| Home | Papers | Reports | Projects | Code Fragments | Dissertations | Presentations | Posters | Proposals | Lectures given | Course notes |
|
|
Active Objects: an Efficient Space/Time Separation of Concurrent Tasks through Active Message QueuesWerner Van Belle1 - werner@yellowcouch.org, werner.van.belle@gmail.com Abstract : This article focuses on Active Message Queues, an abstraction which I created between 1998 and 2006. The abstraction seperates various tasks through means of a message queue whereby the queue will activate the underlying task whenever a new message comes in. Using this abstraction it becomes possible to have time speration between threads (they will not influence each others execution/not wait for each other), space separation (different tasks will not write into each others data space), scheduling independence (we can run multiple tasks with one, two or more processes), syntactical separation (each task is declared in its own source file) and finally lockfree programming, which thus also leads to a noticable lack of deadlock and race-conditions
Keywords:
active objects, actors, active message queues, concurrency management, pattern |
History
Modern computer systems often deal with multiple tasks. For instance, an embedded systems needs to control the temperature of the fridge while downloading the latest service pack (just to give an idea how good the initial software was). A DJ Program needs to play songs, while creating small sound fragments, while analyzing music, while reading entries from a database. A Fractal Calculator needs to make tea while printing a poem and calculating a Julia set.Many people choose threads as the preferred abstraction to deal with the above scenarios mainly because it seems to be fashionable to write multi-threaded programs. However, the 'thread' abstraction has shown to be a rather bad thing. Once one goes into this labyrinth, one quickly starts asking the question: 'Exactly how many threads are going through this particular line of code'. 'Is my thread being started, or is it stopping, or should I just wait a bit more until it finally did what I wanted it to do ?'. Or even worse: race-conditions: 'Hey this thread is not supposed to write to my variable while I'm accessing it'. To deal with these problems, one tends to introduce locks and then one suddenly finds that the program deadlocks, or starts to run slower than expected (priority inversion and/or fairness issues). After 3 weeks looking at a multi-threaded program, one is ready to be shipped off to a mental institution and ponder the finer points of competing health-care management systems and the effect a race condition might have on the number of times the prescribed lobotomy will be performed. Or in more academic terms: one has spent more time on concurrency management than on dealing with the essence of the system under design.
In 1998, I read about Infospheres [1, 2, 3], which was an abstraction that to a large extend solved these problems by using mailboxes. Around 2000 I integrated and refined this idea into Borg [4, 5] (a mobile multi-agent system supporting strong mobility) and around this time I also started to use it in the SEESCOA project [6, 7], (a project aimed at component based development for embedded systems). In 2006, I made a version for C++ [8], which was consequently used in BpmDj [9]. The main reason for introducing it in BpmDj was because by that time the process and thread management had become a festering pool of locks and concurrency problems. This was of course not due to the Russians, and certainly not our own fault (and if it were we wouldn't admit it): instead, we could point a finger (or even an entire fist) at Trolltech [10] and their hugely inadequate view on concurrency.
Although I don't know why most people prefer threads, I could probably guess it is thanks to overzealous engineers and idiots like Doug Lea [11], who effectively pushed concurrency management strategies 10 years back after publishing books such as 'Concurrent Programming in Java' [11]. Thereby he convinced the rest of the world that 'threads', 'locks', 'notifies' and 'synchronized' constructs are the best new thing. All in all it would have been easier to continue building on things like CSP [12] and Actors [13, 14], but around 2000 (and this continues up to now as far as I see it) nobody wanted anything but threads. This impasse prompted me to explain this sad state of affairs and thereby present an abstraction that has been tested and made development of concurrent programs much easier.
This paper describes what active message queues are, how they can be used, how they are implemented and which problems one need to tackle to implement a runtime for this apparent 'simple' abstraction.
What is an Active Message Queue
An active message queue or active object is a task that is activated whenever a message is delivered for that task. The term 'task' is used in a functional sense: a task could be the analysis of a piece of music, or the downloading of an upgrade to an embedded system, or anything which has a clear functionality that can run largely on its own terms. So a 'task' is not the same as a process or a thread.Each task receives messages through a queue. Incoming message are handled one by one. The queue itself will sequentialize concurrently incoming requests. Anybody can send a message to an active object. However, messages are always send asynchronously, thereby disconnecting the time lines of the sender thread/process and the receiving task.
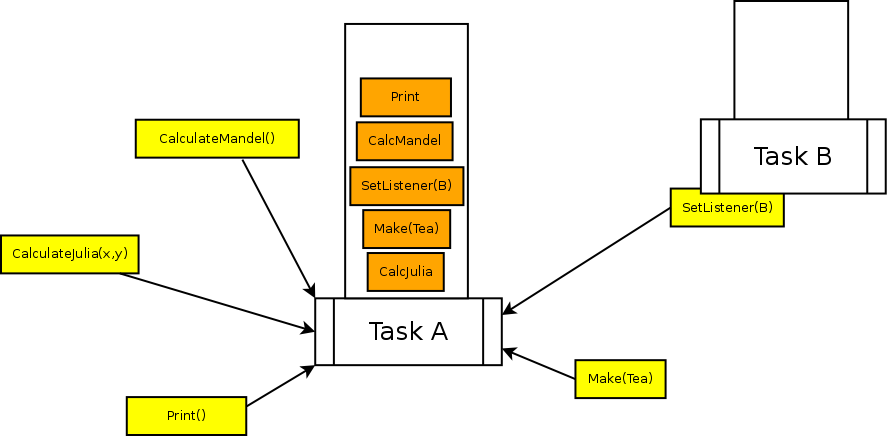
Class View
The above abstraction requires the user to declare each 'active' object in its own file. For instance, Task A and Task B would both be declared as an Active Object in which we specify which messages the task can accept. This will then lead to the follow class hierarchy: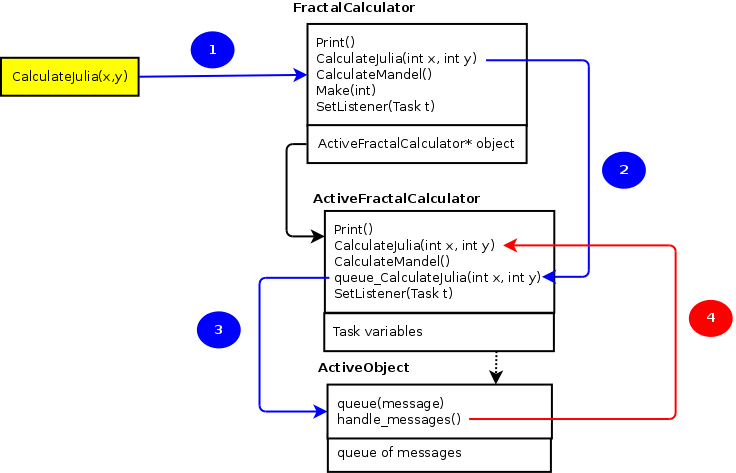
Assuming that task A was declared to be a 'FractalCalculator' task, then we would have a 'FractalCalculator' class declaration that would contain 'Print()', 'CalculateJulia', 'CalculateMandel', etc. This class, called the metaclass (and if instantiated the metaobject), has only one field: a pointer to the class that will performs the logic. This secondary class is called the taskobject, and is preceded with the identifier 'Active'. So the 'ActiveFractalCalculator' is the taskobject. The taskobject inherits from the 'ActiveObject' runtime, which takes care of notifying the scheduler and manages the queue. From these three classes, the 'ActiveObject' class is part of the runtime and the 'FractalCalculator' class will be generated by the precompiler. The declaration of the ActiveFractalCalculator is also generated automatically. Only the message methods declared in the taskobject ('ActiveFractalCalculator::calculateJulia' for instance) must be implemented by the programmer.
The user of the FractalCalculator will only see the meta-object (that is FractalCalculator instead of ActiveFractalCalculator). So in general, he will be dealing with metaobjects, not with taskobjects. The metaobject can be passed around as any other object and can even be passed as argument into another task.
To understand why this abstraction is so nice, it is helpful to have a look at the sending of a message to a task: what happens if a thread sends the 'CalculateJulia' message to the FractalCalculator ? 1) the metaobject receives 'calculateJulia(...)', it will 2) call the ActiveFractalCalculator with 'queue_calculateJulia(...)', which will in turn wrap all arguments into a message and 3) queue it into the 'ActiveObject'. This one will inform the scheduler of a requested action and 4) at a later stage the scheduler will contact the taskobject with a requested activation which will in turn call 'CalculateJulia' onto the 'ActiveFractalCalculator'. The nice thing is that the blue sequence and the red sequence are disconnected and this allows for quite a lot of flexibility, without giving up performance.
Code View
Active Objects are generated from an active object declaration. The precompiler will compile such declaration into a C++ metaclass declaration & implementation and a C++ taskobject declaration.To demonstrate tasks declaration, we illustrate how this works on a 'DemoSender' and a 'DemoReceiver'. The DemoSender accepts a message 'startSending' and will send 'printNumber' messages to the appropriate receiver. The declared variable 'tosend' will become part of the taskobject data space and is called a task variable. The receiver in this case is a 'DemoReceiver' that offers the message 'printNumber'.
active DemoSender
{
int tosend = 20;
message startSending(DemoReceiver* recv, int nr);
};
active DemoReceiver
{
message printNumber(int nr);
};
The implementation of both 'ActiveDemoSender::startSending(...)' and
'ActiveDemoReceiver::printNumber(...)' must be implemented by the
programmer. It could for instance be the following:
elementResult ActiveDemoSender::startSending(DemoReceiver* recv, int a)
{
tosend = a;
for(int i = 0 ; i < tosend ; i++)
recv->printNumber(i);
return Done;
}
elementResult ActiveDemoReceiver::printNumber(int nr)
{
printf("%d ",nr);
return Done;
}
The 'startSending' method is declared as if it is an ordinary method
(which it also is). We do however know that when an instruction
pointer runs through this method that it is the only
instruction pointer running through this code. Actually, we know that
if a thread runs through any method in DemoSender, that no other
thread is accessing any other method in this class. In other words:
all messages are exclusive entry points.
The first statement in the startSending method assigns the 'a' argument to the previously declared task variable 'tosend'. After that we directly send so many messages to the receiver 'recv'. The message sends are simply written as function calls and will all directly return. After this is done the startSending method finishes by telling its caller that it finished dealing with the messages. Another possibility could be to ask the caller to rerun this message at a later timestep.
The printNumber method in the ActiveDemoReceiver is equally simple. It will just print the number and declare the message 'Done'.
To instantiate our little program and get it running we can write the following:
DemoSender sender;
DemoReceiver recv;
int main(int, char* [])
{
sender.startSending(&recv,100);
sleep(1000);
}
The global variables 'sender' and 'recv' will directly instantiate an
underlying task object. In the main routine we can send a message to
the sender and pass as address the receiver task. Then we wait
sufficiently long to see the various tasks interact.
The C++ Implementation
The active object runtime is a class that deals with queuing incoming messages, handling messages, activating and deactivating threads if necessary. Below we discuss a number of aspects of this runtime.Messages
Messages are automatically generated by the precompiler. Each method declaration has an associated message class that will wrap all the arguments in a structure and pass it along using a smart pointer [15, 16, 17]. Doing so makes it possible to have automatic reference counting and disposal of incoming messages when they have been handled.
class ActiveDemoSender_msg_startSending: public ActiveDemoSender_msg_
{
DemoReceiver* recv;
int nr;
public:
ActiveDemoSender_msg_startSending(DemoReceiver* recv, int nr) : recv(recv), nr(nr)
{
};
virtual string declaration()
{
return "DemoSender::startSending(DemoReceiver* recv, int nr)";
}
virtual elementResult run(ActiveDemoSender * ao)
{
elementResult res = ao->startSending(recv, nr);
return res;
};
};
As can be seen, the constructor accepts the two arguments that have been declared in the active object declaration (which was 'message startSending(DemoReceiver* recv, int nr)'). The constructor copies the incoming messages into its own structure. Each message class also provides a 'run' method which provides a form of double dispatching, to deliver the message to the specified taskobject by directly calling the appropriate method: in this case startSending(...).
For each task, all the message that can be delivered to it, stem from a messaging class specifically suited for that task.
class ActiveDemoSender_msg_: public ReferenceCount
{
public:
/**
* Called by ActiveObject to handle this queued message.
* %arg caller is the ActiveDemoSender itself.
*/
virtual elementResult run(ActiveDemoSender * caller)
{
assert(0);
}
/**
* Returns the name of this message. Since this is the message baseclass
* it has no identity and will return 'Unknown Message'
*/
virtual string declaration()
{
return "Unknown message";
}
};
The above class is the basic message class (for messages to the DemoSender task), of which all particular message inherit. The 'ActiveDemoSender_msg_' has the declaration of the virtual 'run' method which is invoked by ActiveObject whenever it wants to handle the message. The message class is also an instance of 'ReferenceCount', which is necessary to use within smart pointers[15, 16, 17].The metaclass
The metaclass, which is generated for each declared task, will transform each incoming call (method) to a method that will queue a message object into the actual task. Each metaobject has one instance of the taskobject. To guarantee that every interaction towards the taskobject goes through the metaobject, the 'object' is a private field.
class DemoSender
{
private:
ActiveDemoSender object;
public:
DemoSender(string name="DemoSender"): object(this, name) {};
void startSending(DemoReceiver* recv, int nr);
};
The constructor of the metaobject directly initializes the main
object. Because object construction and delayed calls interfere
somewhat we prohibit the actual implementation (and especially use) of
specialized task constructors. Instead, simply the name is passed to
the object. If you need to initialize the task, you should add an 'Init'
message to the active object and sending such 'Init' message to the
instantiated task. After all when you make the task, you are the only
one having a reference to it at that moment, so your message will be
delivered first.For instance: Writing DemoSender '*a = new DemoSender()' will instantiate one new DemoSender task. Writing 'DemoSender a' will also instantiate one such a task. If we want specific initialization of this task we can directly write 'a->Init(...), or a.Init()'.
The TaskObject
The taskobject declaration is also automatically generated. It looks as follows:
class ActiveDemoSender: public ActiveObject<Smart< ActiveDemoSender_msg_ > >
{
DemoSender * self;
virtual elementResult handle(Smart< ActiveDemoSender_msg_> cmd);
volatile int tosend;
DemoReceiver* recv;
protected:
ActiveDemoSender(DemoSender* s, string name):
ActiveObject<Smart< ActiveDemoSender_msg_ > >(name), self(s)
{
tosend = 20;
};
public: elementResult startSending(DemoReceiver* recv, int nr);
protected: void queue_startSending(DemoReceiver* recv, int nr);
};
A number of things are noteworthyQueues
Each active object has 2 distinct queues.The separation of these two queues was necessary because we did not want to allow the receiving of many messages delay the handling of messages. Hence, the two queues had to be lockable separately. Although the system, once being used, does not require the use of locks, implementing the runtime did require some locking. To make the locking window as small as possible, we use two queues. The incoming queue accepts incoming messages and can only be altered when the active object is synchronized. The handling queue can be modified only by the active object and will contain the transferred messages from the incoming queue when handling messages.
Sending Messages
The sending of a message goes through multiple stages. First the metaobject is called with for instance 'startSending(...)'. The metaobject has an implementation as:
void DemoSender::startSending(DemoReceiver* recv, int nr);
{
object.queue_startSending(recv, nr);
};
The taskobject has for 'queue_startSending(...)' the following implementation:
void ActiveDemoSender::queue_startSending(DemoReceiver* recv, int nr)
{
push(Smart<ActiveDemoSender_msg_startSending>(
new ActiveDemoSender_msg_startSending(recv, nr)));
};
which summarizes what we said before: a) we use smart pointers
together with a reference counting in each message to decide when to
destroy a message. The message class itself is generated and inherits
from 'ActiveDemoSender_msg_'. In this case, the object we generate is
of type 'ActiveDemoSender_msg_startSending' and as explained before,
the constructor accepts exactly the same arguments as the
'startSending' method itself.
The only thing not yet explained is the 'push()' method. That one comes from the ActiveObject itself and is declared as follows:
void ActiveObject::push(message d)
{
Synchronized(this);
incoming.push_back(d);
activate();
}
The 'push' method pushes a message into the incoming queue. It does
this by locking the active object (which means that only the incoming
queue is locked. From a semantics point of view we associated the
active object lock with the incoming queue and nothing else). The push
requests an 'activation' in all cases since there clearly is something
to be done now. The activate method itself will check whether it is
truly necessary or not.Receiving Messages
At a certain point in time the active object will become active and start dealing with messages. This goes through a number of stages. However, first we focus on the handling itself:
virtual bool handle()
{
if (handling.empty()) return false;
message f = handling.front();
elementResult hr = handle(f);
switch(hr)
{
case RevisitLater:
handling.push_back(f);
case Done:
handling.pop_front();
case Revisit:
break;
case Interrupt:
return false;
case RevisitAfterIncoming:
push(f);
handling.pop_front();
break;
}
return !handling.empty();
}
virtual ActiveDemoSender::elementResult handle(Smart< ActiveDemoSender_msg_> cmd)
{
if (cmd) return cmd->run(this);
else return Done;
};
The 'handle()' method (without arguments) is called in its own (virtual) thread when it should handle an incoming message. The messages to be handled come from the
'handling' queue (a protected field in the active object). That queue can be accessed and
manipulated as necessary. What cannot be accessed here is the
'incoming' queue. The 'handle()' method returns true when it still could do some
more work or false when it has nothing left to do (when the handling queue is empty for
instance, or no useful message left to handle at the moment). The
standard implementation takes the front of the handling
queue and presents it to the more specific handle(T) member that was
generated by the precompiler. Based on the return of that function a
decision is made on what to do with the message.Activation
The part of the runtime that was remarkably hard to write was the activation part itself. We had a number of problems to deal with the activation sequence of a thread. Normally the scheduler associated with the task should be asked to start a thread, whenever the first message or a new message came in. The distinction is as follows: The first message is marked as a message that is pushed into an empty queue, while a new message is one where the task already looked at all messages and could not continue dealing with the messages. If then a new message comes in this is called a new message. We briefly summarizes the problems associated with thread activation:Double Activation 1
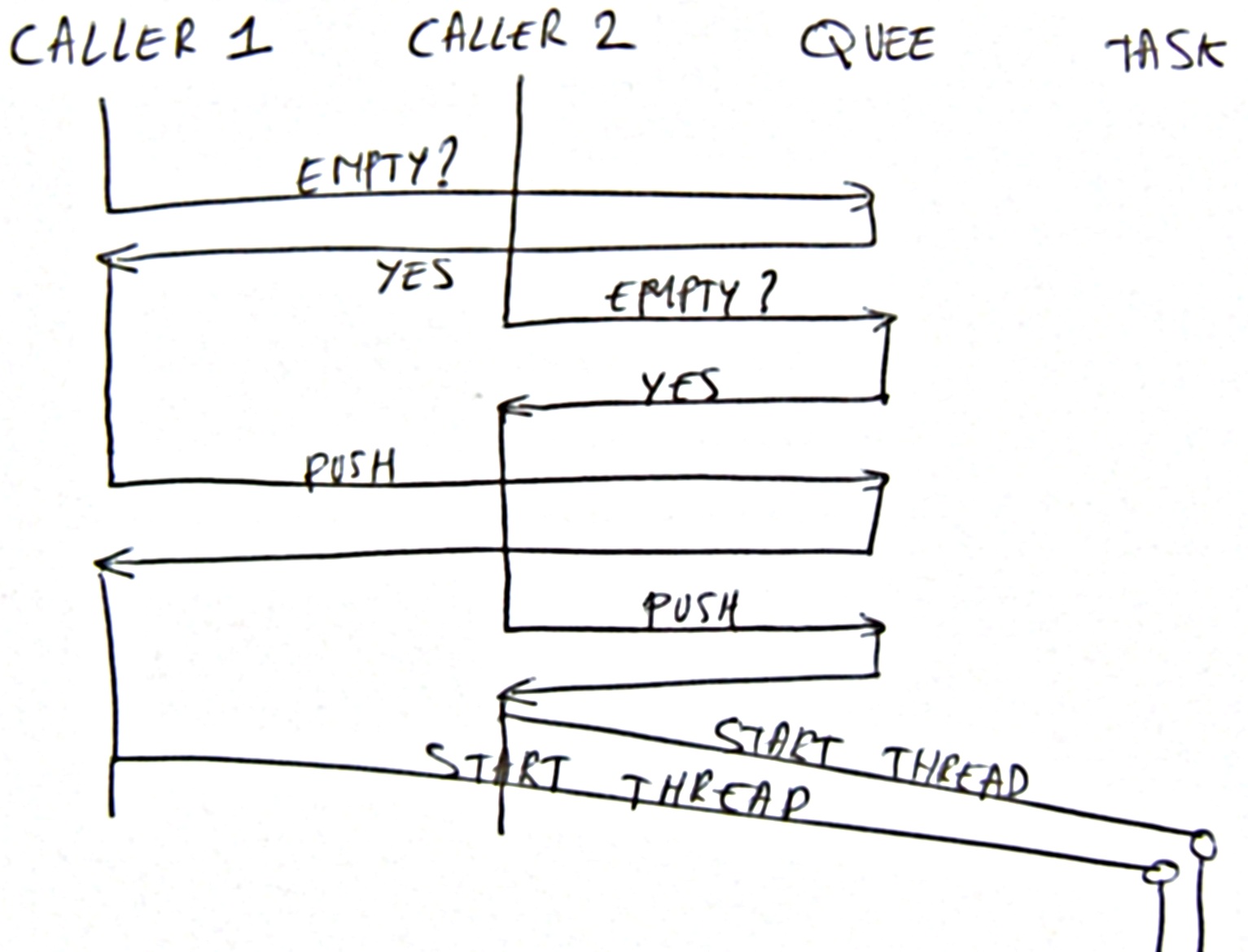
If the task metaobject does not properly lock the incoming queue, multiple activations can lead to multiple threads and consequently multiple threads dealing with the same set of messages.
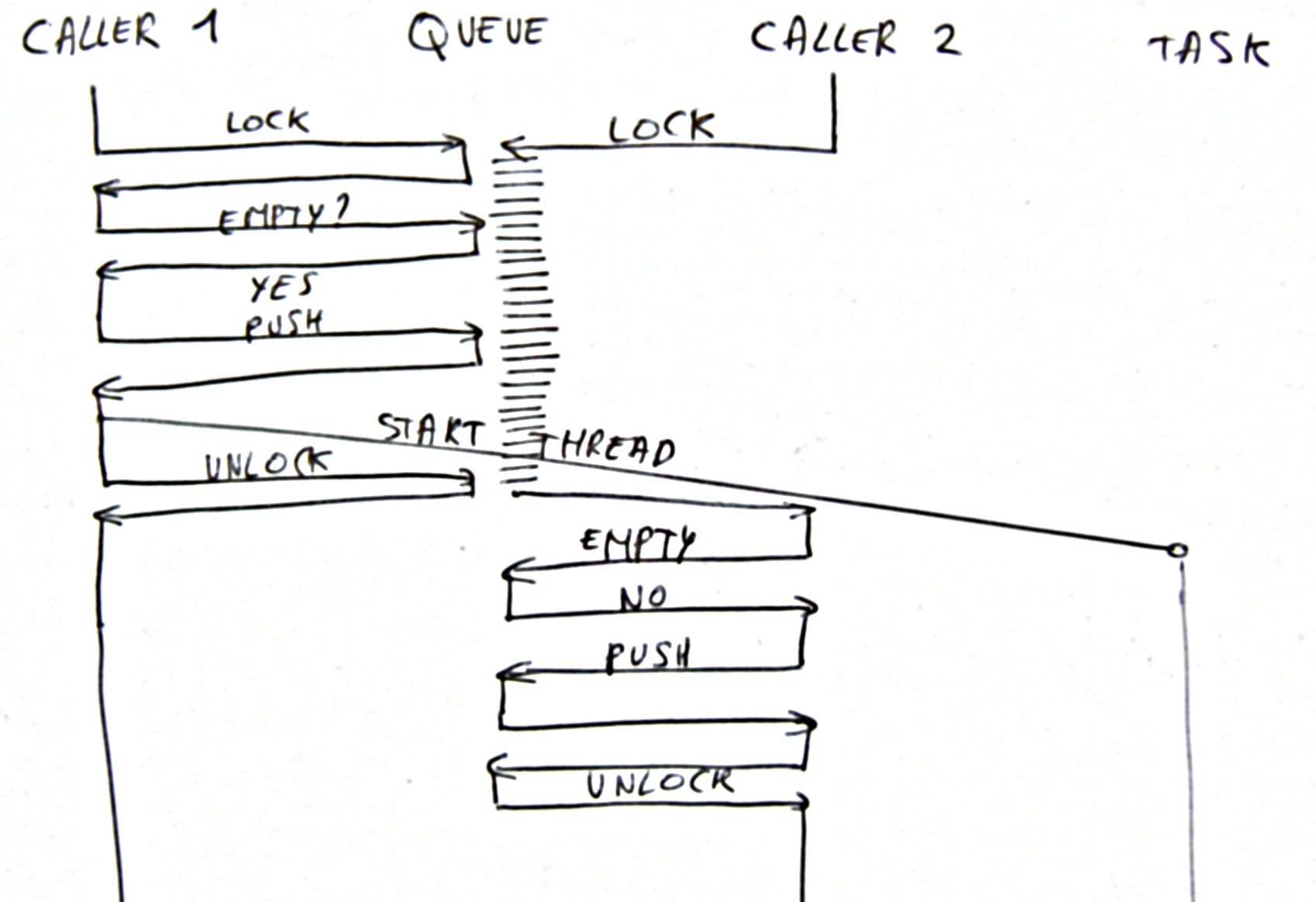
Double Activation 2
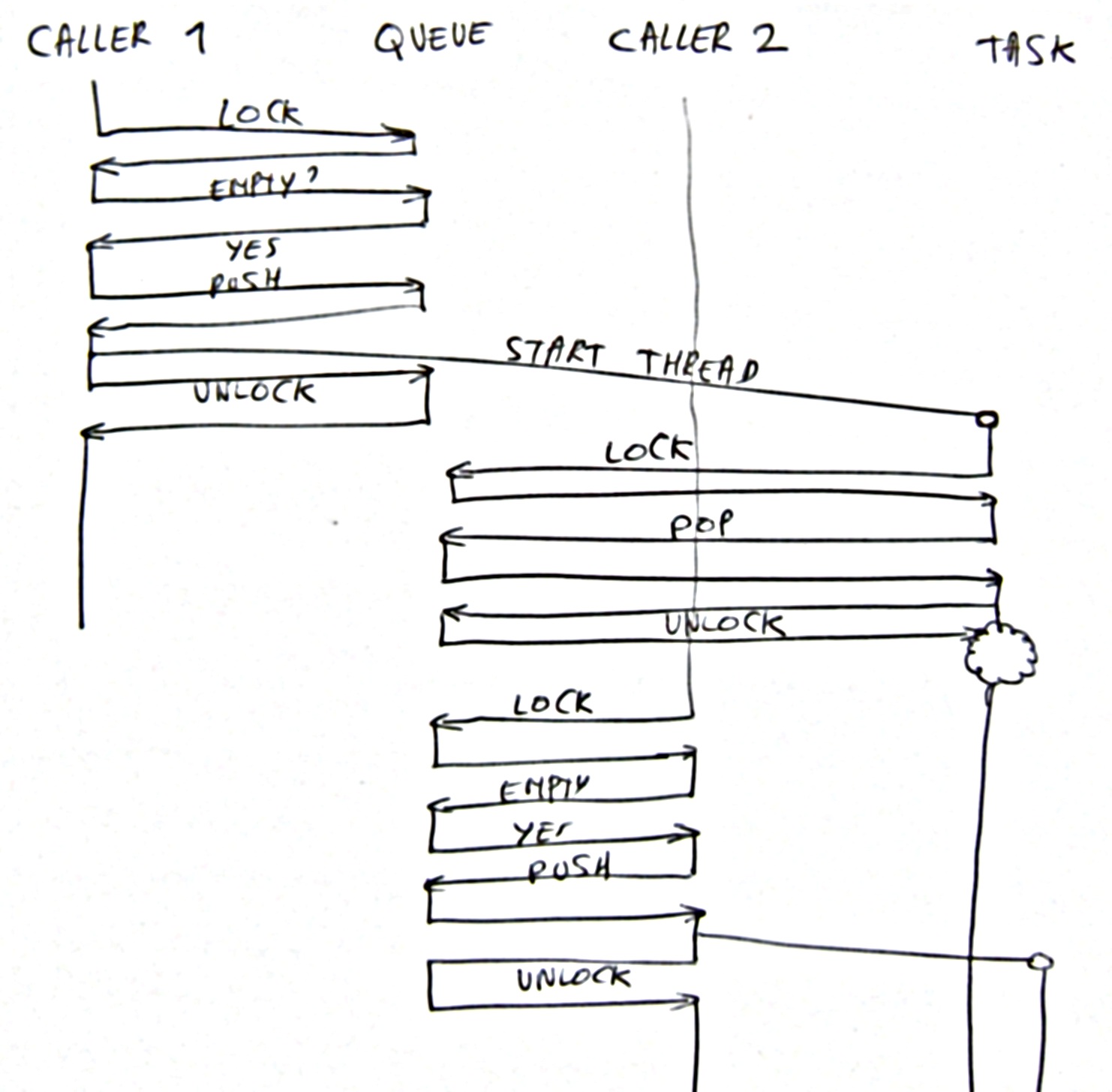
The locking sequence is sensitive in that after starting a thread, the thread directly popped the message and started dealing with it. This could then lead to a secondary activation of the same task, since the queue is empty. As a solution one should introduce a task variable that specifies whether the task is 'active' or not.
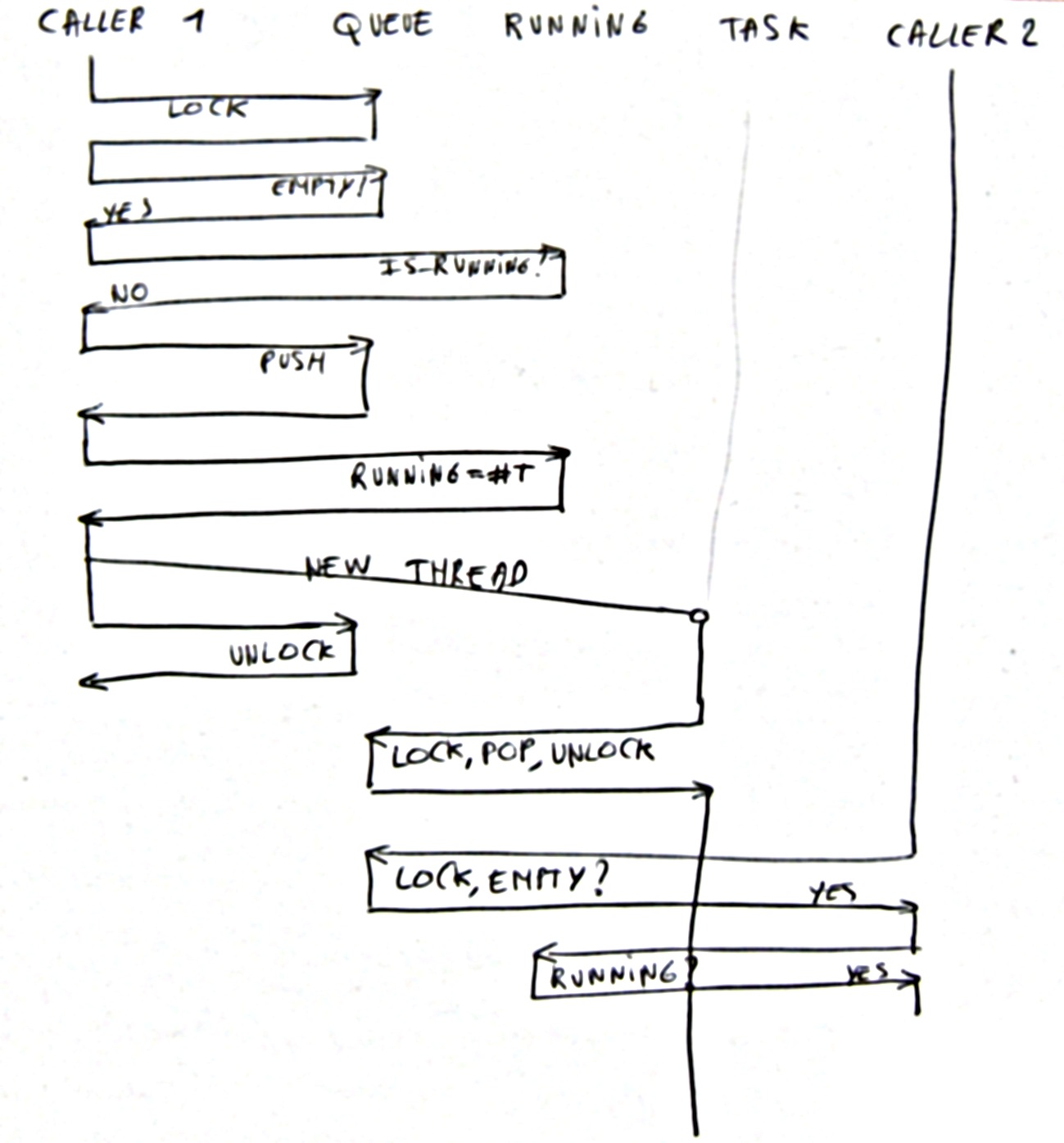
Missed Activation 1
With this approach however, we have the problem that we might miss an activation. Between checking whether the task is active and not starting a new thread, the active flag might have change to false again. This can be solved by locking the queue and the 'active' flag at the same time.
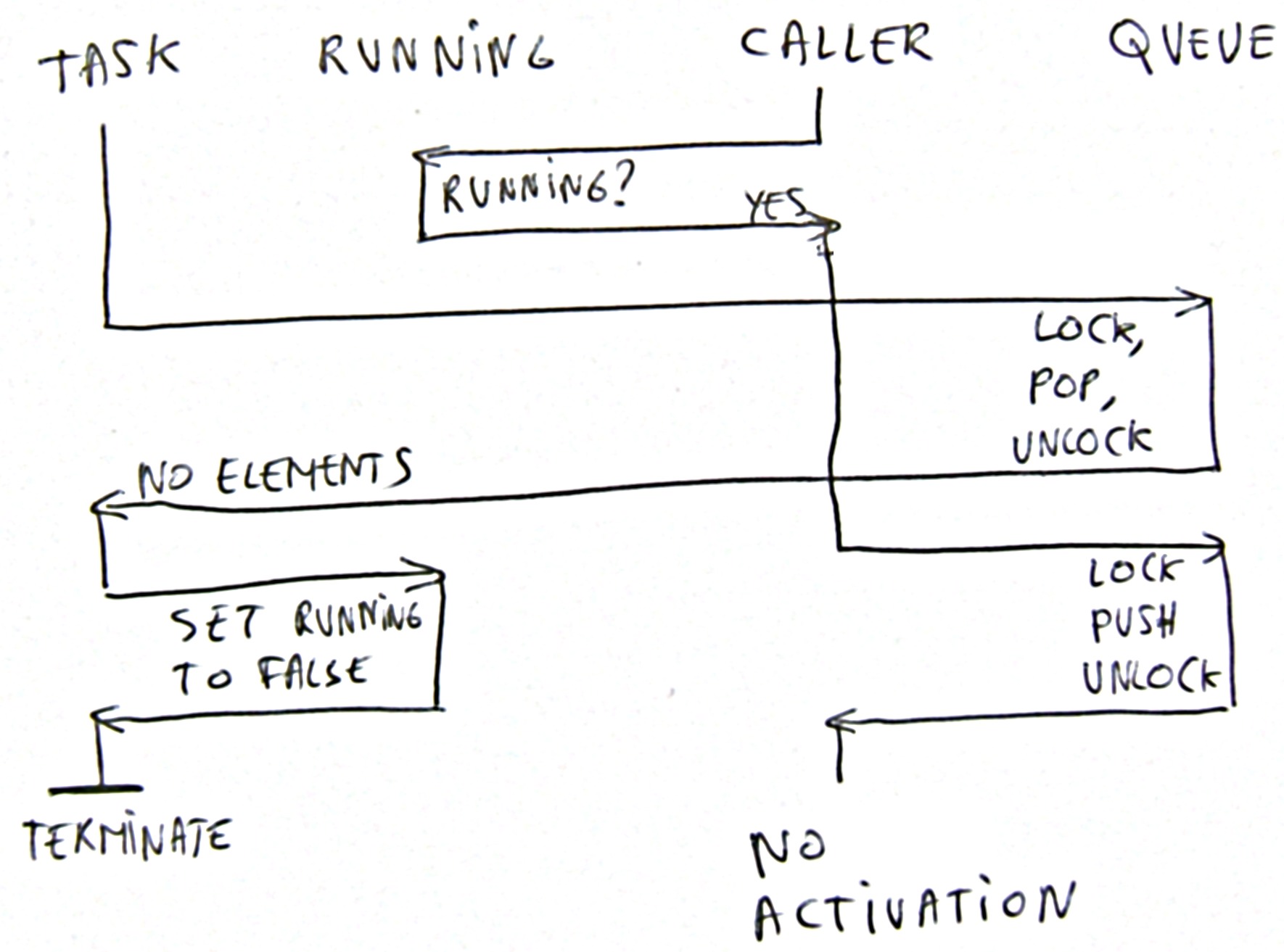
Missed Activation 2
This problem occurs when the taskobject dealt with the last message and the queue is empty. The taskobject is still marked as 'active' and the taskobject is now going to check whether it should continue. It did check whether another cycle of message handling is necessary and decide that it is unnecessary. Now another task pushed a message in the queue , but since the task is still 'active' it will not be activated. We missed an activation.
Unnecessary Message Handling
If we, in order to remedy a missed activation, would verify before setting the 'active' flag to false, whether the incoming queue has more messages, then we would, if the message handlers want to keep some messages in the queue, keep on running through the queue needlessly. To deal with this we should introduce a 'changed' flag that marks whether a specific task queue 'might' have changed elsewhere.Starvation
The last problem, that can occur is that if multiple messages are pushed into the queue, the queue spends quite a lot of time on locks and delays the execution of the task itself. This is unacceptable since it can lead to priority inversion. Therefor we started to work with two queues. The incoming queue that can be locked externally and the handling queue that is accessed only from within the task. The handover between these two queues is merely a pointer exchange and can thus deal with 10000's of incoming messages without performance penalty.Solution
None of the above problems are easy to understand nor solve, and it mainly illustrates the complexities of creating such a working runtime and certainly shows that the 'I'll deal with it in my thread based manner' is very error prone and not something you want to do voluntarily. So now: how does the final activation sequence look like:We have two locks: the first lock is the lock associated with the incoming queue, this is oddly enough, called the task-lock and a second lock, called the updating_state lock, which allows that atomic updating of the 'active' and 'changed' flags. The 'active' flag is true when we already requested the creation of a thread from the scheduler. This flag is only updated when the 'updating_state' lock has been acquired. The second variable is 'changed'. It is true if someone would have asked for the creation of a new thread. This flag is only updated when the 'updating_state' lock has been acquired.
void activate()
{
if (!scheduler) return;
{
Synchronized(updating_state);
changed = true;
if (active) return;
active = true;
}
assert(scheduler);
scheduler->start(this);
}
When the control flow enters the activate method, the situation is as follows.
To avoid confusion, we work with a boolean flag 'active' that reflects the fact that we started a scheduler, which has not yet ended. The active flag will be reset by the handler thread if nothing has potentially changed. To know whether a change could have occurred we use the changed flag, which is true if we want to activate the queue but did not do so since a thread request was already sent out.
So in summary, if we want to start a thread we 1st) set the changed flag and 2nd) if not active, set the active flag and start a thread through scheduler. When the handler thread wants to stop, it first checks the changed flag, and if it is true, starts another round of message handling. If it is not true, it will switch of the active flag. Of course the checking and setting of these flags need to be set atomically. For that purpose we use the updating_state lock. We do not use the active object lock since that would interfere with the push call. Effectively: as long as we are pushing, the object could not start, which is an unnecessary restriction.
Queue running
The last topic of interest is how the activation interacts with handling a collection of messages. This is performed through in the 'run()' method which is called from the activated thread. It takes one argument, 'handle_as_many_as_possible', so that the scheduler can choose to interleave various requests or not. If the scheduler needs to interleave, this flag will be set to false, if the scheduler doesn't need to interleave (sufficient thread available), then it will be set to true. The method return true if more messages can be dealt with and false otherwise.
virtual bool run(bool handle_as_many_as_possible)
{
if (handle_as_many_as_possible)
{
while(step());
return false;
}
else
return step();
}
As can be seen, the run method depends on the 'step()' method which is responsible for dealing with the next incoming message. The 'step()' method will a) transfer the necessary message from the incoming queue, b) execute the handle method and c) check whether something changed, and return true if it did. The order of locking is very sensitive here. A first read of the code might suggest that it is easier to work with 1 lock, but then we introduce starvation under heavy load.
bool step()
{
bool transfer_needed = false;
{
Synchronized(updating_state);
if (changed)
{
transfer_needed = true;
changed = false;
}
}
if (transfer_needed)
/**
* Transfers the incoming messages to the handling queue,
* preserving the order. This method locks the active object during
* its execution.
*/
{
Synchronized(this);
while(!incoming.empty())
{
handling.push_back(incoming.front());
incoming.pop_front();
}
}
if (handle() && scheduler)
return true;
{
Synchronized(updating_state);
if (changed) return true;
active = false;
return false;
}
}
Originally, we had a logic in the step() routine that would handle as many message as possible (similar too 'if (handle_as_many_as_possible) while(handle());' but that broke the semantics of the handle routine. Between calls to the handle routine one can assume that the incoming messages have been transferred. With the above statement, we could no longer assume that and needed an artificial fetch_incoming routine.
Termination
There are two aspects on termination. The first is the termination of a task. This is done by allowing the task to call 'deactivate()'. If it does so, that task will no longer deal with any other incoming message.The second part of termination is to track which tasks are still available and which ones are not. This is done through a separate special task: the active object pool. Every time a new task is created or deactivated, this pool is informed by the scheduler. We call these two aspects: sunrise and sunset for a task.
The advantage of having such a pool are as follows:
Advantages
Space Separation
The first advantage of Active Message Queues is that they tend not to
share data across different tasks. Each task is encapsulated in its
own object and the task metaobject is the only one able to refer to the task
itself. This means that the task state cannot be
modified without sending a message.
Of course there is always the possibility of passing a pointer to the
same data structures to two different tasks (remember we copy each of the
incoming arguments into a message class, if it is a pointer, we
effectively start sharing data again). We considered possibilities to
ensure data space separation by really serializing and deserializing
the data but in the end this performance impact was too high a
cost. Instead the task should assume that each message is a readonly
structure. Of course, when working in a distributed system, the
messages need to be serialized and deserialized, in which case we have
guaranteed space separation.
Since we have space separation and should program as such, we do not
have race conditions and since we don't have race conditions we do not
need locks, making programming much easier.
Time Separation
The second separation is in time, meaning that one task cannot delay
the execution of another task by not blocking the caller. Instead,
whenever a message is send to a task the caller can directly continue since the message send is non-blocking.
Because no task will actively wait for another task, we cannot have
deadlocks between tasks. Of course, if a task is supposed to send back
a message but doesn't, we can still have starvation, but
that has to do with the programming logic and has little to do with
the abstraction itself.
Both, time and space separation lead to a lockfree programming style.
Syntactical Encapsulation
Each task is declared in its own class; the taskobject class.
The methods declared in this class must be implemented by the
programmer, who will normally place all these methods in one source
file. Within this source file, we know that only one thread at a time will run.
None of the messages will be executed concurrently.
This makes it easier to answer questions such as: 'how many threads
could possibly go through this piece of code ?' and 'is it possible
that this task variable is accessed at these two different positions
?'. The answers are respectively: 1 and no.
Although a straightforward result of the setup of our system, it is
unique. Most threading libraries allow you to create a thread and it
requires a lot of discipline from the programmer to ensure that such
a thread stays only within the same code. To present this in analogous
form: threads can be compare to the 'good' (well..) old fashioned goto
statements, while active message queues can be compared to higher
level control structures (for, while, repeat until etc).
Dissociation from Scheduling
The last advantage of active message queues is that due to their time
and space separation, the runtime is no longer forced to allocate 1
thread to each task. Instead, the runtime can choose to run 100 tasks
with only 1 thread, or 10 tasks with 10 thread, or choose to allocate
specific tasks to their own, directly available, thread and use one
thread to deal with the tasks of lower 'priority'
2 tasks, 1 thread
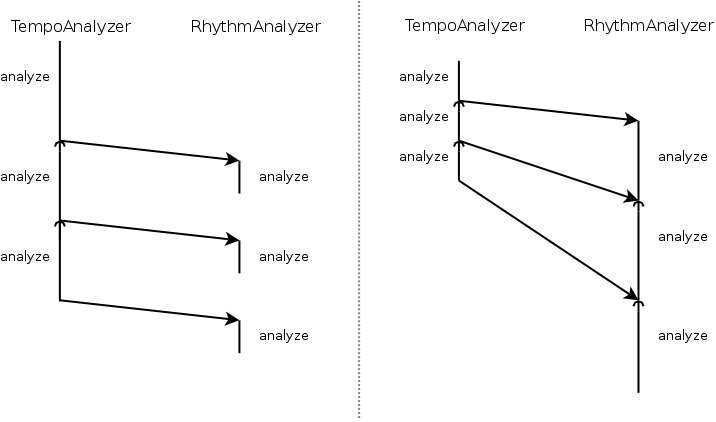
Assume that we have two analyzers: a tempo analyzer and a rhythm analyzer. The rhythm analyzer requires the tempo of a particular song before it can start analyzing the rhythm, as such we asked the tempo analyzer to notify the rhythm analyzer that it finished a certain song. These two tasks can be ran with one thread and if we allocate only one thread we will see the following control flow:
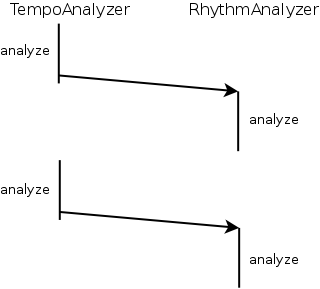
In this graphic time runs from top to bottom. The two tasks are listed horizontally.
We find that at any single point in time there is only one task running.
2 tasks, 2 threads
If we would now have two tasks we have the following two nice scenarios. Either the rhythm analyzer is slower or it is faster than the tempo analyzer. Below we show the two control flows we generate in such scenario. Obviously: it doesn't matter since the queues take care of the 'too many' messages part. It is however a nice demonstration that shows that a typical producer/consumer problem is non existent.
Conclusion
We presented an abstraction that allows tasks to be separated in time, in space, syntactically and be scheduler independent (that is x tasks can be ran with y threads). This abstraction offers the advantage of lockfree programming and consequently cannot deadlock.
The software is available at http://activeobjects.yellowcouch.org/ and is distributed under the GPL2.
Bibliography
| 1. | The Caltech Infospheres Project Joseph R. Kiniry, K. Mani Chandy Technical report published by the Caltech Infosphere Group in 1997-1998 http://www.infospheres.caltech.edu/ |
| 2. | Caltech Infospheres Project Overview: Information Infrastructure for Task Forces K. Mani Chandy Computer Science 256-80; California Institute of Technology, Pasadena California 91125; 14 November 1996; mani@cs.caltech.edu http://www.infospheres.caltech.edu/ |
| 3. | Leveraging the World Wide Web for the Worldwide Component Network Joseph R. Kiniry, K. Mani Chandy Presentation given at OOPSLA October 1996 http://www.infospheres.caltech.edu/ |
| 4. | Agent mobility and Reification of Computational State Werner Van Belle, Theo D'Hondt International Proceedings of Infrastructures for Agents, Multi-Agent Systems and Scalable Multi-Agent Systems; Springer Verlag; Lecture Notes in Artifical Intelligence (LNAI 1887); Editor(s) Tom Wagner and Omer Rana; pages 166-173; June 2000 http://werner.yellowcouch.org/Papers/mobility/index.html |
| 5. | The CBorg Mobile Multi-Agent System Werner Van Belle, Karsten Verelst, Theo D'Hondt Edited Volume on Infrastructures for Large-Scale Multi-Agent Systems; ACM; October 2000 http://werner.yellowcouch.org/Papers/cborg00/index.html |
| 6. | Working Definition of Components David Urting, Werner Van Belle, Koen Debosschere, Yolande Berbers, Viviane Jonckers, Chris Luyten, Tom Toutenel Technical Report / SEESCOA Deliverable 1.4; April 2000 http://werner.yellowcouch.org/Papers/components/index.html |
| 7. | The SEESCOA Component System Werner Van Belle, David Urting Technical report SEESCOA Deliverable 3.3b; January 2001 http://werner.yellowcouch.org/Papers/seescoad1/index.html |
| 8. | The C++ Programming Language Bjarne Stroustrup Adison Wesley, 1998 http://www2.research.att.com/~bs/ |
| 9. | DJ-ing under Linux with BpmDj Werner Van Belle Published by Linux+ Magazine, Nr 10/2006(25), October 2006 http://werner.yellowcouch.org/Papers/bpm06/ |
| 10. | Multi-threaded Programming in Qt Trolltech (currently owned by Nokia) http://qt.nokia.com/ |
| 11. | Concurrent programming in Java. Design principles and Patterns Doug Lea 2nd Edition, ISBN: 0-201-31009-0, The Java Series, Addison Wesley, 2000 http://g.oswego.edu/ |
| 12. | Communicating Sequential Processes C.A.R. Hoare Prentice Hall International Series in Computer Science, 1985. ISBN 0-13-153271-5 (0-13-153289-8 PBK) |
| 13. | Supporting Multiparadigm Programming on Actor Architectures Gul Agha Proceedings of Parallel Architectures and Languages Europe, vol.II: Parallel Languages, Lecture Notes in Computer Science 366, pp 1-19, Springer-Verlag, 1989 http://osl.cs.uiuc.edu/ |
| 14. | A Foundation for Actor Computation Gul Agha, Ian A Mason, Scott F Smith, Carolyn Talcott Cambridge University Press, 1993 http://osl.cs.uiuc.edu/ |
| 15. | Modern C++ Design: Generic Programming and Design Patterns Applied Andrei Alexandrescu Addison-Wesley, 2001, ISBN 0-201-70431-5 http://www.informit.com/articles/article.aspx?p=25264 |
| 16. | Smart Pointers in Boost Bjorn Karlsson Dr. Dobbs; 1 April 2002 http://www.drdobbs.com/cpp/184401507 |
| 17. | The New C++:Smart(er) Pointers Herb Sutter Dr. Dobbs; 1 August 2002 http://www.drdobbs.com/cpp/184403837 |
| http://werner.yellowcouch.org/ werner@yellowcouch.org |  |