| Home | Papers | Reports | Projects | Code Fragments | Dissertations | Presentations | Posters | Proposals | Lectures given | Course notes |
|
|
The Failure of the Connectionless Model and the Vice Software ModelWerner Van Belle1,2* - werner@yellowcouch.org, werner.van.belle@gmail.com Abstract : We investigate a number of modularity problems that arise from using a connection-less software model. A connection-less approach leads naturally to an unmanaged use of direct references. This results in crucial software composition complications such as the inability to replace objects, difficulties to track outgoing messages, difficulties in writing glue-codehidden communication. As a solution to these problems, we present our connection oriented software model, Vice. Its reflective design makes that it surpasses existing architectures in its modularity, manageability and performance.
Keywords:
modular software, connection orientation, reflection, efficient meta-level architectures |
1 Modularity
One of the key issues in modern software engineering is the need for modular application buildup. Modular refers to the possibility to easily alter a software entity externally, such that it serves a purpose slightly different than originally intended. We are interested in reusing a software component externally because in practice software components never offer exactly what is required and cannot always be directly modified. This can be because a) the code is running outside our administrative domain, b) because the code is not available, c) because modifying a component its internals would obfuscate it or because d) modifying the internals of the component would complicate communication with other non-altered components.
In this paper we will investigate a number of well known software modularity problems and track their cause down to the undisciplined use of direct references. We will show how most solutions introduce some form of indirection. Based on these observations, we will argue that a connection-oriented model, when appropriately designed, offers a more coherent solution towards software design and deployment.
2 Running Example
As a concrete example we will investigate something that should not be too difficult: make an application fault tolerant by inserting appropriate replication-glue between its different components. The replicas will execute on multiple computers. The glue itself will behave towards the original library as if it were an original non-replicated object. Therefore it will dispatch any incoming message to all the replicas and catch all outgoing messages of the replicas. These messages are investigated and a consensus is reached by discarding wrong or missing answers, which indicates a failure of one the computers. If the applied software model allows for modularity, then inserting these replicators should not be too difficult. In practice however, creating such a fault tolerant system turns out not to be easy, because of a number of reasons, which all boils down to the same problems: direct referencing.
The software we want to make fault tolerant is the (imaginary) Realism-library which implements the dynamics of a particle system. The library has basic rendering support offered by a renderer class and makes use of point objects to specify the particles. A typical run of the Realism library consists of creating a large amount of particles and then informing each particle of their neighbours (within a certain radius). To evaluate a run of a particle system, all particles are requested to pass their movement vector to their neighbours. After one run, all vectors are summed together to obtain the new positions. The black boxes in picture 1 present the class hierarchy. From a software engineering point of view, we will try to make a part of this library fault tolerant, without modifying any of the existing code.
3 Direct referencing prohibits object replacement
One of the first problems software integrators encounter when trying to use third party software is the inability to replace software pieces within a library. Such an action might be necessary to add functionality to a library or to link the library its functionality with other libraries. For instance, in our case we want to replace every occurrence of a point object with a replicated point. Developing the replicated point itself should not be too difficult. It becomes however more difficult to convince the physics class to actually use this new 'replicated' object. If the Realism library is not designed to be reused, then it might as well be completely impossible to integrate our new points into the library.
![\includegraphics[%
width=1.0\textwidth]{ReplicationFactory.eps}](img1.png) |
Picture 1 shows what kind of indirections are required on the standard Realism classes (the black ones) to easily allow object replacement. Only when the library offers a factory[GHJV94] (the red classes) can we easily insert our own replicated point definition (the blue classes). When the library makes use of a factory, it will, instead of explicitly calling new Point(<initialisers>), call factory.createPoint(<initialisers>). Then through proper initialisation of the library, with a modified factory, we can make sure that a replicated point is instantiated whenever necessary. This technique works fine for replacing the instantiating of classes, however it still does not solve all problems. Suppose, we want to replace the point-hierarchy with an entire new hierarchy, for instance with Point replicas, Wall replicas and so on, then we will encounter hierarchy conflicts. E.g, it might not be possible to insert Replica objects everywhere in the physics library. Especially not where the library expects Wall objects. To overcome this problem a new level of indirection, such as offered by the implementor pattern [GHJV94], might be required. Clearly this illustrates how direct references to objects and classes cannot easily be overridden with other definitions.
The illustrated problem of replacing the identity of an object is certainly not new. A large number of techniques exist to increase the modularity of an application by means of object replacement [GS00,Con01]. For instance, templates in C++ were introduced to allow the possibility to declare a class that works together with any previously unspecified object[Str98]. In a similar way the introduction of interfaces in Java [CWH01] is necessary to allow the passing of objects that implement a certain interface but cannot stem from the same base-class. E.g, without the notion of interfaces, the Java RMI framework would have been much more difficult to create. There exist also a whole range of tricks to solve the problem of object replacement. Stub-compilers ([CORBA, rmic] will generate replacement-classes given a certain interface, however these still require the program to be designed to use these stubs. In a language such as Java a third party library may be coaxed in using a non standard class-loader. This could make it possible to create new classes on-the-fly or load other classes instead of the required one. However, this is a very difficult thing to do and should be regarded more as a hack than a well planned software composition process. Other languages, such as Smalltalk, have certain build-in reflection features might enable object replacement more easily by combining the use of methods such as messageNotUnderstood and a possible re-implementation of the new-operator. Other researchers go even further and argue that the possibility to dynamically modify the identify of any object is crucial. Such a behaviour can be implemented by means of special cell stores, that keep track of reverse reference lists [KK95,KW].
The presented example illustrates that, in object oriented design, libraries must be designed for reuse. If a developer simply writes the bare functionality then very probably the class is not reusable. However, ensuring that a library is reusable requires a lot of indirections. (replacing class loaders, name-servers in RMI, overriding 'new', templates, interfaces, reverse reference lists and so on...). Basically, every solution replaces direct references with better manageable indirections.
4 Direct references prohibits tracking of outgoing Messages
![\includegraphics[%
width=1.0\textwidth]{OugoingMessageProblem.eps}](img2.png) |
Another problem often encountered when adapting existing software to ones needs is the inability to track, intercept and/or modify outgoing messages. In our example we have already replaced every point with a replicated point. Because we have no intention in re-implementing the points themselves we want to make sure that our replicator will make use of the implementation of the standard points, therefore it will instantiate multiple points for every created replicator. The replicator can easily intercept incoming message1 and reroute them to the replicas. It can also intercept all return values from these replicas. However, to avoid that the replicas individually access external (possible non-replicated) objects, the replacement object must also intercept all outgoing calls made by the replicas, otherwise external objects might be accessed multiple times. E.g, in our example (figure 2) the point object will receive notification of all neighbouring points to modify its energy vector. Once this is done, the physics class will ask all points to inform each other of the new energy vector. Clearly, it is extremely difficult to prohibit the replicated points to not call the neighbouring points because these references are direct references and can be not intercepted easily.
Tracking outgoing messages is a long standing problem and has been recognised as a problem by many research groups in a number of domains. For instance, to be able to compose components the composition filters approach [ALV92,AWB+93] allows the declaration of filters that can track outgoing messages. In the domain of software testing and verification this problem is also recognised as being a major obstacle in developing test-suits [WJ98,KGH+95,WH92]. There are even researchers that argue that, in addition to a standard API which describes an incoming interface, the specification of an outgoing interface is also necessary [Bel03,RJM+98,Wyd01].
To alleviate this problem, a whole range of interception techniques and tricks might help. All of them are based on replacing a direct reference with and indirect one. E.g, one can make use of dynamic object replacement [Con01], wrappers [SJ01], automatically generated subclasses [TP01] and extremely invasive techniques at the meta-level such as intercepting and reifying all transmitted messages [Wu98,Wol89,Riv96a,McA95,Riv96b]. The latter is best illustrated by means of the actor formal model [AMST97], which rely entirely upon direct actor addresses for communication. To track outgoing messages, this formalism should be extended with appropriate meta-level operations [T.91]. From all these techniques only the meta-level approach seems to have some added value and is more than a 'trick', however, as we will explain in section 7, meta-level programming itself is often not modular, nor manageable.
5 Passing Direct Addresses Require Address Translation
![\includegraphics[%
width=1.0\textwidth]{PassingSelfProblem.eps}](img3.png) |
A third problem with direct references occurs when they are passed from one part of the software to another, thereby breaking modularity. Looking back at our example, let us assume that every point, when it modifies position, informs a renderer class (a form of call-backs) with as an argument a reference to itself. In such a scenario, every point will pass itself as an argument to the render library (as illustrated in figure 3). The replicated point, which is now, somehow, able to intercept all the outgoing calls, needs to unify the three calls to the renderer class: acceptPoint(``Point1a''), acceptPoint(``Point1b'') and acceptPoint(``Point1c'') such that the replicated point is actually passed to the render class acceptPoint(``ReplicatedPoint1''). To implement such an address translation, the replicated point needs to understands the semantics of the protocol between all communication partners of the replicated points. In other words, our replicated point must be specifically tuned to replicate 'points' and not simple 'any object' it encounters. This clearly breaks modularity. Not only is our point and our physics library not modular because we need to understand the semantics of the protocol they apply, but also our own glue code is no longer modular because it has been specifically tuned to only work with (parts of) the Realism library.
The problem of reference modifications is recognised for a long time in the domain of distributed systems under the form of 'network address translation' (NAT) and has even become more prominent with the rise of mobile devices [BVD99,BTP96]. For instance, proxies on all kind of levels, HTTP, FTP (iptables and ipchains), IP, Quake Multi-player, ICQ, hardware (mac) addresses [CRS99,Wes98] are relatively difficult to implement because of address translation. The problem however is ofter reduced up to the problem of pluggable modules [KMP00], each which understands a certain protocol.
In certain environments in is possible to solved the problem of references pseudo-automatically. When the structure of all communicated messages is understood then it is possible by using a graph traversal algorithm to find and replace direct references automatically.
6 Sharing of direct addresses allows Hidden Communication
To illustrate the problem of direct references even further let us for a moment assume that two software entities share a direct address. This can be either a memory address, the same file on disk or the same remote location. If a component relies on the availability of such a shared direct address then its entire reusability falls apart because such direct addresses allow hidden communication. Components can in such a case communicate by modifying the state of a shared hidden variable. Since external components does not necessarily know, and cannot keep easily track of shared addresses, it might become very difficult to fully modify the protocol used between components.
In our example, let us assume that the different replicas of the points are running on the same computer and all rely on a random function, e.g; to ensure numerical stability. In such a case the different replicas of one point will behave differently because they communicate with each other. The first one calling the random function will get a certain result, while the second one calling the random function its result will depend on the first call to the random generator. As such there is a communication channel between the different components, a communication channel that cannot easily be monitored or adapted.
Another instance of the same problem is accessing the same shared resources, that is, reading and writing to the same files.
7 Reflection to overcome modularity
problems ?
![\includegraphics[%
width=1.0\textwidth]{ReflectionProblem.eps}](img4.png) |
A well known panacea to all these problems is meta-level programming and reflection, which dates back to the early work of Smith [Smi84] and Pattie Maes [Mae87]. Reflection is the ability of a system to introspect its own behaviour and eventually alter it by absorbing new behaviour. A reflective system typically consists of two separated, but causally connected layers: the base-level, in which the core functionality of the application is expressed and the meta-level, in which the execution logic of the system can be altered. How much reification and absorption a reflective system allows depends on which reification and absorption operations are available. This defines the meta level protocol. For instance, certain low-end reflective systems allow the introspection of the own data store, but have difficulties intercepting any incoming messages [Wu98]. Other allow this, for instance by means of messageNotUnderstood[AGR83], but these are limited in their capacity of intercepting outgoing messages. Again others, allow structural reflection and can alter the representation of objects, but these seldomly take care of replacing the identity of objects [Wol89]. Others are specifically designed for behavioural reflection and can alter the message flow between components [SJ01,AWB+93,Riv96a]. Many of these systems are often good in solving a particular problem. E.g, reflection has been successfully applied to build open compilers [LKRR92] and open operating systems [Yok92]. It has also been used to separate concurrency management [Wu98,YT87,JGL98], fault tolerance [JNT+95], mobility [TP01,SJ01], distribution [RJM+98,McA95,JGL98] and other non-functional aspects from the core functionality of the application.
However, despite these positive results, meta-level programming has been criticised for being relatively slow and in general does not solve problems of modularity. Instead, the problem of composing meta-objects has been often considered the next problem to solve [BA01,MMC95,Gra89]. Below we will illustrate two composability problems associated with meta-objects and reflection.
A first modularity problem arises when meta-objects are used to selectively intercept, or alter, communication between objects. E.g, assume that we have replicated all points on different machines in order to create a fault tolerant simulation. At a certain moment, one of the machines is upgraded and will offer a slightly different implementation for the points. When asked to do so it will create a point that has knowledge of its own colour. So instead of setPosition(x,y) we now need to call setPosition(x,y,colour) when communicating with the points on that particular machine. In such a scenario we will need to adapt the output of the replicators in order to insert certain extra information when communicating with the upgraded machine. This however requires the meta-object to be aware of the direct target of the message. In other words, the meta-object must have been written in such a way that it will select for which target messages it will adapt the communication. This introduces non-modularity for two reasons. First because, the adaptor must have been written in order to adapt the message-flow depending on the target, hence a simple meta-object that contains only the core functional adaptation logic will not be reusable in this context. Secondly, when a second meta-object is introduced the target of the message might be different and the adaptor might not work correctly anymore. As long as meta-objects need to use direct references will they very likely not be reusable.
This thought-experiment not only exposes the non-modularity of meta-level architectures, but also illustrates the performance penalty of using a connection-less approach. E.g; the insertion of this single adaptor requires the tracking of all messages sent out from the replicator to all its communication partners, while maybe only a very small amount of messages might be sent to the ones that need adaptation.
Another important composability problem finds its roots in the scattered nature of meta-objects. Meta-objects are often declared closely to the objects themselves. To manage a large set of meta-objects of the same type, one often falls back to some form of centralised manager. E.g; our adaptor meta-object might either make use of static variables in order to share information between all instantiated meta-objects, or it might use several central management objects, depending on who initialised the base-object. Depending on the type of meta-object other management techniques might be appropriate. This naturally leads to multiple meta-object management approaches within the same application. However, the different strategies does not necessarily work well together and they might require adaptation themselves. Yet, writing such a meta-manager is often extremely difficult because one must first thoroughly understand all the involved management strategies and only then can a very application dependent (hence, non-modular) be written.
The bottom-line of this is that meta-level architectures might allow for the adaptation of base-objects but certainly make it not easy to do in a modular and manageable way.
8 The VICE component model
Up until now, we explained how direct references introduce a whole range of modularity problems. Meta-level programming might solve these problems, but does so in a non-modular way and is very difficult to manage. Now, we will investigate how the introduction of explicit connections results in a more manageable software development model. The model we have created is called the VICE component model.2 The model takes ideas from Actor [AMST97,T.91] systems, the PI [Mil99] calculus and ROOM [SGP94] as well as a good deal of experience with Java RMI, Trolltech's QT libraries and others. The model itself contains four important concepts. Components form the modular building blocks of an application. Ports form entry and exit points towards the different interfaces offered by a component. Connections are used to connect two ports to each other. And finally, messages are transmitted over connections by using the local ports.
8.1 Components
Components are the basic building blocks of an application. Every component can create another component by using the create_component(creator, type, name) command. The first argument specifies who should be considered to be the creator of the component, and thus initialise the component. The second argument is the type of the component. Depending on the runtime this can be a class description, actual code or a library reference. The third argument designates the name of the new component. This name should be unique within the application scope.3 Once the component is created the by the runtime, a connection will be set up between the creator and the created, to allow proper initialisation.
Every component in the system has its own code and data space and does not share this with other components. Components should also never use communication means that are hidden for the VICE runtime system. In particular, two types of hidden communication should be clearly avoided. First, components should never pass direct addresses to other components. The VICE runtime should discourage this by all means possible. E.g, address mangling strategies, memory protection schemes, virtual memory mappings and so on. Second, common resources that might allow communication should never be accessed directly. E.g, files, network access and so on... In order to allow the runtime to keep track of messages from and to these resources, they should be encapsulated in components themselves.
8.2 Ports
Every component can create multiple ports. Every port forms a connection-point on the component and provides access to certain behaviour. E.g; a component might offer the component's core functionality on one port while offering a concurrency management strategy on another port.
Ports are always full-duplex. They can send messages as well as receive messages. A component can send out a message over a port by using the send_message(port, message) command. When a message cannot be immediately sent out the message will be queued until the port is connected. To handle incoming messages the component should provide a receive_message(port, message) call-back function. When a message arrives on a port the runtime will call this function. When receive_message cannot be called, because it is still running, then the incoming message will be queued. If the component does not understand the incoming message then it should call handle_message(port, message) in order to allow the runtime to handle it further.
Ports are never shared with other components. In order to actually make two components communicate, two ports should be connected.
8.3 Connections
Two ports can be connected through invoking create_connection(component1, port1, component2, port2, description). The first and third argument specify the names of the two components. The second and fourth argument describe the kind of ports to be connected. The last argument is connection information that is passed to both components. Once the runtime receives this command, both components will be asked, through the create_port(type, description) call-back, to offer (and possible create) the port that should be used. The first argument specifies what kind of port is being looked for (E.g; clients). The second argument contains the connection information.
In contrast to most connection oriented systems, VICE-connections can also be created by other components than the ones that are to be connected. E.g, component A and B can be linked by component C. Once a connection exists, the underlying system will deliver messages exactly once, thereby preserving order.
8.4 Messages
Messages are self-contained object graphs. They behave as if they are deeply copied when calling send_message. This can be achieved by actually copying them or through a copy-on-write memory map at the sending side.4
Message are explicitly represented in order to allow all components to understand the structure of a message. In dynamically typed languages (Java, Scheme, Smalltalk...) this happens automatically. In other languages, explicit structural information should be attached to the messages [BBCV99]. All messages carry extra non-functional information which is automatically (re)transmitted with every newly created message. This makes unique identification and tracking of messages possible. [KJAvR03]
9 The VICE reflective model
![\includegraphics[%
width=1.0\textwidth]{ViceApi.eps}](img5.png) |
The presented runtime concepts are offered to the component programmer as an API (depicted in figure 5). In order to offer a manageable and reusable software model, certain operations of this runtime are treated specially. Below we discuss the reflective nature of the VICE runtime by investigating the meta-level protocol.
9.1 Reification
The runtime consists of different operations such as message creation, port creation, handling messages, sending messages, creating connections and creating components. Most operations are offered by means of a standard API. Operations such as sending and receiving messages are executed immediately by the runtime library. However, certain other operations such as creating components and setting up connections will be executed through explicitly sending a message towards the runtime system. (Depicted in figure 5). To support such reified operations, every component makes a system port available that will automatically be connected to a component that represents the runtime architecture. We will now further investigate the protocol to set up connections and create components.
![\includegraphics[%
width=1.0\textwidth]{ConnectionPhase.eps}](img6.png)
The protocol to set up a connection consists of three phases. First, somebody wants to setup a connection between two components. This connection is specified by naming the two components involved and describing the required port. Once the runtime receives such a request, it will ask the two components to offer a port, based on the port descriptor. The second phase consists of each component offering an address of the port that should be used. And thirdly, once both port addresses are received by the runtime the two ports will be linked together by sending two Link messages. Figure 6 illustrates the entire process.
![\includegraphics[%
width=1.0\textwidth]{CreationPhase.eps}](img7.png)
The component creation protocol is reified similarly. A component contacts the runtime to create a component by sending a create message over its system port. This message contains the name of the requester, the type of the component to create and the name this new component should have. When the runtime receives this message, it will create the required component and immediately retrieve the system port from it. Afterward it will set up two connections to this component using the regular protocol. One connection from the reified runtime component toward the component its system port and one between the init port of the created and the created port of the creator. This allows the creator to initialise the component by sending certain initialisation messages to it.
The reification of both the runtime and the operations necessary to create and connect components might enable us to easily modify the connections between components. Nevertheless, there is still one piece of the puzzle missing and that is the possibility to alter centrally the message flow towards the runtime system.
9.2 Absorption
![\includegraphics[%
width=1.0\textwidth]{RuntimeSystemReflection.eps}](img8.png)
The runtime system offers a possibility to alter the creation of components and connections. This is accomplished by a) reifying the runtime and the protocol needed to create and connect components (as already explained) and b) by allowing a component to intercept this protocol towards the runtime system. The latter is achieved through a hook on the runtime architecture. Every connect or create request that arrives from one of the clients will be sent over the hook. This hook consists of two ports and are normally immediately connected without any interference. The first port (called outgoing) will send out all the connection and creation requests while the second port (called incoming) expects these messages to come back. Only when a connect or create requests arrives at the incoming port will the necessary logic be executed.
9.3 Example: Modular Replication
As an illustration of the modularity offered by the VICE software composition model, we will now turn back our attention to our initial example of transparent replication. We will replace every instantiation of a point with one replicator and three points. Below we will discuss two component types: the replicator-generator and the replicator. The replicator-generator will replace the connection and creation requests. The replicator tracks the incoming and outgoing messages and verifies them.

-
- Replicator

link . send_message_outside ( messages [ 0 ] );
The above code is modular because it does not require the replicator to know anything about the components it is replicating: it does not need to know the interfaces of the components the replica wants to communicate with, which makes it easy to intercept all incoming messages (coming from e,g the physics class). The replicator component itself has also no problems in intercepting outgoing messages because messages can only be sent out over connections and theses are all intercepted. Similarly, to replace the few direct addresses that are passed (the names of the different points), the replicator does not need to understand the protocol used between a Point and its communication partner.
10 Validation
The presented approach has been validated by four universities, all working together on a common test case. This common test case was a video surveillance system that would keep a record of the video-streams, detect motion and decide which cameras should be zoomed in, in order to ensure complete coverage of the environment. The development process itself consisted of 3 distinct phases. First, every university would agree to create components offering a certain functionality. E.g; application specific components offering motion detection, zoom behaviour, user interfacing, image storage and others. Second, after agreeing on a suitable behaviour, the components were developed. This development process ran entirely parallel without much interaction (given the highly different schedules of the different universities and their geographical location). Hence, there were no compatibility tests between the different components before the components were deployed. The third and last phase of the process was the integration of the different components into an application. As expected, a number of interfacing problems and modularity problems arose. Below we will briefly touch upon them
- Dynamic Connection Management: a number of components offered a user interface that would connect to all cameras and obtain images from them. This in itself turned out to be tricky because the user interface component did not know where to look for cameras. To alleviate this problem we added a special connection-module that would keep track of newly created user interface components and connect them automatically to the available camera components. This component was called the controller and would, aside from managing dynamic connections also immediately deploy the application when starting. The current controller works by means of a declarative set of rules.
- Distribution: One of the problems we encountered was the fact that all components had been developed from a single user perspective, not taking distribution into account. To overcome this problem, the central connection broker had to be modified to place stub components on connections that would span multiple computers. The stub components were general purpose and did not have to be compiled specifically for every possible interface. Also, the components themselves did not need to be modified to make the whole infrastructure distributed. This clearly indicates a high level of modularity.
- Control flow: Another, non-anticipated problem was that the camera would generate images while the image-decoder would decode the raw binary data. Since both components were executing on their own piece of hardware, some flow control components had to be inserted to avoid a typical producer consumer problem. That is, the camera would produce images faster than the network could handle. To solve this problem we inserted a regulator on the sending side that would communicate with a regulator at the receiver side to agree on dropping a certain number of images. To avoid that the control messages should go through the congested communication channel we made use of a separate control-connection between both regulators.
11 Discussion
As observed during our experiments, the VICE component model allows for manageable modularity that can be efficiently implemented.
Modularity arises from the fact that components can only communicate by means of messages that are passed over communication channels. It is forbidden to share direct references between components and as such all modularity- problems arising from using direct references are avoided. The only direct references that are passed are the names of components. However, because these names are useless as long as no connection has been set up, these are relatively harmless to pass along. The only way the name of a component can be used afterward is by first setting up a connection toward the component. Since this operation can be intercepted we still have an adaptable, hence modular, architecture.
Manageability arises from the fact that all connection and creation requests are routed through a centrally placed channel. This is in contrast to meta-level architectures in which meta-objects (and their management) are scattered throughout an application. E.g; it would have been much more difficult to intercept a connection if two components could connect by immediately targeting the port address of the other component.
The model can be implemented efficiently because it does not offer a reified version of all operations. E.g; the sending and receiving of messages is not reified. The main advantage of doing so is that the performance penalty introduced by standard reflective architectures is strongly reduced. Directly communicating components will not pass their messages through a centrally placed meta-level. Nevertheless, the fact that these two operations cannot be modified does not mean that the message flow cannot be altered. If one wants to do so, the specific connection can still be altered in order to pass all messages through another component. Another performance boost can be found in the fact that it is no longer necessary to look at all messages transmitted by a component to modify the communication it has with one other component.
12 Conclusion
In this paper, we presented a reflective connection-oriented software model. The model avoids a number of problems that makes common software components not modular.
This research came forth from a number of observations. First, direct references complicate object-replacement and interception of incoming and outgoing messages. Second, undisciplined use of direct references enables hidden communication, which disables external adaptation. Third, meta-level programming merely shifts these problems to the meta-level and proves inadequate in managing different classes of meta-objects.
Based on these observations, we created a reflective software model that uses explicit connections. It offers a set of communication operations. A number of these (send_message, receive_message, ...) are decentralised and execute on the components themselves. Other operations (create_connection, create_component,...) are centralised in order to intuitively manage them. This approach reduces the performance penalty of full reflective systems to a minimum, while increasing the expressive power, manageability and modularity of the system.
As an example we used the problem of adding transparent computational replication to an application. Four universities validated this approach through working on a common test case.
Bibliography
- AGR83
- Adele Goldberg and Dave Robson.
Smalltalk-80: the Language.
Addison Wesley, 1983. - ALV92
- M. Aksit, L.Bergmans, and S. Vural.
An object oriented language-database integration model: The composition filters approach.
In Proceeding ECOOP'92, pages 372-395. Springer Verlag, LNCS 615, 1992. - AMST97
- Gul Agha, Ian A. Mason, Scott F. Smith, and
Carolyn L. Talcott.
A Foundation for Actor Computation.
Journal of Functional Programming, 7(1):1-72, 1997.
- AWB+93
- M. Aksit, K. Wakita, J. Bosh, L. Bergmans,
and A. Yonezawa.
Abstracting object interactions using composition filters.
In R. Guerraoui, O. Nierstrasz, and M. Riveill, editors, Object Based Distributed Processing, pages 152-184. Springer Verlag, LNCS, 1993. - BA01
- Lodewijk Bergmans and Mehmet Aksit.
Composing multiple concerns using composition filters.
Communications of the ACM, 44(10):51-57, October 2001. - BBCV99
- R. Behrens, G. Buntrock, C.Lecon, and V.Linnemann.
Is XML really enough ?
Technical Report A-99-11, Institut für Informationssysteme, Osterweide 8, 23562 Lübeck Medizinische Universität, Germany, 1999.
- Bel03
- Werner Van Belle.
Creation of an Intelligent Concurrency Adaptor in order to mediate the differences between conflicting concurency interfaces.
PhD thesis, Vrije Universiteit Brussel, Pleinlaan 2, 1050 Brussels, Belgium, 09 2003. - BTP96
- Pravin Bhagwat, Satish K. Tripathi, and Charles Perkins.
Network layer mobility: an architecture and survey.
IEEE Personal Communication, 3(3), June 1996. - Bug02
- Kristof Van Buggenhout.
Using a declarative language to support concurrency management in mobile multi agent systems.
Master's thesis, Vrije Universiteit Brussel, 2002. - BUOA
- Werner Van Belle and David Urting.
The Component System.
Technical Report 3.4 for the SEESCOA project, October 2000, http://www.cs.kuleuven.ac.be/cwis/research/distrinet/projects/SEESCOA. - BVD99
- Werner Van Belle, Karsten Verelst, and Theo D'Hondt.
Location Transparent Routing in Mobile Agent System - Merging Name Lookups with Routing.
In Proceedings Workshop on Future Trends of Distributed Computing Systems, volume 7, pages 207-212, http://borg.rave.org/, December 1999. IEEE Computer Society Press.
- Con01
- Pascal Constanza.
Dynamic object replacement and implementation-only classes.
2001. - CRS99
- A. Cohen, S. Rangarajan, and N. Singh.
Supporting transparent caching with standard proxy caches.
Proceedings of the 4th International Web Caching Workshop, 1999. - CWH01
- Mary Campione, Kathy Walrath, and Alison Huml.
The JAVA Tutorial.
The Sun Microsystems Press Java Series. 2001. - GHJV94
- Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides.
Design Patterns: Elements of Reusable Object Oriented Soft.
Addison Wesley, 1994. - Gra89
- Nicolas Graube.
Metaclass compatibility.
Proceedings of the 4th Conference on Object Oriented Proramming: Systems, Languages and Applications (OOPSLA'89), 24(10):305-316, October 1989. - GS00
- Peter Grogono and Markku Sakkinen.
Copying and comparing: Problems and solutions.
Lecture Notes In Computer Science, 1850:226+, 2000. - JGL98
- J.P.Briot, R. Guerraoui, and K.P. Lhr.
Concurrency and distribution in object oriented programming.
ACM Computer Surveys, 30(3), September 1998. - JNT+95
- J.C.Fabre, V. Nicomette, T.Perennou, R.J.Stroud, and Z.Wu.
Implementing fault tolerant applications using reflective object oriented programming.
Proceedings of FTCS-25 "Silver Jubilee", ACM Press, June 1995. - KGH+95
- D. Kung, Jerry Gao, Pei Hsia, Y. Toyoshima, and Chris
Chen.
Developing an object oriented software testing and maintanence environment.
Communications of the ACM, 38(10):75-87, Oct 1995. - KJAvR03
- Age Kvalnes, Dag Johansen, Audun Amesen, and Robbert van Renesse.
Vortex: an event-driven multiprocessor operating system supporting performance isolation.
Technical report, Universitetet i Tromso, Norway, June 2003. - KK95
- Alfons Kemper and Donald Kossmann.
Adaptable pointer swizzling strategies in object bases: Design, realization and quantitative analysis.
VLDB Journal, 4(3):519-566, July 1995. - KMP00
- E. Kohler, R. Morris, and M. Poletto.
Modular components for network address translation.
Technical report, MIT LCS Click Project, December 2000. - KW
- Sheetal V. Kakkad and Paul R. Wilson.
Address translation strategies in the texas persistent store. - LKRR92
- J. Lamping, G. Kiczales, L. Rodriguez, and
E. Ruf.
An architecture for an open compiler.
Proceedings of the International Workshop in Reflection and Meta-level architectures, pages 95-106, 1992. - Mae87
- Pattie Maes.
Concepts and experiments in computational reflection.
Proceedings of OOPSLA'87, ACM Press, pages 147-155, 1987. - McA95
- J. McAffer.
Meta-level programming with coda.
Proceedings of the 9th conference on Object-Oriented Programming (ECOOP'95), 952, 1995. - Mil99
- Robin Milner.
Communicating and Mobile Systems: the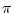 -calculus.
-calculus.
Cambridge University Press, May 1999.
- MMC95
- Philippe Mulet, Jacques Malenfant, and Pierre Cointe.
Towards a methodology for explicit composition of metaobjects.
Conference On Object Oriented Systems, pages 316-330, 1995. - Riv96a
- Fred Rivard.
A new smalltalk kernel allowing both explicit and implicit metaclass programming.
OOPSLA'96, 1996. - Riv96b
- Fred Rivard.
Smalltalk: a reflective language.
In Gregor Kickzales, editor, REFLECTION'96, pages 21-38, April 1996. - RJM+98
- Bert Robben, Wouter Joosen, Frank Matthijs, Bart Vanhaute, and
Pierre Verbaeten.
Building a meta-level Architecture for distributed Applications.
May 1998. - SEE99
- The SEESCOA Project Proposal.
http://www.cs.kuleuven.ac.be/cwis/research /distrinet/projects/SEESCOA, October 1999.
- SGP94
- Bran Selic, G. Gullekson, and P.T.Ward.
Real-Time Object Oriented Modelling.
John Wiley and Sons, Inc, 1994.
. - SJ01
- Nils P. Sudmann and Dag Johansen.
Supporting mobile agent applications using wrappers.
International Workshop on Internet Bots: Systems and Applications (INBOSA/DEXA'01), 2001. - Smi84
- B. C. Smith.
Reflection and semantics in lisp.
Proceedings of the 14th anual ACM symposium on Principles of Programming Languages, pages 23-35, January 1984. - Str98
- Bjarne Stroustrup.
The C++ Programming Language.
Adison Wesley, 1998. - T.91
- Tanaka T.
Actor reflection without meta-objects.
OOPS Messenger ACM Sigplan, 2(2):114, 4 1991. - TP01
- Eric Tanter and José Piquer.
Managing references upon object migration: Applying seperation of concerns.
Proceedings of the XIXI International Conference of the Chilean Computer Science Society (SCCS 2001), november 2001. - Ver02
- Pieter Verheyden.
Transparante Foutentolerantie voor Mobiele Multi-Agent Systemen.
Master's thesis, Vrije Universiteit Brussel (VUB), http://borg.rave.org/research.html, 2002.
- Wes98
- D. Wessels.
Squid internet object cache.
http://squid.nlanr.net/Squid/, January 1998. - WH92
- N. Wide and R. Huitt.
Maintenance support for object-oriented programs.
IEEE Transactions on Software Engineering, 18(12):1038-1044, December 1992. - WJ98
- Weyuker and Elaine J.
Testing component-based software: A cautionary tale.
IEEE Software, September/October 1998. - Wol89
- De Meuter Wolfgang.
The story of the simplest mop in the world -or- the scheme of object-orientation.
Prototype Based Programming, 1989. - Wu98
- Z. Wu.
Reflective java and a reflective component based transaction architecture.
In J.C.Fabre and S.Chiba, editors, Proceedings of the ACM, OOPLSA'98, workshop on Reflective Programming in Java and C++, October 1998. - Wyd01
- Bart Wydaeghe.
PacoSuite: Component Composition Based on Composition Patterns and Usage Scenarios.
PhD., November 2001.
", isbn = 1-55860-595-9. - Yok92
- Y. Yokote.
The apertos reflective operating system: The concepts and its implementation.
Proceedings of OOPSLA'92, ACM Press, 27:414-434, October 1992. - YT87
- Akinori Yonezawa and Mario Tokoro.
Object-Oriented Concurrent Programming.
Computer Science Series. The MIT Press, 1987.
Footnotes
- ... message1
- We assume that the language used offers basic features such as messageNotUnderstood in Smalltalk.
- ...2
- VICE has been developed during the SEESCOA [SEE99,BUOA] research project. It was funded by the IWT (Flemish institute for science and technology) and 6 industrial partners from 1999 till end 2003. The project itself was a cooperation between 4 universities: VUB, UG, KUL, LUC. The industrial partners were Phillips, Agfa Gevaert, Alcatel, Barco, Imec and Siemens.
- ...3
- This can be achieved by choosing a name that is unique to the creating component and then prefixing it with the creators name.
- ...4
- The later has proven to be 3 times faster than actually copying the messages.
| http://werner.yellowcouch.org/ werner@yellowcouch.org |  |