| Home | Papers | Reports | Projects | Code Fragments | Dissertations | Presentations | Posters | Proposals | Lectures given | Course notes |
Aanvraag IWT Specialisatiebeurs: Positie Optimalisering binnen Mobiele Multi-Agent SystemenWerner Van Belle1* - werner@yellowcouch.org, werner.van.belle@gmail.com Abstract : A brand new programming paradigm is that of mobile software agents. One is now able to move an agent from one machine to another while its execution state remains intact. It is clear that interaction between two agents on the same host is much faster than the same interaction between agents on different hosts. Because of this the performance of these systems can be finetuned by moving agents to the same location if they are interacting enough. (This is done of course while the system is running.) The only problem is the unpredictability of the interaction patterns between the agents. For this reason we can't make these systems run globally better than open distributed systems. We can't predict that agent A should always be near agent B in order to enhance performance. In this doctoral study we want to develop the necessary algorithms and methodologies to automate the distribution of mobile agents, with the main purpose of obtaining better global performance. The methodology we will use consists of moving agents towards each other. If agents interact on a local machine an after the interaction retract to their original position it is possible to lower the response time. This will be done by an additional management layer to existing mobile multi-agent systems. This extra will be able to reason about the agents' positions at a different, higher level, while the agents carry out their tasks. On this level we will develop some models to describe the task execution of the agents (how they respond to certain messages, what their standard behavior is and so on). It is important to know that these models will only use local information. After the agent models we will develop algorithms to fulfill our Quest, that is, an automated higher global performance. To achieve this we will look at genetic programming, subsymbolic statistic techniques and learning techniques like reinforcement learning.
Keywords:
Mobile Multi Agent Systems, distributed load balancing, mobile objects, distributed applications |
Probleemstelling
Ontwikkelaars van client/server toepassingen weten dat het vastleggen van de functionaliteit van de client en de server reeds in de startfase van een project moet gebeuren. De beslissing die hierrond gemaakt wordt is vaak ad hoc en houdt nauwelijks rekening met de performantie van het gehele systeem. Dit wordt bijvoorbeeld geïllustreerd door user interfaces die enkel aan de client-zijde werken en waarbij alle bewerkingen aan de server-zijde verricht worden (VT100 terminals, Netscape en andere). De performantie van het geheel is bijgevolg zeker niet optimaal. We zien hier tegenwoordig een (noodzakelijke) verandering in komen, onder de vorm van applets door de extra rekenkracht van de client ook te benutten, maar conceptueel blijft er een probleem van schaalbaarheid. In de praktijk wordt hierom de communicatie tussen client en server zo laag mogelijk gehouden, dit natuurlijk ten koste van abstracties en performantie.
Om deze computationele onmacht te lijf te gaan evolueert men langzaam van client/server computing naar open gedistribueerd rekenen. Binnen deze systemen heeft men componenten die op verschillende plaatsen kunnen uitgevoerd worden, en die op basis van hun interface en functionaliteit worden samengesteld. Een voorbeeld hiervan zijn services binnen internet, zoals sendmail daemons, HTTP daemons, FTP daemons en andere services. Deze services zijn op relatief losse wijze met elkaar geconnecteerd, dit naar gelang de behoeften van de organisaties in kwestie. Het kenmerkende aan dergelijke systemen is dat de aanwezige componenten niet noodzakelijk dezelfde eigenaar hebben (vandaar de term: open gedistribueerde systemen). Het nadeel met dergelijke systemen is dat de abstractie vaak zoek is en dat er geen overzicht te houden is over de gehele situatie. Dit heeft als gevolg dat de uiteindelijke performantie van dergelijke systemen zeker niet is wat ze zou kunnen zijn. Services binnen grote gedistribueerde systemen worden bijna op random plaatsen gelegd en het komt maar al te vaak voor dat we een nodeloze ping pong tussen ver afgeleven services waarnemen. Systeembeheerders zullen er natuurlijk wel steeds voor zorgen dat het systeem relatief performant werkt, maar dit zijn steeds lokale oplossingen. Hoeveel performanter het systeem globaal gezien nog kan draaien blijft een open vraag.
Een verder stadium van gedistribueerd rekenen dat men vandaag onderzoekt betreft mobiele agent systemen. Deze recente vorm van gedistribueerd programmeren bestaat eveneens uit het samenstellen van componenten op basis van hun interface, met het grote verschil dat de componenten mobiel zijn (men spreekt in deze context dan ook niet meer over componenten maar wel over agenten). Men kan zich dit inbeelden als sendmail daemons of data servers die in staat zijn zichzelf naar andere machines te verplaatsen naarmate dit nodig is. Het probleem met deze nieuwe ontwikkeling is dat er nog maar weinig testen gedaan zijn op de industriële toepasbaarheid van agent systemen. Desalnietemin kunnen mobiele agent systemen de mogelijkheid bieden om aan positiemanagement te doen. Dit wil zeggen dat de beheerder van een netwerk in staat is, afhankelijk van de noodzaak, bepaalde agents (services) te verplaatsen naar andere machines. Omdat de praktische oplossing nog steeds ad hoc en manueel uitgevoerd wordt zal de globale performantie niet veel beter zijn dan binnen een open gedistribueerd systeem. En dit is wel degelijk een probleem. Mobiele multi agent systemen hebben voor de industrie relatief weinig direct belang als er geen performantieverbetering bij komt.
De voor de hand liggende stap die men nu met mobiele agent systemen dient te zetten is het automatisch positioneren van agenten binnen een netwerk, met als hoofdbedoeling een globale performantiewinst te krijgen. Het voornaamste probleem hierbij is dat we geen overzicht hebben over het netwerk zodra we binnen een dynamisch wijzigende omgeving werken.
Doelstelling
In de literatuur treffen we voldoende stof aan die deze planningsproblemen benadert. Nochtans zijn dit steeds maar partiële oplossingen. Laten we de bestaande methodologieën overlopen. Een eerste methode past bestaande algoritmen aan zodat ze performanter werken binnen een specifieke gedistribueerde omgeving. Hierbij worden positioneringscode en uitvoeringscode met elkaar verweven. Dit leidt tot een onbeheersbaar amorf geheel, waarbinnen we op geen consistente wijze over positionering kunnen redeneren. Een tweede methode vinden we terug in de wereld van de Artificiële Intelligentie, waar men massa's offline rekenkracht gebruikt om een vlotte planning te verzekeren. Gezien de constraints van het probleem (tijdsgebonden en schaalbare positieplanning), blijken deze offline benaderingen ook ontoerijkend. Een derde methode gaat ervan uit dat men een globaal beeld heeft van de gehele werkomgeving. Buiten het feit dat dit niet realiseerbaar is binnen een internet omgeving, mag men er ook niet vanuit gaan omdat het volledige netwerk niet dezelfde eigenaar heeft. Men kan dus onmogelijk op voorhand het gedrag van de gemiddelde agent voorspellen. Een laatste methode betreft lerende algoritmen via bijvoorbeeld reinforcement learning, die enkel werken binnen statische omgevingen.
Het uiteindelijke resultaat is dat er op dit moment geen methoden zijn om aan automatische positie planning1 te doen binnen mobiele mult agent systemen. Hoewel het probleem op zich onoplosbaar is aangezien er geen definitie van ‘beste’ performantie is, zullen we in dit onderzoek toch de nodige hulpmiddelen en (gevalideerde) heuristieken aanreiken die een veel betere performantie garanderen dan de performantie die manueel bekomen kan worden.
Samengevat willen we de impliciete distributie afstraffing, zijnde wachttijden over afstand, indijken ten voordele van de performantie van het globale systeem.
De methodologie die we hiervoor zullen gebruiken bestaat eruit een zelf ontwikkeld mobiel multi agent systeem uit te breiden met positiebeheer.2 Dit wil zeggen dat we op een hoger niveau kunnen nadenken over de positie van de agenten terwijl zij op zich hun taak uitvoeren.
Het is op dit beheersniveau dat we een aantal modellen zullen ontwikkelen die de taakuitvoering van agenten beschrijft (hoe gedragen ze zich, hoe reageren ze op bepaalde berichten, wat verwachten ze van hun omgeving). We merken hierbij op dat we ons slechts kunnen baseren op lokale waarnemingen zonder globale verificatie omdat we binnen een wide area netwerk (kunnen) werken. Bijgevolg zal elk ontwikkeld model altijd partieel zijn. Het is uiterst noodzakelijk een goed model te ontwikkelen. Dit model zal toepasbaar zijn op wide area networks waarbinnen men onvoorspelbare wachttijden aantreft.
Eens we weten hoe een agent uitgaande van lokale waarnemingen binnen het dynamische systeem een schatting kan maken van de globale situatie, zullen we trachten de gehele omgeving sneller te laten werken. Algoritmen die daarvoor in aanmerking komen zijn heuristieken, leertechnieken en subsymbolische statische technieken.
Gedetailleerd onderzoeksvoorstel
Het gedetailleerde onderzoeksvoorstel is gestructureerd als volgt: het eerste deel bestaat uit een korte studie van bestaande agentsystemen. Hierin schuiven we de technische beperkingen van agentsystemen naar voor en lichten een nieuw zelf ontwikkeld agentsysteem toe. Dit nieuwe agentsysteem is hetgeen we zullen gebruiken tijdens het onderzoek. Het tweede deel beschrijft de realistische case die we zullen gebruiken in de rest van het onderzoek. Het derde deel handelt over hoe we lokaal een geschikt model kunnen ontwikkelen dat het gedrag van een agent beschrijft. In dit onderdeel zullen we duidelijk bepalen waaraan een dergelijk model moet voldoen en hoe we het model zullen trachten te ontwikkelen. Uiteindelijk streven we naar de ontwikkeling van algoritmen die gebruikt kunnen worden om mobiele agentsytemen te versnellen. In elk deel bespreken we hoe we dit in de praktijk zullen uitvoeren.
Aangaande de vorm van de tekst zullen we in de voetnoten eenvoudige verklaringen geven van begrippen en afkortingen. Er wordt daarentegen wel een basiskennis van objectgerichte talen zoals Java verwacht. We hebben zoveel mogelijk getracht algemeen nederlands te gebruiken in de tekst, waar het nodig was om de verstaanbaarheid van de tekst niet in het gedrang te brengen hebben we de oorspronkelijk engelse term behouden.
1. Agentsystemen
Introductie
Het concept Agent kan uit verschillende hoekpunten benaderd worden.
Enerzijds komen agentsystemen voort uit het domein van de Artificiële Intelligentie. Het begrip agent verwijst daar hoofdzakelijk naar intelligente robots die in naam van hun eigenaar bepaalde acties vereenvoudigen en verbergen. Agenten waren in deze optiek kenmerkend intelligent en autonoom, omdat ze zelf beslissingen konden nemen in naam van de gebruiker. We noemen dit soort agenten tegenwoordig user interface agenten omdat ze vaak enkel de user interface intelligenter maken. Een typisch voorbeeld hiervan is de Paper Clip die in Microsoft Word zit .
Na verloop van tijd begon men in te zien dat dergelijke agenten misschien nuttig zijn in een ruimer domein dan enkel user interface verbeteraars, zoals het werk van Pattie Maes en ander duidelijk illustreert . De klemtoon verschoof langzaam van user interface agenten naar interface agenten die internet afschuimen op zoek naar informatie. Deze agenten blijven weliswaar op een vaste plaats maar exploreren toch internet door het web te browsen. Weinig van deze agenten hebben dus echt een ‘mobiel’ gedrag, desalniettemin is de aanzet voor mobiele multi agent systemen duidelijk aanwezig.
Een ander hoekpunt van waaruit we agenten kunnen benaderen is vanuit distributie. Tesamen met de evolutie van software agenten kwam de industrie in aanraking met agenten om bepaalde performantieproblemen van gedistribueerde applicaties op te lossen, zoals beschreven is in de probleemstelling. Hiervan kan het onderzoek binnen Tromsø (Noorwegen) getuigen, waar men met behulp van een wereldwijd gedistribueerde applicatie het weer tracht te voorspellen (StormCast & Tacoma ). Des te meer bieden mobiele multi agent systemen veel beter de mogelijkheid intelligente agenten te schrijven dan huidige programmeertalen.
Mobiele multi-agent systemen
Om verwarring te vermijden geven we een aantal algemeen aanvaarde definities voor agenten, mobiele multi agenten en agentsystemen:
Een agent is een actieve autonome software component. Men kan hierbij denken aan een process dat ergens runt en een service voorziet. Elke agent kan gebruik maken van een eigen code en data ruimte.
We praten over multi agenten als twee dergelijke agenten in staat zijn met elkaar te communiceren. Afhankelijk van het agentsysteem wordt deze communicatie gedaan op basis van RPC3 of RMI4 of het uitwisselen van een of andere verzameling regels (KIF). Dit houdt ook vaak asynchrone communicatie in.
Een mobiele agent is een agent die in staat is zich tussen verschillende machines te verplaatsen, of om het iets abstracter te zeggen, een agent die in staat is tussen verschillende plaatsen te migreren. In één van de volgende sectie zullen we praten over migratie.
Een mobiel multi agent systeem is een architectuur of een taal die voldoende flexibiliteit aanbied om mobiele multi agenten in te schrijven. Dit houdt in dat het systeem zich bezig houdt met serializatie van berichten, routering van berichten, interconnectie met andere agentsystemen, processplanning, veiligheid en migratie. Dit natuurlijk zonder al te veel gebruikerstussenkomst. Deze eisen bespreken we kort in de volgende sectie.
Eisen gesteld aan mobiele multi agent systemen
Open gedistribueerde systemen hebben een aantal duidelijke eisen die vrijwel onmiddelijk overdraagbaar zijn op multi agent systemen.
-
Benaming: men moet in staat zijn agenten5 te benoemen om te kunnen communiceren.
-
Modulariteit: agenten moeten modulair samengesteld kunnen worden. De interface tot de componenten moet uniform zijn.
-
Homogeniteit: de werking van een agent mag niet afhangen van de plaats van de agent. De agent moet zowel op Sparc stations als op Intel klonen draaien.
-
Beheersbaarheid: men moet op uniforme wijze in staat zijn agenten te beheersen. Men moet op eenvoudige wijze agenten kunnen herstarten, stoppen, bewaren en binnenladen.
-
Fout tolerantie: fouten moeten zo goed mogelijk opgevangen zorden.
-
Routering en interconnectie met andere agent systemen: berichten moeten tussen verschillende agenten kunnen uitgewisseld worden.
-
Communicatie sessies die toelaten dat verschillende agenten met elkaar communiceren en dat ze niet onderbroken worden. Dit houd eventueel een transactie systeem in.
-
Veiligheid: van zodra men buiten een LAN6 gaat wil men niet zomaar al de interne services (agenten) beschikbaar maken voor de buitenwereld.
Als we specifiek aan mobiele multi agent systemen denken komen hier nog een aantal eisen bij:
-
Lokatie transparantie: we willen in staat zijn te communiceren met agenten, zelfs als deze verplaatst zijn.
-
Veiligheid: In tegenstelling tot statische agenten, die het probleem hebben dat verzonden, vertrouwelijke data onderschept kan worden, hebben agenten ook het probleem dat de machine waarop ze draaien vertrouwelijke data rechtstreeks uit de agent kunnen halen.
-
Beheersbaarheid wordt iets moeilijker aangezien agenten in staat zijn te migreren.
In de praktijk lost men dergelijke problemen op door het ontwikkelen van een agent programmeer taal die de ongewenste heuvels effent. Java , Obliq , Mole , Telescript en AgentTCL zijn hiervan goede voorbeelden. De Java virtuele machine stelt ons in staat platform onafhankelijke agenten te schrijven waarbij we met behulp van Java Serialisatie7 en RMI agenten van machine tot machine kunnen verplaatsen. Voorbeelden van dergelelijke agentsystemen zijn Mole , Aglets . We zien dus duidelijk dat de noodzaak om allerhande problemen binnen distributie op te lossen een nieuwe naam heeft gekregen. Namelijk dat van het agent onderzoek. De reden waarom wij in ons onderzoek geen dergelijke agent systeem gaan gebruiken wordt toegelicht in de sectie Borg.
Migratie
Migratie is de daad waarbij een uitvoerende agent wordt verplaatst naar een andere plaats. Na migratie moet de agent verder uitvoeren en verder doen wat hij aan het doen was voordat hij verhuisde. Wanneer een agent verhuist zijn er drie dingen die gedaan moeten worden. Ten eerste moeten we hem stilleggen en zijn volledige status encapsuleren, ten tweede moeten we de geëncapsuleerde data verplaatsen en als laatste moeten we de agent op zijn nieuwe bestemming weer in zijn oorspronkelijke toestand brengen en verder laten uitvoeren. Met de ruime aanwezigheid van TCP/IP netwerken kunnen we gerust stellen dat het verplaatsen van de data geen probleem is. Het moeilijke gedeelte is het stilleggen en encapsuleren van de data.
Wanneer iemand een agent wilt encapsuleren moet hij alles wat de agent toebehoort in acht nemen, zonder natuurlijk het gehele agentsysteem mee te transporteren. Conceptueel bestaat een agent uit:
-
Eén of meer draaiende processen
-
Een data gedeelte waarin de data gebruikt door de agent vervat zit
-
Een code onderdeel hetwelk beschrijft hoe een agent uitgevoerd moet worden
-
Eén of meer runtime stacks die de status van de processen registreert.
-
Een aantal connecties naar bronnen (resources)
-
Een verbinding naar het onderliggende agentensysteem.
Vandaag verplaatsen bijna alle mobiele multi agent systemen (met uitzondering van AgentTCL en General Magics’ Telescript ) alles behalve de runtime stack. Dit ligt aan het feit dat de interpreter voor de agenten programmeertaal een grondige verandering moet ondergaan om toe te laten de agent stack mee te migreren. Dit probleem heeft geleid tot 2 soorten migratie:
De eerste vorm, het looping model genaamd, verplaatst alles behalve de stack. Dit betekent dat wanneer men correct agenten wil encapsuleren de agenten in kwestie een lege stack moeten hebben. Als de agent wil migreren moet hij vrijwillig zijn stack ledigen en op de een of andere manier nadien weer de draad oppikken. Vandaar ook dat dit model het looping model genoemd wordt: het alterneert tussen starten en stoppen.
Dergelijke vorm van migratie niet goed is omdat
-
Zodoende het aspect migratie een enorme impact heeft op hoe de code geschreven is. Uiteindelijk wordt de migratie zelf veel te moeilijk te exploiteren zodat men uiteindelijk geen migratie meer zal gebruiken, tenzij het absoluut noodzakelijk is.
-
Het reflecteren over het gedrag van een agent wordt bemoeilijkt zoniet onmogelijk. Dit belet onmiddelijk het gebruik van manager agenten die de beslissing tot verplaatsen maken. En dit is hetgeen we in dit onderzoek willen doen.
Het tweede migratie model is telescripting. 8Op het ogenblik dat een agent systeem telescripting ondersteunt laat het systeem toe een agent op eender welk moment te verplaatsen, zonder telkens opnieuw de volledige berekening te moeten herstarten. Zoals te verwachten is wordt in dit model de agent runtime stack mee verplaatst en bijgevolg kunnen we op elk moment een agent encapsuleren.
Het agentsysteem dat we zullen gebruiken in dit onderzoek is er een dat zelf geschreven is en is één van de weinige die telescripting ondersteund. We geven hiervan een bespreking in de subsectie ‘Borg’.
Lokatie
Transparantie: Routering
Een aspect dat agentsystemen aanbelangt is lokatie. Als we ons willen bezighouden met het versnellen van de communicatie tussen agenten door ze naar elkaar toe te brengen, hebben we nood aan transparante communicatie. Dit is communicatie die geen rekening moet houden met de positie van de agenten. Zodra we ons geen zorgen meer moeten maken over het laten toekomen van berichten en ons geen zorgen moeten maken dat communicatie-sessies verbroken worden, zijn we in staat ons zuiver bezig te houden met het beheersprobleem, zijnde het kiezen van de positie.
Een basisprobleem dat optreedt in ongeveer alle agentsystemen die we bestudeerd hebben is het probleem van lokatietransparantie. Zodra een agent het adres bemachtigd heeft van een andere agent blijft deze hetzelfde adres gebruiken zolang hij ermee communiceert. Hiermee treden natuurlijk problemen op zodra de agent van plaatst verhuist. Zijn nieuw adres is door geen enkele van zijn gesprekspartners meer gekend en de communicatie zal dus ofwel verbroken worden ofwel enorm vertraagd door het opzoeken van de nieuwe naam.
Ter illustratie: als we het IP nummer van een server wijzigen zullen al de gerbuikers die het adres van de server hebben hem niet meer kunnen bereiken tenzij ze weer ergens het juiste IP nummer opvissen. Binnen internet wordt dit opgelost door name servers9 te gebruiken. Het blijkt nu dat dergelijke methode om lokatie transparantie te verzekeren niet goed genoeg is voor agent systemen omdat de mogelijke granulariteit van het verplaatsen leidt tot overbelasting van de centrale diensten.
Positie onafhankelijke communicatie is helaas een aspect dat niet eenvoudig verwezenlijkt wordt binnen bestaande agentsystemen.
-
Een eerste oplossing hiervoor is elke referent van een agent updates te sturen als de agent verplaatst . Het nadeel hiervan is natuurlijk dat een agent niet noodzakelijk al zijn referenten kent. Nog erger is het als een van de referenten het adres op disk plaatst of doorgeeft aan iemand anders. In dat geval is het bijna onmogelijk geworden al de referenten in te lichten.
-
Een voor de hand liggende oplossing is het installeren van statische proxies10 voor elke agent. Deze proxies zouden dan al de berichten bestemd voor de agent doorsturen naar de agent in kwestie. Het nadeel hiervan is natuurlijk de ellendige performantie. Hoe verder een groep agenten van hun creatiemachine verwijdert is, hoe trager de groep intern zal werken. Het is duidelijk dat dit voor ons onderzoek niet wenselijk is.
-
Een intelligent systeem is het opzetten van gestructureerde communicatiesessies , , . Hierbij hoort elke agent in een communicatiesessie. Als een agent van zo een sessie verplaatst zullen al de partners binnen de communicatiesessie ingelicht worden over de nieuwe positie. Dit systeem werkt perfect en leidt tot gestructureerde communicatievormen maar heeft het nadeel dat de grootte van communicatiesessies vrij beperkt is. We zijn in staat betere alternatieven aan te bieden.
Het systeem dat besproken is in mijn licentiaatsthesis:
-
Elke agent heeft een voor de gebruiker verstaanbare naam.
-
De gebruiker kan zelf namen toekennen aan zijn agenten.
-
Elke toegewezen naam is globaal uniek.
-
Als we een communicatie-sessie met een agent willen gebruiken we eenvoudig zijn naam. (zonder het opzetten van communicatie sessies)
-
Het verplaatsen van een agent heeft geen overtollige performantie impact op de communicatie tussen agenten.
Deze eigenschappen laten toe op eenvoudige wijze te communiceren zonder dat we ons zorgen moeten maken over de positie van een agent. Agenten kunnen na verplaatsen steeds hetzelfde adres blijven gebruiken zonder dat er speciaal ‘adres-update’ code moet geschreven worden, wat voor ons onderzoek uitermate noodzakelijk is. Dit systeem is hetgeen we zullen gebruiken en welk geïmplementeerd is in Borg.
Beheersing: Meta11 Componenten
Naast lokatie transparantie willen we natuurlijk ook in staat zijn te redeneren over de lokatie van agenten. We moeten ooit de beslissing kunnen nemen tot verplaatsen en we willen dit liefst doen op een niveau dat gescheiden is van de uitvoering van de agenten zelf. Het eerste idee dit op een centrale plaats te laten doen door een alom aanwezige service die exact het doen en laten van elk object kent (zie onderstaande figuur).
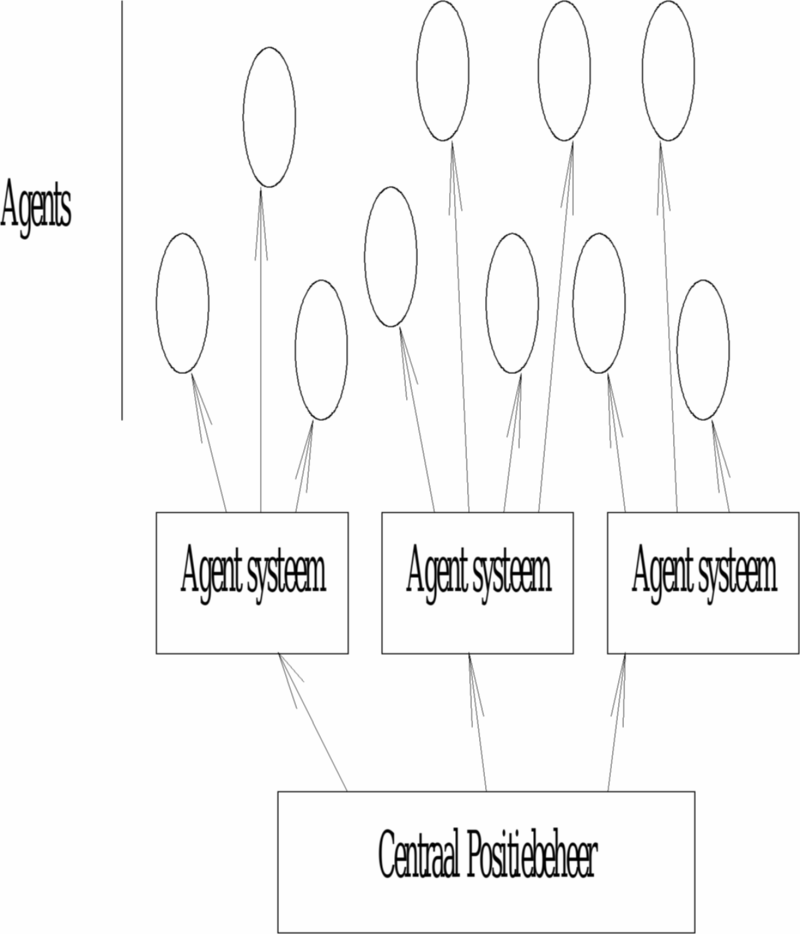
De beheerslaag waar we aan denken is bijgevolg zelf een gedistribueerd systeem dat redeneert over de positionering van zijn onderliggend gedistribueerd systeem. We kunnen dan zeker al aan twee mogelijkheden denken.
De gemakkelijkste methode is op elk agentsysteem een agent te draaien die de data uit zijn lokale router haalt en die hieruit opmaakt welke agenten het best verplaatst worden. De agentsysteem agenten kunnen dan onderling data uitwisselen om hun inschattingen kracht bij te zetten.
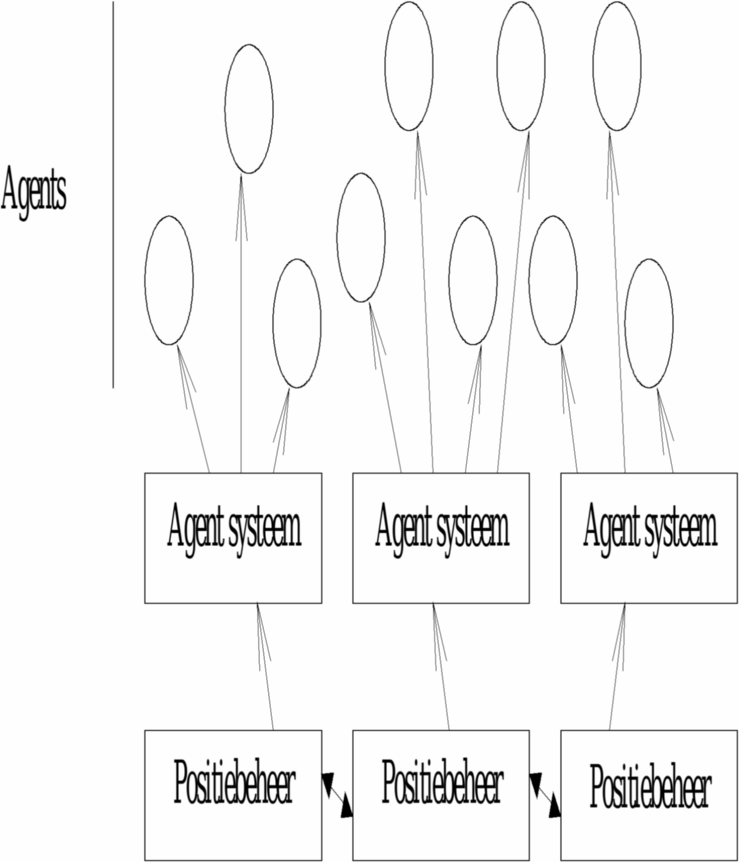
Het voordeel van dit systeem is dat het gemakkelijk implementeerbaar is zonder al te veel performantie overhead. Al de berichten die binnenkomen worden geleverd en enkel de statistieken zijn toegankelijk voor de monitor agent. Het redeneren over de positie gebeurt onafhankelijk van de uitvoering van de agenten. Het nadeel van dit systeem is dat we niet in staat zijn voor een bepaalde agent een eigen monitor agent te voorzien.
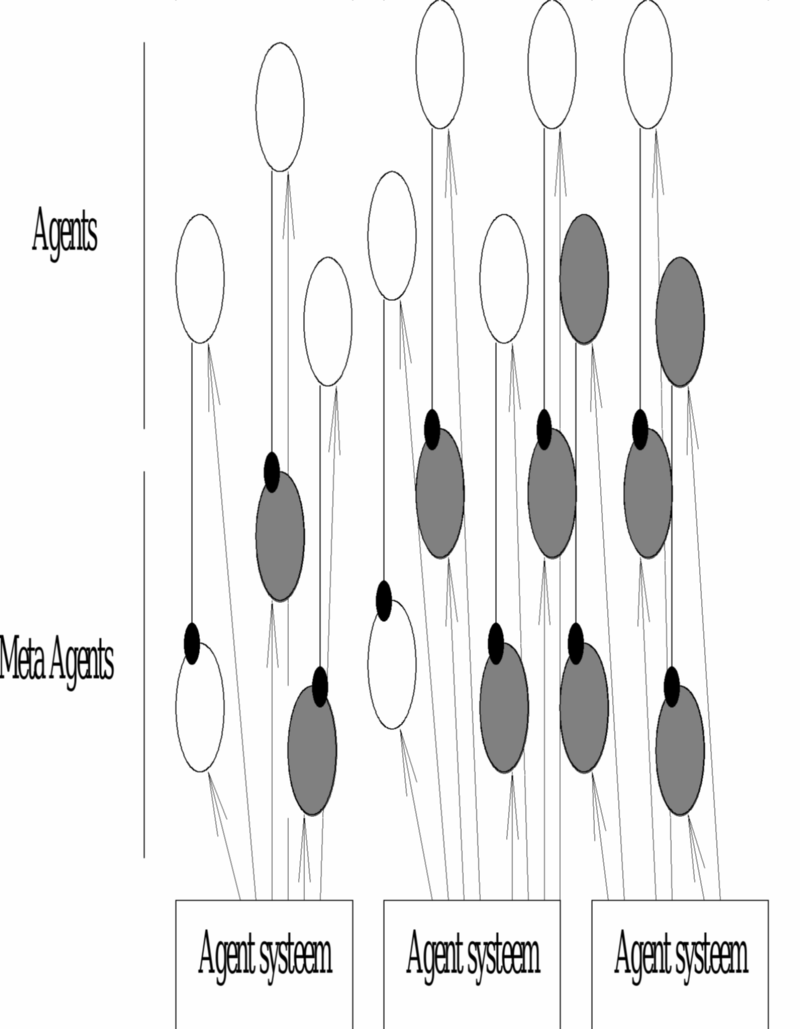
Een andere manier om aan een
gedistribueerde positie beheersing te doen is elke agent te mirrorren
door een positionerings agent. We denken dan aan meta agenten die al
de berichten bestemd voor specifieke agenten onderscheppen en
omleiden naar de eigenlijke. Ondertussen houden ze natuurlijk
statieken bij en ontwikkelen ze een model van de eigenlijke agent.
Het nadeel van dit systeem is zijn grandioze synchroniteit (iets wat
niet orthogonaal staat op de gescheiden
redenering) en zijn performantieoverhead zowel op plaats als op
tijdsniveau.
Als we trachten één van de twee laatste systemen te implementeren in bestaande agentsystemen merken we dat we eigenlijk geen van beide op vlotte wijze te implementeren is. Ofwel laat men niet toe statistieken van de router op te vragen ofwel laat met niet toe meta agenten te installeren diewaarnemen wat er zoal gebeurt. Het agent systeem dat we zullen gebruiken laat beide systemen toe en wordt besproken in de volgende sectie.
Borg
De aspecten van agent systemen die we hierboven besproken hebben, heb ik geïmplementeerd en op het ogenblik heb ik een bruikbaar mobiel multi agent systeem om verder te kunnen gaan met het onderzoek. Het systeem heet Borg en is geïmplementeerd in C.
Aangezien ongeveer alle agentsystemen vandaag de dag in Java geschreven zijn is het nuttig te verantwoorden en verklaren waarom het agentsysteem dat we zullen gebruiken geen Java is noch geschreven is in Java.
-
Het agentsysteem dat we nodig hebben moet telescripting ondersteunen omdat anders de agenten moeten meewerken met hun verplaatsing. In Java is het onmogelijk aan telescripting te doen zolang we niet in staat zijn de java runtime stack te encapsuleren. Op het ogenblik is dit nog steeds onmogelijk in Java.
-
Het agentsysteem moet toelaten op eenvoudige wijze statistieken te verzamelen over de uitgewisselde berichten. Als we dit willen doen door gebruik te maken van meta agenten gaat dit niet op voldoende flexiebele wijze.
-
Het bereiken van een Java gebaseerde agent vraagt een stub systeem12 om binnenkomende berichten te dispatchen naar het juiste object. In Java is het te moeilijk en vraagt het te veel overhead om stubs te genereren.
-
De reden waarom we dan geen agent programmeertaal schrijven in Java is dat het schrijven van een CPS13 gebaseerde interpreter (wat noodzakelijk is om aan telescripting te kunnen doen) in dergelijk objectgerichte taal bijna onmogelijk is
Bijgevolg hebben we een agentsysteem geïmplementeerd in C, wat aanleiding heeft gegeven tot een systeem dat telescripting, multithreading en communicatie voorziet. De hoogtepunten van Borg staan hieronder samengevat.
-
Borg is geschreven in C en draait onder Linux, Windows en Solaris. Dit garandeert dat we binnen een voldoende uitgebreid systeem kunnen experimenteren
-
Gebaseerd op een prototype14 gebaseerde taal, genaamd Pico
-
Garbage collection
-
Multithreading
-
Serializatie van berichten tussen agenten
-
Dynamisch getypeerd
-
Borg heeft een lokatie transparante router in zich
-
Communicatie tussen agenten is asynchroon
-
Reificatie van de agent stack laat toe te reflecteren over de staat van een agent zonder hem te moeten stilleggen
-
Telescripting
-
Management agenten kunnen eenvoudig geinstalleerd worden
-
Incorporatie van CSP in Borg in ontwikkelfase
Kortom, als we een agent willen schrijven die aangeroepen kan worden om een matrix te inverteren en het resultaat moet terugsturen kunnen we dit doen als volgt:
doInvertmatrix(matrix,answerto)::
{
result:InvertMatrix(matrix);
answerto.InvertResult(result)
}
In dit voorbeeld ziet u hoe we een functie definieren en hoe we een callback15 kunnen aanroepen. answerto is het callback object (een remote dictionary genaamd) waarnaar we op eenvoudige wijze de message InvertResult sturen. De parameters die meegegeven worden aan InvertResult zullen automatisch geserializeerd worden.
De agent die deze inverteer-matrix agent wil oproepen kan dit doen op onderstaande wijze:
Inverter:Remotedict(“tecra/matrixinverter”);
Matrix:[[1,2,3],[4,5,6],[7,8,9]];
InvertResult(answer)::display(answer);
Inverter.doInvertmatrix(Matrix,agentself());
In dit voorbeeld maakt de agent eerst een connectie aan met de matrix-inverteer-agent. Op de tweede lijn wordt een matrix gecreëerd die zal doorgestuurd worden naar de inverteer agent. De derde lijn zorgt ervoor dat de inverteer-agent een callback kan doen naar de huidige agent en de laatste regel roept de inverteer-agent aan met de matrix en zichzelf als parameters.
Als we dit vergelijken met andere agentsystemen en open gedistribueerde systemen (DCOM & CORBA ) merken we dat Borg uitermate bruikbaar is als uitgangsbasis voor de rest van ons onderzoek.
-
We kunnen op zeer compacte wijze communiceren met andere agenten
-
We moeten ons geen zorgen maken over het encapsuleren van de data
-
We hebben een lichtgewicht systeem waaraan we gemakkelijk wijzigingen kunnen doorvoeren indien het nodig blijkt
Uitvoering
De uitvoering van het bovenstaande deel van het onderzoek is grotendeels het voorbije jaar gebeurd. Er zijn nog een aantal validaties uit te voeren maar het geheel is demonstreerbaar en bruikbaar. Deze tijdswinst biedt ons de kans een betere case te introduceren dan diegene die we vorig jaar in gedachten hadden.
2. Specifieke Gevalstudie
Nu we een agentsysteem hebben, zijn er een aantal cases nodig om het agentsysteem te testen en metingen op uit te voeren. Deze cases moeten realistisch zijn wat wil zeggen dat we voornamelijk interactieve cases nodig hebben die in de huidige internetstructuur passen. We denken dan voornamelijk aan internet daemons, zoals sendmail, HTTP daemons, FTP daemons; clients zoals mail readers, web browsers en andere. Als case zullen we dus een aantal van deze daemons schrijven binnen het agentsysteem. 16
Om het onderzoek realistisch te houden is het duidelijk dat we dergelijke case op geleidelijke wijze moeten introduceren. We zullen beginnen met het implementeren van een actieve webserver. Dit omdat een webserver en zijn componenten vanuit vier invalshoeken benaderd kan worden.
-
We hebben de client die gewoon data wil opvragen en waarvoor HTML moet gegenereerd worden.
-
We hebben de auteur van de webpagina die een bepaalde component wil bijregelen (bijvoorbeeld een teller op nul zetten).
-
We hebben de systeembeheerder die bepaalde systeemgerichte taken, zoals het vernieuwen en wijzigen van componenten doet.
-
In tegenstelling tot andere systemen hebben we andere agenten die informatie over een bepaalde webpagina willen opvragen. (Hierbij denken we aan webcrawlers die beter direct de juiste zoekdata zouden opvragen in plaats van HTML te parsen)
Het is duidelijk dat deze realistische case geschikt is om lokatieoptimalisaties te testen, zeker als we binnen een voldoende groot in elkaar gestrengeld systeem werken.
-
We werken in een dynamisch wijzigend systeem met hardware die meer moet doen dan alleen maar een agentsysteem uitvoeren. Dit laat toe te testen hoe het systeem reageert op externe factoren.
-
We connecteren het gehele agentsysteem aan bestaande internet services zodat het systeem gebruikt kan worden in een gebruiker gedreven omgeving
De gevalstudie zelf hebben we opgesplitst in een aantal eenheden die hieronder besproken worden.
Systeem ontwikkelaar interactie
Om te beginnen hebben we een manier nodig om agenten op eenvoudige wijze te laten communiceren met hun ontwikkelaars of gebruikers. Hiertoe zullen we een niet mobiele native user interface agent ontwikkelen waarmee mobiele agenten op uniforme wijze met de gebruiker kunnen communiceren.
Een normale omgeving waarbinnen een systeem ontwikkelaar werkt is er een waarbinnen hij interactief met het systeem kan communiceren. Dit wil zeggen dat hij op eenvoudige wijze expressies moet kunnen intikken en laten evalueren. Het systeem moet op dezelfde eenvoudige wijze antwoorden kunnen terugsturen naar de ontwikkelaar. Bij mobiele agenten is hier toch een indirectielaag vereist.
We willen bijvoorbeeld niet dat wanneer de agent de instructie read uitvoert de inputline getoond wordt op de machine waar de agent is. We willen dat de read request gestuurd wordt naar de juiste machine en dat het antwoord automatisch teruggestuurd wordt naar de agent. Op dezelfde wijze moet het intikken van een expressie op de ontwikkelmachine gestuurd worden naar de agent die dan voor de evaluatie instaat.
In dit onderdeel zullen we dit probleem oplossen door een user interface agent te schrijven die verantwoordelijk is voor het doorsturen van expressies die gevalueerd moeten worden, het implementeren van een read en write en andere betrekkelijk laag bij de grondse primitieven. Zie figuur. Niettegenstaande laag bij de gronds zijn ze noodzakelijk om op eenvoudige wijze agenten te kunnen testen van zodra ze mobiel zijn.
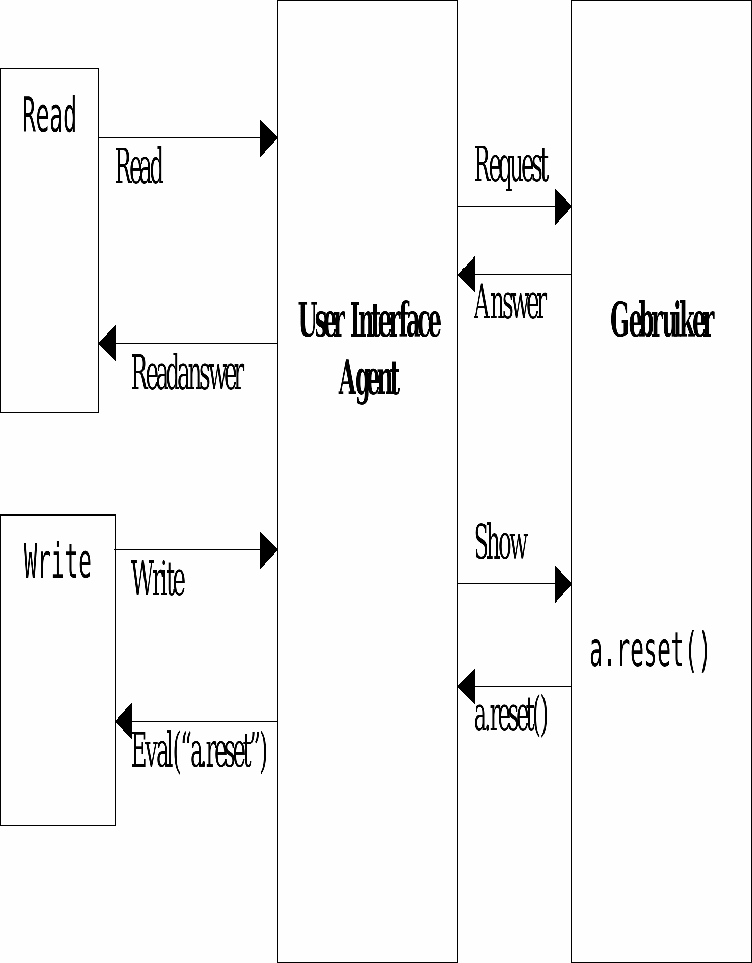
Auteur interactie
Een ander onderdeel is de interactie met de auteur of de met de eigenaar van de component/agent. De auteur van een webpagina zal zijn uitvoerende componenten willen wijzigen naarmate dat nodig blijkt. In deze eenheid implementeren we een bruikbare, doch beperkte, user interface tot de HTML componenten.
Deze user interface komt neer op het uitbreiden van de eerder genoemde ontwikkelaar interface. We zullen hiervoor waarschijnlijk een MFC17 achtige interface ontwikkelen die standaard zaken zoals dialogboxes, listboxes, inputlines en andere eenvoudige zaken voorziet.
Uiteindelijk zal een component toegang hebben tot twee user interfaces.De eerste is zijn native user interface om te interageren met zijn ontwikkelaar. De tweede user interface is om te interageren met de gebruiker van de component.
Client interactie
Het ontwikkelen van een web daemon agent die binnenkomende berichten initieel afhandelt door bestanden van een schijf te halen en gewoon te antwoorden. Deze is vrij noodzakelijk om binnenkomende aanzoeken om te zetten naar de eigenlijke HTML generator nadien. Vanzelfsprekend zullen deze agent(en) niet mobiel zijn. Een webserver heeft nu eenmaal een vast adres in de huidige technologie.
Na verloop van tijd zullen we de webdaemon laten interageren met actieve web componenten. We zullen agenten ontwikkelen die HTML code genereren als iemand (bijvoorbeeld de web daemon agent) er om vraagt. We zullen ons hier initieel beperken tot een HTML-file component, HTML-counter component en HTML zoek component. Gepaard gaande hiermee hebben we natuurlijk transport agenten nodig die zorgen dat de teruggestuurde data naar de juiste plaats gestuurd worden (eventueel kunnen deze transport agenten de web daemon omzeilen zodat er minder communicatie nodig is en dat de responsetijden van het geheel beter worden. Uiteindelijk zal dit van de situatie afhangen). Waarschijnlijk zullen we hiervoor eveneens een beperkte persistentielaag moeten inbouwen, doch hier zullen geen problemen optreden.
Agent interactie
We hebben in bovestaande gesproken over een zoek agent. Als we deze willen implementeren hebben we nood aan een of andere tabel die toelaat de juiste data op te zoeken en te lokaliseren. Hiervoor zullen we een agent ontwikkelen die de bestaande aanwezige agenten raadpleegt en een index creeert van de informatie die deze bevatten.
De data zelf zal verkregen worden door aan de agent een indexeer aanvraag te sturen waarop de agent dan de nodige keywords terugstuurt. Dit voorbeeld is relatief belangrijk omdat het een behoorlijke berichtenuitwisseling garandeert binnen de aaneenschakeling van de systemen.
3. Performantie
Eens het agentsysteem gevalideerd is en we een goede case hebben, hebben we nood aan een managementlaag waarbinnen we kunnen redeneren over de positie van de agenten. Dit houdt in dat we in staat moeten zijn een aantal bruikbare parameters te selecteren die kunnen leiden tot een globale performantieverbetering.
Meta Agenten
Hoewel het agentsysteem theoretisch bruikbaar is om meta agenten te implementeren hebben we dit nog niet getest en zullen we dit ongetwijfeld moeten doen.
We willen de mogelijkheid hebben asynchroon een agent te volgen (dus elk bericht dat de agent krijgt wordt ook gestuurd naar zijn meta agent), maar we willen ook in staat zijn als agent proxy op te treden: al de berichten die naar de agent gestuurd worden, worden tegengehouden, goedgekeurd, en eventueel doorgestuurd.
Het meta agent protocol moet de mogelijkheid bieden dynamisch meta agenten op te stapelen en af te bouwen, zodat we bijvoorbeeld een synchronisatie filter kunnen plaatsen onder de positie filter. Hoe we dit exact kunnen implementeren met bestaande middelen is een open probleem .
Hoewel het lijkt dat we hier te veel hooi op de vork nemen, denk ik dat dit zeker haalbaar is. We willen in dit onderdeel geen vernieuwend onderzoek doen in reflectie, we willen enkel de mogelijkheid bieden om een beheerslaag te implementeren.
Globale informatie inwinnen op basis van lokale waarnemingen
Het inwinnen van globale informatie, zijnde het gedrag van een agent binnen het gehele systeem, is een kerngedachte achter dit onderzoek. Bijgevolg zullen we er ook een groot deel van onze tijd aan besteden. De techniek die we aanwenden bestaat uit het vormen van een beeld van wat we mogen verwachten, bepalen hoe we dit beeld terugvinden in lokale waarnemingen en het opstellen van eisen aan het plannen van agenten.
Globale kwantitatieve analyse
Het eerste wat gedaan wordt is dus het bepalen van de relevante informatie. Het nadeel hierbij is dat sommige informatie moeilijk gekwantificeerd kan worden. Relevante informatie zoals de grootte van een agent of de gemiddelde grootte van berichten zijn meetbaar, maar vage begrippen als voorspelbare uitvoeringstijden op bepaalde machines zijn al een pak moeilijker te vatten.
Met behulp van een reeks globale metingen willen we de interactiepatronen binnen een groot software systeem bepalen en in een taxonomie brengen. We willen op voorhand een idee hebben van wat we kunnen verwachten van de gemiddelde agent. Er zijn bijvoorbeeld typische agenten die niets anders doen dan al hun berichten doorsturen. Het planningsgedrag van zo'n agent is vanzelfsprekend eenvoudiger dan dat van een deadlock resolution agent. De nuttige informatie voor de eerstgenoemde agent is dan ook veel kleiner dan voor de laatstgenoemde.
Lokale kwantitatieve modellering
Eens we een taxonomie hebben van agent gedragingen willen we deze efficiënt modelleren met behulp van de meta agenten. Binnen deze modelleringen dienen mogelijke acties opgenomen te worden die een agent kan ondernemen (hierbij denken we bijvoorbeeld aan het verplaatsen van een agent naar een andere host of het simuleren van het gedrag van een andere agent). We willen bijvoorbeeld dat de meta agent leert dat steeds na bericht A altijd 35 berichten buiten gestuurd worden. Het ontwerpen van deze dynamische modellen kan gaan van het ontwikkelen van een model-vertolkende agent tot het vertalen van een meta agent naar een nieuwe meta agent.
Samen met de mogelijkheid tot het uitvoeren van acties moet de meta agent een schatting hebben van de afstraffing of beloning die die actie teweeg brengt. Hiervoor is een grondige kennis nodig van de gebruikte routing en de link die we hebben naar ander agenten.
Globale performantie eisen
Bij het verplaatsen van agenten en het ondernemen van acties moeten we wel rekening houden met uitsluiting van agenten of oneerlijke berichtverdeling. We willen bijvoorbeeld niet stellen dat een systeem als performant werkend beschouwd wordt als er één communicatie-sessie volledig opgeschort blijft.
Zoals reeds duidelijk was zijn we niet in staat de `beste' oplossing te ontdekken, noch zijn we in staat binnen een statisch omgeving een goede oplossing aan te bieden. Om dit soort problemen aan te pakken kunnen we terugvallen op leeralgoritmen.
Het probleem bestaat hierin dat we een mogelijk leeralgoritme willen kwantificeeren op basis van zijn gedrag op lange termijn. Hiertoe moeten we in staat zijn te abstraheren over lokale onperformanties. Het is bijvoorbeeld toegelaten dat het agentsysteem gedurende 1 seconde agent X totaal uitsluit, maar hetzelfde is niet toegestaan als we daar 5 uur trachten van te maken. De moeilijkheid in het bepalen van goede kwaliteitseisen is dus het begrip tijd. Het is te verwachten dat we hier geen eenduidig antwoord zullen kunnen op geven. Het is dan ook in functie van de gebruiker(s) dat de gewenste eisen gehandhaafd dienen te worden.
Performantie Winnen
Aangezien dit de finalisatie van het onderzoekswerk inhoudt is dit punt nog vrij abstract. Desalniettemin zijn er een aantal veelbelovende denkpistes die we kunnen betreden om, uitgaande van een model, de juiste acties te kiezen. Een eerste mogelijkheid omvat het gebruik van genetische algoritmen en een tweede mogelijkheid omvat leertechnieken zoals reinforcement learning.
Genetisch programmeren
Genetische programma's zijn programma's die gecodeerd zijn met behulp van een reeks digitale genotypen (een string). Door een gesimuleerde natuurlijke evolutie worden ongeschikte programma's verwijderd en blijven enkel geschikte programma's over om een bepaalde taak uit te voeren.
Deze techniek kan ook toegepast worden op het verplaatsen van agenten. Door een agent gedurende een proefperiode binnen een agentsysteem te laten verplaatsen door een gen-gecodeerde agent kunnen we op basis van natuurlijke selectie de meest optimaliserende meta agent overhouden. Het nadeel van deze techniek is dat hij offline gebeurt en dat een agent dus een trainingssessie nodig heeft. Het voordeel daarentegen is dat hij een uniform stramien heeft en universeel toepasbaar is zodat hij ons een idee geeft van wat mogelijk is.
Leertechnieken
We kunnen agenten beschouwen als entiteiten binnen een zwaarteveld, die afhankelijk van hun gewicht bewegen naar plaatsen die hen aantrekken. Het zwaarteveld bepaald naar waar agenten bewegen. Agenten kunnen tegen dit zwaarteveld ingaan en hun omgeving exploreren. Telkens een agent een juiste actie onderneemt krijgt hij een beloning en telkens hij een foute actie onderneemt krijgt hij een afstraffing. Dit systeem van terugkoppeling en het toekennen van reinforcements (de afstraffingswaarden) wordt reinforcement learning genoemd.
Het probleem met dit systeem is dat het formalisme ontwikkeld is om binnen statisch of licht wijzigende omgevingen te werken. Het is duidelijk dat globale agentsystemen onderhevig zijn aan snelle fluctuaties. Het aanpassen van deze leertechnieken is een uidaging die op zich aangepakt dient te worden.
Statistische Technieken
Een techniek die eveneens aangewend kan worden is het gebruik van statistische waarnemingstechnieken en historiek analyses. Hiermee bedoelen we dat we op basis van een aantal parameters, die we reeds in het vorige deel van het onderzoek zo goed mogelijk hebben trachten te bepalen, waarnemen hoe een verplaatsing de omgeving verandert en zo de gewichten van de gegeven parameters aanpast. Als voorbeeld kunnen we de belasting op machines als behoorlijk belangrijk beschouwen. Als dergelijke agents ineens in een omgeving komen waar alle processoren reeds verschrikkelijk snel draaien maar waar men toch nog altijd serieuze belastingsverschillen aantreft is het vaak onnodig nog te verplaatsen omdat het verplaatsen zelf in verhouding tot het verder rekenen veel te traag gaat. In dergelijke omgevingen moet na verloop van tijd het gewicht van de machine belasting aangepast worden.
Een ander voorbeeld vinden we in de onverwachtte situaties. Als een agent bijvoorbeeld kijkt naar zijn historiek van verplaatsen en hij merkt dat telkens hij naar een bepaalde machine gaat de parameters die hij waarneemt ver onderschat of bovenschat zijn kan hij eventueel een passende terugrekenfactor toevoegen.
Uiteindelijk komt het erop neer dat geen van de parameters als vaste waarde beschouwd kan worden en we elke parameter moeten normaliseren naar de waarnemingen van de agent. Eventueel kunnen we dergelijke waarnemingen terugkoppelen naar het agent systeem zelf zodat het systeem uiteindelijk stabilseert.
Heuristieken
Een ander aspect dat we niet mogen verwaarlozen is het gezonde verstand. Sommige voor de hand liggende zaken zoals bijvoorbeeld het aaneenkoppelen van twee agenten, die onderling zodanig veel communiceren dat ze beter niet gescheiden worden, moet op een of andere wijze eenvoudig in het systeem geplaatst kunnen worden. Dit kan zowel op regels gebaseerd zijn als op subsymbolische benaderingen waarbij een bepaalde koppelcoefficient toegevoegd wordt.
Actie voorspelling
Om de positie optimalisering te doen kunnen we dus met een systeem van reinforcements werken of met een systeem van historiek controle. Een mogelijkheid die we hier eventueel nog aan moeten toevoegen is het anticiperen van de acties van de communicatiepartners van een agent. Het is bijvoorbeeld mogelijk dat we denken dat een communicatiepartner naar ons gaat migreren en dat we bijgevolg niet zelf de stap tot verplaatsen zullen zetten. Hierbij zullen we natuurlijk de data moeten randomizen zodat eventueel niet coopererende algoritmes niet te perfect op elkaar afgestemd zijn (en dus gaan rezoneren).
Uitvoering
De uitvoering gebeurt zoals hierboven beschreven op de eerder ontwikkelde actieve web server. We treffen voldoende literatuur aan die beschrijft hoe we plannen en modellen kunnen opstellen voor allerhande componenten. Deze literatuur zal ook geraadpleegd worden. Het onderzoeken van performantie-afstraffing door het uitvoeren van bepaalde acties zal worden uitgevoerd vanuit een globaal beheer. Om de sequentie van het onderzoek te schetsen zullen we eerst trachten een aantal heuristieken hard te coderen en zien in hoeverre we reeds goede heuristieken kunnen vinden. Door dit te doen spelen we een beetje met het systeem en kunnen we eventueel een aantal onverwachte zaken opmerken.
Nadien zullen we door gebruik te maken van statische technieken (zonder reinforcement learning te gebruiken) trachten aan positionering te doen die voldoende goed is. Hierbij moeten we opmerken dat we er hier reeds vanuit zullen gaan dat al de parameters die het agent systeem weergeeft, en dat al de parameters die we waarnemen absoluut correct zijn.
Eens we hierin geslaagd zijn zullen we een terugkoppeling plaatsen die eventueel fouten in de metingen bijstuurt. Hiervoor zullen we de historiek van de agent moeten raadplegen of met een systeem van reinforcement werken. Welk van de twee het voordeligste is zal afhangen van de waarnemingen die we doen. Het voordeel hier van een historiek is dat we bepaalde parameters kunnen filteren op basis van hun invloed. Dit is zo goed als onmogelijk als we met een systeem van reinforcements werken.
Op het einde van het onderzoek zullen we met de eerder opgedane kennis een geschikt genetisch programma trachten te schrijven dat geparameteriseerd is door een aantal genen. Dit programma zouden we laten muteren in de omgeving en zo zouden we uiteindelijk automatisch een positie optimaliserings programma bekomen.
Industriële relevantie
Op korte termijn kan het onderzoek direct in het ontwikkelingsproces van client/server toepassingen geplaatst worden. De ontwikkelfase van client/server toepassingen bestaat dan uit het ontwikkelen van een prototype binnen het agentsysteem. Na het testen en goedkeuren van dat prototype opereert de toepassing gedurende een bepaalde tijd binnen een industrieel kader zodat ze doorgelicht kan worden. Na deze empirische automatische doorlichting hebben de agenten zich geplaatst op een bepaalde machine en kunnen we er een `foto' van nemen. Het nemen van deze foto wil zeggen dat we de mobiliteit van de agenten bevriezen en ervoor zorgen dat ze niet meer kunnen verplaatsen. Naderhand kunnen we de agenten zelf doorvertalen naar een produktietaal zoals Smalltalk, Java, C++ en andere.
Een ander voorbeeld is systeem administratie. Een groot onderdeel van de taak van systeembeheerder is het plaatsen van resources op de juiste machines en er een toegang voor voorzien. Bestaande netwerken hebben het grote probleem dat enkel de systeembeheerder genoeg weet om problemen kunnen op te lossen. Meer bepaald, enkel de systeembeheerder weet waar welke service uitvoert. Systeembeheer zou veel vereenvoudigd worden door een standaard te voorzien om aan interprocescommunicatie te doen. Dit is iets wat agentsystemen zeker te bieden hebben.
Buiten het toepassingsgebied van de informatica is het optimaliseren van control flow door gebruik te maken van heuristieken en meta-heuristieken niet enkel toepasbaar op mobiele agents, het is evenzeer toepasbaar binnen andere communicatienetwerken, zoals bedrijfsstructuren.
Op lange termijn is dit onderzoek essententieel voor de ontwikkeling van een nieuw paradigma dat toelaat over actieve objecten te praten in plaats van passieve objecten. Objectgerichte talen komen voort uit het verlangen ‘entiteitjes’ te hebben die zelf iets kunnen, waarover men niet moet zeggen hoe ze iets moeten doen, maar waartegen men kan zeggen wat ze moeten doen. Impliciet zit in dit verlangen een soort ‘ik wacht op het antwoord terwijl jij rekent’. Er is met andere woorden een vaste control flow aanwezig die men in een distributieverband vaak wil veranderen. Binnen gedistribueerde systemen komt het maar al te vaak voor dan men het antwoord op een bepaalde vraag pas later wil ontvangen. Als we het idee van objectgerichtheid verder doortrekken komen we uit bij actieve objecten, ofwel agenten genaamd. En deze eenvoudige overgang is iets wat voor de industrie duidelijk belangrijk is: hoe beter men over een probleem een mentaal beeld heeft, en hoe beter men het kan uitdrukken, hoe sneller men betere code ontwikkeld.
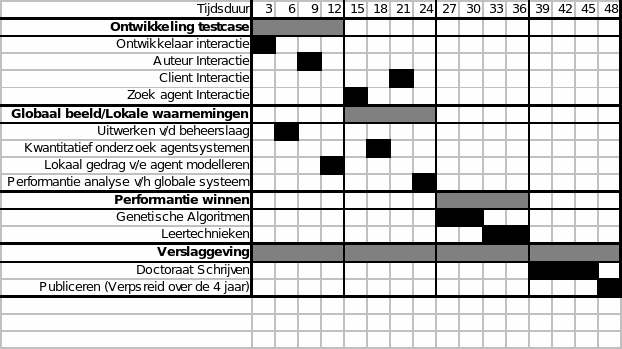
Planning
-
Ontwikkelen van de test case [12 maand]
-
Ontwikkelaar interactie [3 maand]
-
Auteur interactie [3 maand]
-
Client interactie [3 maand]
-
Zoek agent interactie [3 maand]
-
Globaal beeld met behulp van lokale waarnemingen [12 maand]
-
Uitwerken van de beheerslaag [3 maand]
-
Kwantitatief onderzoek agentsystemen [3 maand]
-
Lokaal gedrag van een agent modelleren [3 maand]
-
Performantie analyse van het globale systeem [3 maand]
-
Algoritmen en technieken om globale performantie te winnen. [12 maand]
-
Genetische algoritmen [6 maand]
-
Leertechnieken [6 maand]
-
Doctoraat schrijven + publiceren [12 maand]
-
Doctoraat schrijven [9 maand]
-
Publiceren naar de internationale onderzoekswereld en deelname aan conferenties [3 maand]
Activiteitenverslag voorafgaand doctoraatsonderzoek.
Zoals vermeld in de projectaanvraag, zal mijn doctoraat zich toespitsen op het onderzoeken van mogelijke optimalisaties binnen mobiele multi agent systemen. Tijdens de voorbije periode, waarvan ik mij slechts 5 maand met onderzoek heb kunnen bezig houden, heb ik een agentsysteem ontwikkeld waarbinnen dit onderzoek mogelijk gemaakt wordt. Het resultaat van dit werk heb ik beschreven in de projectbeschrijving. Hieronder vindt u het eigenlijke activiteitenverslag.
Oktober ‘97
Om een beter inzicht te krijgen in CORBA en huidige distributie trends heb ik na het indienen van mijn vorige aanvraag een Scheme evaluator geïmplementeerd in Java. Met behulp van deze evaluator heeft een kleine groep van mensen een HTTP-daemon geschreven en een databank online gebracht. De databank en de interface hebben reeds een volledig jaar werking bewezen.
Een tijdje later heb ik diezelfde Scheme evaluator gedistribueerd gemaakt door toe te laten de symbool tabellen op andere machines te plaatsen. Hiervoor heb ik eerst mijn toevlucht gezocht tot RMI, en nadien verder gewerkt met OrbixWeb, dewelke een Java implementatie van de CORBA specificatie is.
In het algemeen, kunnen we onze lessen trekken uit deze ervaring met distributie.
-
Als we ooit een agent systeem willen ontwikkelen zullen we terdege rekening moeten houden met de begrenzing van de informatie (welke informatie en welke referenties moet meegenomen worden als we objecten op een afgelegen plaats leggen).
-
Garbage collection vormt een centraal probleem. Hieromtrent zijn sinds kort reeds een aantal papers verschenen (onder meer op OOPSLA97 en ECOOP98). Dus op het ogenblik kunnen we dit probleem als opgelost beschouwen.
-
Inheritance vormt een enorm probleem als we objecten op andere machines leggen. Het is namelijk niet zo vanzelfsprekend ‘self’ naar een andere machine te laten refereren. In het algemeen denk ik dat concurrentie en inheritance vrij harde problemen geven.
November ‘97
Gedurende de maand november heb ik de router geïmplementeerd die in mijn licentiaats-thesis beschreven wordt om deze in de Java-Scheme te integreren. Het resultaat heeft licht geworpen op een aantal problemen aangaande de performantie van het gegeven systeem. Het duurde bijvoorbeeld 7 seconden om een bericht van de ene machine naar de andere te sturen via de router, een behoorlijk demotiverend resultaat. Zeker als we ervan uitgaan dat we veel kleine berichtjes moeten uitwisselen tussen objecten.
Inmiddels was me een ander probleem van de Sun Java implementatie opgevallen. Het is zo dat de Java implementatie niet staartrecursief is (een vrij vervelende eigenschap voor een interpreter die erop rekent dat de programmeertaal waarin hij geschreven is staartrecursief is), en dat de push operaties op de Java runtime stack trager en trager gaan naarmate de stack groeit.
Dit heeft me ertoe gebracht Java als programmeertaal (tijdelijk) te laten varen en de stap naar C te zetten, wat uiteindelijk een performantiewinst van een factor 4900 betekende. We hebben nu een router die erin slaagt 700 berichten per seconde uit te wissellen tussen 2 machines. Met deze router moeten we in staat zijn realistische experimenten te doen.
December ‘97
De maand december was voornamelijk een literatuurstudie. Ik heb een massa papers in verband met agent security gelezen , een aantal in verband met garbage collection en een aantal volledige agentsystemen bestudeerd.
De meest opvallende papers hiervan is die van Hudson. Deze paper is door een student geimplementeerd binnen de Scheme implementatie. Hieruit bleek dat de interpreter haast onmogelijk te integreren is met het voorgestelde celgeheugen zolang we base level objecten (objecten binnen de geinterpreteerde taal) willen voorstellen door objecten op metaniveau (de taal waarin de interpreter geschreven is).
Verder mogen we geen standaard parameterpassing meer gebruiken om objecten binnen de interpreter door te geven omdat deze objecten dan niet meer bereikbaar zijn voor de garbage collector. We kunnen hieruit gerust concluderen dat objectgerichte talen in essentie een fout paradigma zijn om interpreters in uit te drukken, dit omdat
-
De natuurlijke behoefte om elk base-level object in de meta taal voor te stellen leidt tot referentieproblemen voor de garbagecollector (het celgeheugen wordt gedupliceerd ofwel wordt de access ernaar enorm vertraagd)
-
Het schrijven van CPS code in een typische object oriented fashion bijna onmogelijk is.
Januari ‘98
Tijdens de maand januari heb ik gewerkt voor MediaGeniX, een bedrijf dat zich ontfermt over planningsprogrammatuur voor televisie omroepen. In januari bestond hun applicatie uit een databank waarmee een reeks fat clients verbonden waren. Deze fat client gebruikte een transactie management systeem van vrij ruwe aard waarbij de volledige databank opgehouden werd indien nodig. Zodra deze niet opgehouden kon worden wachtte men tot de houder vrij kwam. Het is vrij duidelijk dat dit vaak in theorie tot grove problemen leidt. In de praktijk bleken deze gelukkig relatief weinig voor te komen.
Aangezien men in de toekomst de fat clients ging converteren naar een commercieel agent systeem om aan produktieplanning te doen, heb ik een transaction management systeem uitgewerkt dat hen toelaat hun bestaande applicatie om te zetten naar een gedistribueerde omgeving, zodat alle data ‘consistent’ blijft maar dat men toch geen te ruw locking mechanisme heeft. Dit werk heeft me toegelaten in diepte de problemen van bestaande gedistribueerde applicaties te onderzoeken.
Februari ‘98
Logistieke taken.
Maart/April ‘98
Gedurende deze twee maanden heb ik gewerkt als voltijds systeem beheerder op de labos INFO (Informatica), PAR (parallelle), NW (netwerken) en LASSE (labo voor software engineering) aan de Vrije Universiteit Brussel.
Mei ‘98
Hoewel ik nog steeds aangesteld was als systeembeheerder is er in mei meer tijd vrijgekomen om aan mijn doctoraat te werken. Gedurende deze maand heb ik dan ook het agentsysteem geschreven door het converteren van een bestaande CPS based interpreter. (zie projectvoorstel). Dit houdt in het kort in dat we
-
De router geschreven in november hebben overgenomen en direct een aantal bugs verwijderd.
-
Geparameteriseerde serialisatie hebben geïmplementeerd.
-
Remote Object calling hebben geïmplementeerd.
-
Telescripting getest hebben en geconstateerd dat dit zonder al te zware problemen gegaan is.
Ik heb het resultaat ‘Borg’ gedoopt.
Juni ‘98
Het agentsysteem dat ik de vorige maand ontwikkeld had, heeft een student nu getest door een determinant te laten berekenen door 9 agentsystemen. Er was een centrale computer die de matrix splitste en de submatrices doorstuurde naar de 8 andere agent systemen. Deze testcase heeft een massa bugs naar boven gebracht die ons de rest van de maand gekost hebben.
Juli ‘98
Deze volledige maand is gespendeerd aan de mede organisatie van ECOOP9818. Dit hield het voorbereidende werk in, de conferentie zelf en het opruimen nadien. Deze episode is niet direct toepasbaar op mijn onderzoek, desalnietemin heb ik wel contacten gelegd met mobiele multi agent mensen.
Augustus ‘98
Vanuit mijn huidige ervaring met gedistibueerde systemen kan ik constateren dat er een duidelijk gebrek aan coordinatie is tussen al de componenten die binnen een gedistribueerde applicatie aanwezig zijn. Om dit probleem op te vangen hebben we een stage/thesis student opgezadeld met het incorporeren van CSP (het formalisme dat OCCAM voorafgegaan is) binnen het agentsysteem. In het achterhoofd zijn we aan het denken aan Chemical Abstract Machines en coordination .
Referenties
Veiligheid van agent systemen
-
Uwe G. Wilhelm, Cryptographically Protected Objects, Ecole PolyTechnouque Federale de Lausanne, CH-1015 Lausanne.
-
Bennet S. Yee, A sanctuary for Mobile Agents, UCSD, February 18, 1997
-
Leonard N. Foner, A Security Architecture for Multi-Agent Matchmaking, MIT Media Lab, Cambridge, MA02139.
-
Drew Dean, Edward W. Felten, Secure Mobile Code: Where do we go from here, Princeton University, 26 Maart 1997
-
Cedric Fournet, Security within a Calculus of Mobile Agents ? INRIA Rocquencourt, February 1997
-
Giovanni Vigna, Protecting Mobile Agents through Tracing, Dip Elettronica e Informazione, Politecnico di Milano.
-
Joan FeigenBaum, Peter Lee, Trust Management and Proof-Carrying Code in Secure Mobile-Code Application, Darpa Workshop on Foundations for Secure Mobile Code, 26 maart 1997.
-
Peter Lee, George Necula, Research on Proof-Carrying Code for Mobile-Code Security, 26 maart 1997.
-
Nevin Heintze, Jon G.Riecke, The Slam Calculus: Programming with Security and Integrity Bell Laboratories, Lucent Technologies.
-
Lars Rasmusson, Sverker Jansson, Simulated Social Control for Secure Internet Commerce, Swedish Institute of Computer Science, 1 april 1996
-
Tomas Sander, Security! Or “How to avoid to Brath Life in Frankensteins Monster”, International Computer Science Institute, Berkeley, 23 september 1997
-
Yaron Minsky, Robbert van Renesse, Fred B. Schneider, Scott D. Stoller, Cryptographic Support for Fault-Tolerant Distributed Computing, Departement of Computer Science, Cornell University, Ithaca, New York. 5 July 1996
-
Vipin Swarup, Trust Appraisal and Secure Routing of Mobile Agents, The MITRE Corporation, 27 February 1997.
-
Catherine Meadows, Detecting Attacks on Mobile Agents, Center for High Assurance Computing Systems, Naval Research Laboratory, Washington
-
Andrew D. Gordon, Nominal Calculi for Security and Mobility, University of Cambridge, Computer Laboratory
-
Jose Meseguer, Carolyn Talcott, Rewriting Logic and Secure Mobility, SRI International and Stanford University.
Besprekingen volledige systemen
-
Markus Strasser, Joachim Baumann, Fritz Hohl, Mole – A Java Based Mobile Agent System, IPVR (Institute for Parallel and Distributed Computer Systems), University of Stuttgart, 23 october 1996
-
Telescript: Jim White, Mobile Agents White Paper, General Magic.
-
Maarten van Steen, Philip Homburg, Andrew S. Tanenbaum, The architectural Design of Globe: A wide-area distributed system, Internal Report IR-422, Maart 1997
-
Eric Jul, Rajendra K. Raj, Norman C. Hutchinson, Niels Christian Juul, The Emerald System USER’S GUIDE, DistLab, Departement of Computer Science University of Copenhagen, Denmark, October 1993.
-
Robert S. Gray, Agent TCL: A flexible and secure mobile-agent system, Departement of Computer Science Darthmouth College
-
Obliq: Luca Cardelli, A Language with Distributed Scope, Digital Equipment Corporation, Systems Research Center.
-
Aglets: Danny B. Lange, Agent Transfer Protocol ATP/0.1Draft, IBM Tokyo Research Laboratory, 29 July 1996, www.trl.ibm.co.jp/aglets.
Papers zeer specifiek gericht op migratie van code
-
Fritz Hohl, Peter Klar, Joachim Baumann, Efficient Code Migration for Modular Mobile Agents, IPVR, University of Stuttgart, Germany
-
Gian Pietro Picco, Understanding Code Mobility, Politecnico di Torino, Italy, Tutorial at ECOOP98, 22 July 1998
Coordinatio, structureren van communicatie sessies
-
Paolo Ciancarine, Coordination models, languages and applications, University of Bologna, Italy, February 19-21, 1997, gepresenteerd aan de KUL.
-
Philip Homburg, Leendert van Doorn, Maarten van Steen, Andrew S. Tanenbaum, Wiebren de Jonge, An object Model for Flexible Distributed Systems, Vrije Universiteit Amsterdam, 29 Maart 1995
-
Philip Homburg, Maarten van Steen, Andrew S. Tanenbaum, Distributed Shared Objects as a Communication Paradigm, Vrije Universiteit Amsterdam
Agents & Distributed Objects in het algemeen
-
Philip Homburg, Maarten van Steen, Andrew S. Tanenbaum, Unifying Internet Services Using Distributed shared Objects, Internal report IR-409, October 11, 1996
-
Colin G. Harrison, David M. Chess, Aaron Kershenbaum, Mobile Agent: Are they a good idea ? IBM Research Division, T.J. Watson Research Center, Yorktown Heights, NY 10598.
-
David Chess, Banjamin Grosof, Colin Harrison, David Levine, Colin Parris, itinerant Agents for Mobile Computing, IBM Research Report, T.J. Watson Research Center, Yorktown Heights, New York.
-
Dag Johansen, Robbert van Renesse, Fred B. Schneider, An Introduction to the TACOMA Distributed System, University of Tromso, Cornell University June 1995.
-
G. Hartvigsen, D. Johansen, A Multi-Aagent Architecture for a Distributed Artificial Intelligence Apllication, Departement of Computer Science, University of Tromso
-
V. Farsi, Increased Scalability of the Stromcast Distributed Application, Computer Science Technical Report 94-17, Institute of mathematical and physical sciences, University of Tromso, September 1994.
-
P. Emerald Chung, Yennun Huang, Shalini Yajnik, Deron Liang, Joanne C. Shih, Chung-Yih Wang, Yi-Min Wang, DCOM and CORBA side by side, step by step and layer by layer, Bell Laboratories, Lucent Technologies, Institute of Information Science, Academic Sinica, AT&T Labs, Research.
-
Takahi Nishigaya, Design of Multi-Agent Programming Libraries for Java, Fujitsu Laboratories Ltd. Kawasaki, Japan.
Lokatie transparantie
-
Om P. Damani, P. Emerals Chung, Yennun Huang, Chandra Kintala, Yo-Min Wang, ONE-IP: Techniques for hosting a Service on a Cluster of Machines, Departement of Computer Science, University of Texas, Bell Laboratories, Lucent Technologies, At&T Labs, Research.
-
Woo Young Kim, Gul Agha, Efficient Support of Location Transparency in Concurrent Object Oriented Programming Languages Departement of Computer Scienec, University of Illinois
-
Justin A Boyan, Michael l. Littman, Packet Routing in Dynamically Changing Networks: A Reinforcement Learning Approach, School of Computer Science, Carnegie Mellon University, Cognitive Science Research Group, Bellcore
-
Maarten van Steen, Franz J. Hauck, Philip Homburg, Andrew S. Tanenbaum, Locating Objects in Wide Area Systems, Vrije Universiteit Amsterdam, University of Erlangen-Nurnberg.
Garbage Collection
-
Richard L. Hudson, Ron Morrison, J. Eliot B. Moss, David S. Munro, Training Distributed Garbage: The DMOS Collector. Departement of Computer Science, University of Massachusetts, School of Mathematical and Computational Sciences, University of St Andrews.
-
Nalini Venkatasubramanian, Gul Agha, Carolyn Talcott, Scalable Distributed Garbage Collection for Systems of Active Objects, DARPA.
Leren & Planning
-
Tuomas W. Sandholm, Robert H. Crites, Multiagent Reinforcement Learning in the Iterated Prisoner’s Dilemma University of Massachusetts at Amherst, Computer Science Departement.
-
Mario Tokoro, Computational Field Model: Toward a New Computing Model/Methodology for Open Distributed Environment, Departement of Computer Science, Keio University, 11 June, 1990
-
Hideaki Okamura, Yutaka Ishikawa, Mario Tokoro, Metalevel Decomposition in AL-1/D, Department of Computer Science, Keio University, Real World Computing Partnerschip, Tsukuba Research Center
-
Hideaki Okamura, Yutaka Ishikawa, Mario Tokoro, Al-1/D: A distributed Programming System with Multi-Model Reflectioon Framework, Department of Computer Science, Keio University, Real World Computing Partnerschip, Tsukuba Research Center
-
Hedaki Okamura, Yutaka Ishikawa, Object Location Control using Meta-Level Programming, Departement of Computer Science, Keio University, Tsukuba Research Center, Real World Computing Partnership.
-
Gilad Zlotkin, Jeffrey S. Rosenschein, Negotiation and Task Sharing among Autonomous Agents in Cooperative Domains, Computer Science Departement, Hebrew University, Givat Ram, Jerusalem, Israel.
-
Satinder Singh, Peter Norvig, David Cohn, Agents and Reinforcement Learning, Making software agents do the right thing, Adaptive Systems Group, Harlequin Inc, 5 July, verschenen in Dr. Dobbs, Maart 1997.
-
Andrea Schaerf, Yoav Shoham, Moshe Tennenholtz, Adaptive Load Balancing: A study in Multi-Agent Learning, Dipartimento di Informatica e Sistemistica, Universita di Roma, Robotics Laboratory, Computer Scienec Departement, Stanford University, Faculty of Industrial Engineering and Management, Technion, Haifa, Israel.
-
Anthony Chavez, Alexandros Moukas, Pattie Maes, Challenger: A Multi-agent System for Distributed Resource Allocation, Autonomous Agents Group, MIT Media Lab, Cambridge.
Algemeen
-
Gerald Jay Sussman, Guy Lewis Steele Jr, Scheme, An interpreter for extended Lambda Calculus, Massachusetts Institute of Technology, Artificial Intelligence Laboratory. December 1975.
-
Java Remote Method Invocation, Sun Microsystems, chatsubo.javasoft.com/current/
-
JavaObject Serialization Specification, Sun Microsystems, chatsubo.javasoft.com/current/, 11 november 1996
Intelligente & User Interface agenten
-
Bradley J. Rhodes, Thad Starner, Remembrance Agent, A continuously running automated information retrieval system, MIT Media Lab, Cambridge
-
Pattie Maes, Agents that Reduce Work and Information Overload, MIT Media Lab, Cambridge
-
Robert H. Guttman, Pattie Maes, Agent-Mediated Integrative Negotiation for Retail Electronic Commerce, MIT Media Lab, Cambridge
-
Pattie Maes, Artificial Life meets Entertainment: Lifelike Autonomous Agents, MIT Media Lab, Cambridge
-
Gene Ball, Dan Ling, David Kurlander, John Miller, David Pugh, Tim Skelly, Andy Stanskosky, David Thiel, Maarten Van Dantzich, Trace Wax, Lifelike Computer Characters, the Persona Proejct at Microsoft Research, Microsoft Research.
Footnotes
1 We gebruiken bewust de term load balancing niet omdat we tijdens het plannen rekening moeten houden met de communicatie tussen verschillende agenten.
2 We gebruiken een zelf ontwikkeld systeem omdat dit reeds afgewerkt is en omdat Java een aantal sterke beperkingen heeft die we in het projectvoorstel zullen bespreken.
3 Remote Procedure Call: een systeem dat binnen unix gebruikt wordt om functies op te roepen over een netwerk.
4 Remote Method Invocation: Een systeem zoals RPC maar waarbij men objecten op een server aanroept in plaats van functies.
5 Als men denkt aan open gedistribueerde systemen vervangt men best het woord agent door component of service.
6 Local Area Network: een netwerk dat beheert wordt door hetzelfde instituut.
7 Serialisatie is een techniek die toelaat een graph van objecten in een lineair geheugen te dumpen. Dit kan gebruikt worden om de objecten naar een andere machine te sturen of om de objecten persistent te maken.
8 De naam telescripting is gebasseerd op het eerste telescript gebasseerde agent systeem dat ontwikkeld is, genaamd telescript.
9 Een name server is een service die op een centrale plaats draait en die weergeeft welke naam overeenkomt met welk adres. Bijvoorbeeld, dat igwe8.vub.ac.be overeenkomt met 134.184.49.8.
10 Een proxy is een object, een agent, een service die binnenkomende berichten cached en eventueel doorstuurd naar de betreffende instantie. Dit omwille van de performantie.
11 Een meta object of meta component is een component die reflecteert over het gedrag van een andere component. Het base object is dan het object waarover geredeneert wordt. Meta objecten kunnen in dezelfde taal geschreven zijn als de base objecten, maar dit is zeker niet noodzakelijk.
12 Een stub is een wrapper object dat binnenkomend berichten omleidt naar de juiste instantie en de resultaten weer doorstuurd naar de oorspronkelijke vrager. Deze term werd vooral gebruikt in applicaties waar men van het ene moment op het andere een deel van de functionaliteit naar een andere machine verplaatste. Het stopsel of stub was dan nodig om de ontbrekende functionaliteit weer te voorzien door de berichten door te sturen naar het andere deel van de applicatie.
13 CPS: Continuation Passing Style: Een CPS gebaseerde interpreter is een interpreter waarin elke functie die gebruikt wordt door de interpreter ten behoeve van de geinterpreteerde taal (de native functies dus) op een stack gezet wordt. Al de parameters die meegegeven worden aan deze functie worden eveneens op de stack gezet zodat de functie zelf parameterloos is. Deze techniek laat toe zowel vanuit de meta taal (de interpreter), als vanuit de base taal (de geinterpreteerde taal) de runtime stack te overschouwen. Meer informatie hieromtrent kan gevonden worden in .
14 Een prototype gebaseerde taal is een taal waarbinnen objecten niet gemaakt worden door constructors maar wel gekloond (gekopieerd) worden en dan aangepast.
15 Een callback object is een object waarvan de referentie doorgegeven wordt naar een ander object, zodat dat ander object op een later tijdstip een antwoord kan terugsturen naar de oorspronkelijk aanroeper. Dit is een voor de hand liggende techniek om asynchrone communicatie te voorzien in een gedistribueerde omgeving. CORBA basseert zich sterk op deze manier om antwoorden terug sturen.
16 De idee van een aantal internet services gelijk te stellen door ze dezelfde interface te geven is niet nieuw. Getuige daarvan de referentie .
17 MFC: Mifrosoft Foundation Classes, een library die het ontwikkelen van windows gebasseerd toepassingen veel eenvoudiger maakt.
18 European
Conference on Object Oriented Programming
| http://werner.yellowcouch.org/ werner@yellowcouch.org |  |