis causes a crash then the program might go into a restarting loop.
Aside from providing a straightforward top-down approach to locking, the locking stack that is created during debug runs, allows us to profile various sections within virtual transactions.
Garbage Collection
Garbage collection of a database is not the same as garbage collection of a runtime memory. The latter is often written, rewritten and used from various angles. A database on the other hand is mostly used to retrieve data. Therefore we have split the garbage collector into 3 different sections
1. marking objects that are still in use. This is done incrementally by retrieving objects from disk, checking their references and adding them to a gc queue. When an object changes during garbage collection it is automatically added to this queue. Even if we already investigated it before.
2. When all objects have been marked, we run through the id/address barrier and delete all objects that are no longer necessary. This deletion does not require us to access the data on disk. Avoiding a bunch of scattered reads.
3. Eventually, when a file on disk is believed to have sufficient 'holes' a compactor (described above) runs through the virtual memory and rewrites all objects to a new position.
The garbage collector is automatically run, when necessary, at the end of a transaction.
Statistics
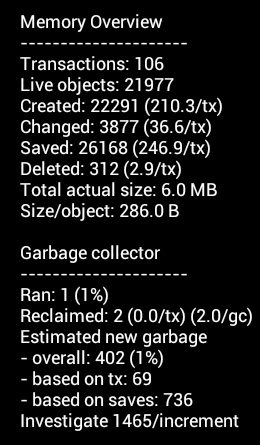
During execution, a number of statistics are gathered:
- Transactions – specifies how many times a commit has been performed.
- Live Objects – specifies how many objects are currently accessible
- Created Objects – specifies how many objects we created since the start of the system
- Changed Objects – specifies how many objects have been changed since the start of the system
- Saved Objects – how many times an object was save (the sum of created or changed)
- Deleted Objects – how many objects were consciously deleted (only the blocktree deletes its own nodes at the moment. All the rest goes through the garbage collector)
- Total actual size – how many pages do we use on disk ?
- Size/Object – from that we can obtain an overall estimate on how many bytes we use per live object.
Aside from these overall statistics, we also aggregate statistics for the garbage collector
- Ran: how many times we ran it. The percentage specifies in how many % of the transactions a garbage collector runs.
- Reclaimed: how many objects were reclaimed in total. Divide it by the number of transactions to understand how much garbage is created per transaction. Divide it by the number of garbage collector runs to know how much garbage is reclaimed per GC.
From all these number it becomes possible to estimate how much new garbage we expect. We can do this either based on the number of transactions since the last collection, or on the number of saved objects. It furthermore helps us to estimate how many objects we must investigate per incremental transaction run if we don't want to lag so much behind the transactions that we will never reach completion.
Code example
The two columns below are a 'before' and 'after' check. Beware that the new code is still horrible. That is because it has been mainly made compatible with the old interface. E.g: the (unnecessary) batch processing is still in place, and various static creators are also present. However, there is not much else to do if you want to compare two pieces of code. They must have the same interface, otherwise the comparison wouldn't show a thing.
public class FileToken extends Token<FilesPlace> implements Comparable<FileToken>
{
public Directory directory;
public String filename;
public int fileId;
public long timeStamp;
public FileToken(FilesPlace place, Directory parentDirectory, String entry)
{
super(place);
fileId=Ids.next();
filename=entry;
directory=parentDirectory;
created();
}
public FileToken(FilesPlace place, Cursor cursor)
{
super(place,cursor);
}
@Override
protected void load(Cursor cursor)
{
final int fileIdCol = cursor.getColumnIndex(FilesPlace.FILE_ID);
final int parentDirCol = cursor.getColumnIndex(FilesPlace.FILE_DIR);
final int timeStampCol = cursor.getColumnIndex(FilesPlace.FILE_TIMESTAMP);
final int filenameCol = cursor.getColumnIndex(FilesPlace.FILE_NAME);
directory = Directories.create(cursor.getInt(parentDirCol));
filename=cursor.getString(filenameCol);
fileId=cursor.getInt(fileIdCol);
timeStamp=cursor.getLong(timeStampCol);
}
public void checkTimeStamp()
{
File file = getFile();
if (file.exists() && file.canRead())
{
long newTimeStamp=file.lastModified();
if (newTimeStamp!=timeStamp)
{
timeStamp=newTimeStamp;
changed();
}
}
}
private static Atomic SET_TIMESTAMP=new Atomic(FileToken.class,"setTimeStamp");
public void setTimeStamp(long newTimeStamp)
{
if (newTimeStamp!=timeStamp)
{
SET_TIMESTAMP.lock();
timeStamp=newTimeStamp;
changed();
SET_TIMESTAMP.unlock();
}
}
public File getFile()
{
return new File(directory.dir,filename);
}
@Override
public String toString()
{
return getFile().toString();
}
static final private ContentValues FAAIL_VALUE_HELPER=new ContentValues();
@Override
protected void replace(SQLiteDatabase db)
{
FAAIL_VALUE_HELPER.clear();
FAAIL_VALUE_HELPER.put(FilesPlace.FILE_ID, fileId);
FAAIL_VALUE_HELPER.put(FilesPlace.FILE_NAME, filename);
FAAIL_VALUE_HELPER.put(FilesPlace.FILE_TIMESTAMP,timeStamp);
FAAIL_VALUE_HELPER.put(FilesPlace.FILE_DIR,directory.directoryId);
db.insertWithOnConflict(place.table, null, FAAIL_VALUE_HELPER, SQLiteDatabase.CONFLICT_REPLACE);
BpmDjGlobal.log("FileToken Updated file " + filename + " id " + fileId); //X
}
@Override
protected void delete(SQLiteDatabase db)
{
db.delete(FilesPlace.FILES_TABLE, FilesPlace.FILE_ID+"="+fileId, null);
}
@Override
public int compareTo(FileToken another)
{
final int oid=another.fileId;
if (fileId<oid) return -1;
if (fileId>oid) return 1;
return 0;
}
}
public class FilesPlace extends Place<FileToken>
{
public final static String FILES_TABLE = "Files";
final public static String FILE_ID = "_id";
final public static String FILE_DIR = "directory";
final public static String FILE_NAME = "filename";
final public static String FILE_TIMESTAMP = "timeStamp";
public final static TreeMap<Integer,FileToken> FILEID_TO_FILETOKEN = new TreeMap<Integer, FileToken>();
public final static String[] FAAIL_COLUMNS = {FILE_ID, FILE_NAME, FILE_TIMESTAMP, FILE_DIR};
@Override
protected void tokenCreated(FileToken f)
{
Directory parentDirectory=f.directory;
parentDirectory.filesInDir.put(f.filename, f);
FILEID_TO_FILETOKEN.put(f.fileId, f);
}
@Override
protected void tokenLoaded(FileToken f)
{
Directory parentDirectory=f.directory;
parentDirectory.filesInDir.put(f.filename, f);
FILEID_TO_FILETOKEN.put(f.fileId, f);
}
public FilesPlace()
{
super(FILES_TABLE);
}
@Override
protected void setupDescription()
{
addKey(FILE_ID, "INTEGER", "PRIMARY KEY AUTOINCREMENT");
addCol(FILE_DIR,"INTEGER");
addCol(FILE_NAME,"TEXT");
addCol(FILE_TIMESTAMP,"LONG");
setConstraint("CONSTRAINT pk UNIQUE (" +
FILE_DIR + "," +
FILE_NAME + ")");
}
final private static Atomic HAVE_OR_LOAD=new Atomic(FilesPlace.class,"haveOrLoad");
private FileToken haveOrLoad(int fileId)
{
SQLiteDatabase db=HAVE_OR_LOAD.lock();
if (FILEID_TO_FILETOKEN.containsKey(fileId))
{
HAVE_OR_LOAD.unlock();
return FILEID_TO_FILETOKEN.get(fileId);
}
Cursor cursor=db.query(table,FilesPlace.FAAIL_COLUMNS, FILE_ID+"="+fileId, null, null, null, null);
cursor.moveToFirst();
if (cursor.isAfterLast())
BpmDjGlobal.fatal("Cannot retrieve entry for file id " + fileId);
FileToken result=new FileToken(this,cursor);
cursor.close();
HAVE_OR_LOAD.unlock();
return result;
}
final private static Atomic HAVE_LOAD_OR_CREATE=new Atomic(FilesPlace.class,"haveLoadOrCreate");
private FileToken haveLoadOrCreate(String str)
{
SQLiteDatabase db = HAVE_LOAD_OR_CREATE.lock();
int idx = str.lastIndexOf(File.separator);
String directory = str.substring(0,idx+1);
idx++;
String filename = str.substring(idx);
Directory dir = Directories.create(directory);
FileToken result;
if (dir.filesInDir.containsKey(filename))
result=dir.filesInDir.get(filename);
else
{
result = haveLoadOrCreate(db,dir,filename);
}
HAVE_LOAD_OR_CREATE.unlock();
return result;
}
final static private String PREPPED_STAT=FilesPlace.FILE_NAME+"=? AND "+FilesPlace.FILE_DIR+"=?";
final static private String[] args=new String[2];
private FileToken haveLoadOrCreate(SQLiteDatabase db, Directory dir, String filename)
{
FileToken faail=dir.filesInDir.get(filename);
if (faail!=null) return faail;
args[0]=filename;
args[1]=Integer.toString(dir.directoryId);
Cursor cursor=db.query(table, FilesPlace.FAAIL_COLUMNS, PREPPED_STAT, args, null, null, null);
final int cnt=cursor.getCount();
if (cnt==0)
{
faail=new FileToken(this, dir,filename);
}
else if (cnt==1)
{
cursor.moveToFirst();
faail = new FileToken(this,cursor);
}
else
{
BpmDjGlobal.fatal("More than one 'unique' file object (instance 1).");
faail=null;
}
cursor.close();
return faail;
}
static public FileToken create(int fileId)
{
FileToken result = Application.DB.files.haveOrLoad(fileId);
return result;
}
final private static Atomic CREATE=new Atomic(FilesPlace.class,"create");
public static FileToken create(String str)
{
CREATE.lock();
FileToken result = Application.DB.files.haveLoadOrCreate(str);
CREATE.unlock();
return result;
}
static public FileToken create(File file)
{
String str;
try
{
str = file.getCanonicalPath();
}
catch (IOException e)
{
e.printStackTrace();
return null;
}
return create(str);
}
final static int STEPS_PER_TX=100;
final private static Atomic BATCH_CREATE=new Atomic(FilesPlace.class,"create(batch)");
public static FileToken[] create(ArrayList<File> directories, ArrayList<String> filenames, FsScanner listener)
{
FileToken[] result=new FileToken[filenames.size()];
Directory[] dirs=Application.DB.directories.create(directories,listener);
int oldPct=-1;
for(int i = 0 ; i < result.length; )
{
int nextStop = Math.min(result.length, i+STEPS_PER_TX);
SQLiteDatabase db = BATCH_CREATE.lock();
db.beginTransaction();
try
{
while (i<nextStop)
{
Directory dir = dirs[i];
String filename = filenames.get(i);
FileToken faail=Application.DB.files.haveLoadOrCreate(db, dir,filename);
result[i++]=faail;
}
db.setTransactionSuccessful();
}
catch (Exception e)
{
BpmDjGlobal.exception(e);
}
finally
{
db.endTransaction();
BATCH_CREATE.unlock();
}
int pct=(i+1)*100/(result.length);
if (pct!=oldPct)
{
if (listener!=null)
listener.integratingFiles_anal(pct);
oldPct=pct;
}
}
return result;
}
}
|
public class FileToken extends FileTokenBase
{
public void checkTimeStamp()
{
File file = getFile();
if (file.exists() && file.canRead())
{
long newTimeStamp=file.lastModified();
setTimeStamp(newTimeStamp);
}
}
private static RwLock SET_TIMESTAMP=new RwLock(FileToken.class,"setTimeStamp");
public void setTimeStamp(long newTimeStamp)
{
if (newTimeStamp==timeStamp) return;
SET_TIMESTAMP.write();
super.setTimeStamp(newTimeStamp);
SET_TIMESTAMP.unlock();
}
public File getFile()
{
return new File(directory.get().toString(), filename.toString());
}
@Override
public String toString()
{
return getFile().toString();
}
public String dir()
{
return directory.get().toString();
}
}
public class FileTokenFactory extends FileTokenBaseFactory
{
public FileTokenFactory(Memory mem)
{
super(mem);
}
final private static RwLock HAVE_OR_LOAD=new RwLock(FileTokenFactory.class,"haveOrLoad");
public FileToken haveOrLoad(int fileId)
{
HAVE_OR_LOAD.read();
FileToken result = super.haveOrLoad(fileId);
HAVE_OR_LOAD.unlock();
return result;
}
private DirectoryFilenameIndex.Iterator findFile;
@Override
public void setupIndices()
{
super.setupIndices();
findFile=directoryFilename.new Iterator();
}
final private static RwLock HAVE_LOAD_OR_CREATE=new RwLock(FileTokenFactory.class,"haveLoadOrCreate");
private FileToken haveLoadOrCreate(String str)
{
HAVE_LOAD_OR_CREATE.write();
int idx = str.lastIndexOf(File.separator);
String directory = str.substring(0,idx+1);
idx++;
String filename = str.substring(idx);
Directory dir = DirectoryFactory.create(directory);
FileToken result = haveLoadOrCreate(dir,filename);
HAVE_LOAD_OR_CREATE.unlock();
return result;
}
private FileToken haveLoadOrCreate(Directory dir, String filename)
{
findFile.directory.set(dir);
findFile.filename.set(filename);
findFile.matchForward();
FileToken result=findFile.next();
if (result==null)
{
result=FileToken.create();
result.setDirectoryFilename(new DirectoryRef(dir),findFile.filename);
}
return result;
}
static public FileToken create(int fileId)
{
return FileToken.FACTORY.haveOrLoad(fileId);
}
final private static RwLock CREATE=new RwLock(FileTokenFactory.class,"create");
public static FileToken create(String str)
{
CREATE.write();
FileToken result = FileToken.FACTORY.haveLoadOrCreate(str);
CREATE.unlock();
return result;
}
static public FileToken create(File file)
{
String str;
try
{
str = file.getCanonicalPath();
}
catch (IOException e)
{
e.printStackTrace();
return null;
}
return create(str);
}
final static int STEPS_PER_TX=100;
final private static RwLock BATCH_CREATE=new RwLock(FileTokenFactory.class,"create(batch)");
public static FileToken[] create(ArrayList<File> directories, ArrayList<String> filenames, FsScanner listener)
{
FileToken[] result=new FileToken[filenames.size()];
Directory[] dirs=Directory.FACTORY.create(directories,listener);
int oldPct=-1;
for(int i = 0 ; i < result.length; )
{
int nextStop = Math.min(result.length, i+STEPS_PER_TX);
BATCH_CREATE.write();
try
{
while (i<nextStop)
{
Directory dir = dirs[i];
String filename = filenames.get(i);
FileToken faail=FileToken.FACTORY.haveLoadOrCreate(dir,filename);
result[i++]=faail;
}
}
catch (Exception e)
{
BpmDj.exception(e);
}
finally
{
BATCH_CREATE.unlock();
}
int pct=(i+1)*100/(result.length);
if (pct!=oldPct)
{
if (listener!=null)
listener.integratingFiles_anal(pct);
oldPct=pct;
}
}
return result;
}
}
|
| http://werner.yellowcouch.org/ werner@yellowcouch.org |  |