Next: I. Preliminaries Up: Contents Previous: General Glossary Contents
WITH THE ADVENT OF THE INTERNET, DISTRIBUTED SYSTEMS seem to have become an ubiquitous phenomenon. Ever more organizations that were are already present on the Internet with a website start to feel the need to extend the services they offer. These vary from simple scripting applications (making their website a little more intelligent and appealing to the end-user), to applications that are literally distributed and in which the cooperating nodes are technically equally powerful and thus abandon the traditional thin-client/fat-server point of view.
Unfortunately the construction of such distributed applications is far from trivial. Not only does one need to take into account the possibility of failures, all distributed systems are inherently concurrent systems. And the construction of concurrent systems is widely accepted to be an extremely delicate and complex problem. One of the complexities lies in the selection and correct realization of a suitable concurrency strategy in a certain context. Such a strategy is responsible for the correct cooperation of different concurrently operating components. The reason for the complexity stems from the fact that the actual concurrency strategy cannot be localized in one of the operating components but spans the entire application. Hence, the concurrency strategy is by definition an agreement between the concurrently operating components. Its implementation will thus leave traces in all those components. In other words, two strategies needs to be compatible or otherwise the software will not work. This problem is further aggravated in the context of open distributed systems, i.e. systems in which not all components are under control of the same entity, and for which the components' implementations have no control over each other.
The goal of this dissertation is to create an adaptor between the interfaces of components that are in essence compatible with each other, but fail to cooperate simply because of conflicts between the concurrency strategies they employ. Concurrency strategies are in conflict if one of the involved components fails to be alive and/or suffers from data races, i.e. concurrency that results in data corruption. The adaptor we will create is responsible for mediating the differences between the different concurrency interfaces in such a way that both components can communicate in a way that makes sense. Of course, the adaptor will not affect the core functionality of the components themselves.
In this dissertation, we will illustrate that creating such an intelligent concurrency adaptor is possible. Throughout the thesis it should be kept in mind that we will not be solving the inherent problems of distributed and concurrent systems. Instead they form the setting in which we conducted our research.
THE PROBLEM OF CONCURRENCY CONFLICTS outlined above is an instance of what one might generally call interface conflicts in distributed systems. With the current state of the art in connection technology these interface conflicts emerge in apparently different situations which together form the broader context of our work. In the sections to come we will outline the following three different points:
As explained before, the first context for the problem consists of the inherent absence of standards in the world of open distributed systems. The word 'inherent' in the preceding phrase was chosen deliberately. In what follows, we will argue that, in the market driven world in which companies relentlessly compete to make their market position more stable and larger, there cannot be one standard used by everybody. As a consequence companies have a strategic advantage if they can resolve the problem of conflicting standards quickly.
Before 'proving' these statements, let us first explain what we mean exactly by the term 'open distributed system'. A distributed system is a system which consists of two or more computers that are connected to each other by means of a network. Two computers connected with a serial cable in the same room is as much a distributed system as are computers connected via satellites in different parts of the world. Distributed systems can be either open or closed. Open distributed systems are systems made of components that may be obtained from a number of different sources which work together as a single distributed system. These systems are basically ``open'' in terms of their topology, platform and evolution: they run on networks which are continuously changing and expanding, they are built on top of a heterogeneous platform of hardware and software pieces, and their requirements are continuously evolving[MW99,Kie96,Cro96,CD99]. The Internet is the best example of an open distributed system, because no end user, or company knows the interconnection of all the computers on the Internet. The Internet interconnects different companies as well as end-users by means of an unknown network.
Programming open distributed systems is difficult... not only because the field is relatively new, but mainly because such systems highly depend on many external factors. Not the least important of these is the market behavior of mutually competing middleware providers. Being dependent on their products, one has to anticipate what they are planning to do, and possibly change one's behavior accordingly. If the providers are planning to drop support for a certain standard, one can no longer rely on that standard and might need to look for other solutions. This is nothing new, but for open distributed systems this highly increases the costs of evolution maintenance. Components that exist and are currently widely accepted can be invalid tomorrow. Everything, including the operating environment (that is, the Internet) is so unreliable that writing distributed programs is sometimes said to be nothing more than making some educated guesses about what will happen and what will not happen. [OHE96,Sel01]
The problem of conflicting interfaces cannot be solved by 'requiring' that everybody follows the same standard. Standards evolve not only as a consequence of technological innovation but also as a consequence of the market behavior of the companies behind it. An example of this is the 'evolving' web technology. E.g., whenever companies serve data on the web they are among others dependent on the W3C HTML standard for describing the content of their data. This turns out to be a problem in itself, because this widely used standard is interpreted and augmented in many different ways: Mosaic, Netscape Navigator, Microsoft Internet Explorer, Opera, Konqueror, Mozilla each have their way to understand and render webpages. Surely, one of the reasons behind this diversification comes from the fact that the standard was not very well defined in the eighties. So, the standard needed to grow, which it did. However it did not become a better standard. Instead, different companies tried to redefine the standard to enlarge their market-shares by 'adopting' this standard and modifying it as necessary. One of them was Microsoft. Around 1995 Microsoft was a large player in the operating system market and had the resources to push its own modified standard [BL01] by a) bundling its browser with its operating system, b) not releasing its API's to its competitors Netscape, c) creating components which only worked with its own browser (ASP) and d) creating interpreters that only worked for programs written with its tools (Java versus J++). From these 4 techniques, the last three are centered around the use of standards. Techniques likes this are not exclusively used by Microsoft, which illustrates sufficiently how different standards are defined and molded through the interaction of different companies. Standards are subject to considerations other than the ones involved with the standard. Therefore there cannot be one single standard.
As explained above, there cannot be one standard, especially not in an open distributed system. Therefore, companies that develop open distributed applications and that involuntarily depend on all kinds of middleware to do so, spend a lot of resources on maintaining their application(s) in a very volatile environment. If only such a company would have the ability to solve the problem of conflicting interfaces in an automatic way, it would have a strategic advantage compared to others. This concludes the first position to illustrate the need for automatic adaptors between conflicting interfaces.
A number of academic groups try to foresee what the Internet will be like in 10 years. One such research track led to the concept of mobile multi agents. Originally these were conceived as intelligent agents [CDGM97] (as defined by Pattie Maes) which would assist the user with some daily tedious tasks such as sorting email in order of interest, looking over his shoulders and assisting where it deems necessary (Microsoft Clippy), bringing people with the same interests together, and performing other intelligent tasks.
As it turned out, to the contrary of what was predicted, intelligent agents currently do not roam the web in search for information, nor do they bring users in contact with interesting opportunities. Writing intelligent agents requires a lot more than writing simple programs, because much of the necessary infrastructure is missing. Such an infrastructure would connect all computers with each other in a non strict hierarchical way. Every single computer would run a mobile multi agent system, which would ensure basic operations for the agents. Agents would be able to communicate with each other and migrate to other computers as necessary. In such a peer to peer world, computation would emerge from the interaction between the agents, and not only in the agents themselves. The Internet would become a large universal computer [FDF03], where resources are shared and used as needed. Instead of buying software, users would subscribe to software, completely ignoring where the software runs. Such applications would consist of a large number of interacting agents, which are not necessarily written by the same company. Users could have their personal intelligent agent on-line, which could schedule meetings with other intelligent agents. Such agents would learn the preferences of their users and search the net for information within that context. They could be able to book airplanes and plan travel-routes. And when the user travels to the other end of the world, the intelligent agent would follow him, together with his preferences. This agent would take care of recreating his virtual environment, wherever the user goes.
However, from a technical point of view, implementing such agents is often still very difficult. One of the reasons is that in general global peer to peer computational networks are extremely volatile. Aside from the problems of finding communication partners (how does a text editor find a suitable printer in a new environment), and the problems of partial failure (what should happen if the agent dies), we have even bigger problems when interfacing the different agents. Let us e.g. assume that a running agent wants to interface with a printer. All printers will provide a different API. Some printers will require one to take a ticket and will call the originator back with a request to send data. Other printers will redirect one to a printer spooler and yet others might require one to lock them first. It is clear that a programmer will never be able to foresee all such printer-interfaces. Even in cases where it is possible to foresee and program all currently available interfaces, it is still impossible to support every possible future change. Indeed, by the time one releases an agent, somebody will probably have written another implementation of the interface, or updated an interface to offer a slightly different implementation. This can happen because this agent, with its new implementation of this interface, needs to run on different (possibly optimized) hardware, or because the operating system is different, or simply because the agent is part of another application, and thus developed by other programmers.
In a global peer to peer environment with billions of users, API's change faster than programmers can write. Every extra assumption made by a programmer about an API increases the chance of failure at some time in the future. Hence programmers cannot exhaustively support every possible interface one might encounter in this volatile setting. Instead, a minimal support for some prototypical interfaces will have to be provided under the assumption that the running agent will be able to adapt its interface automatically and dynamically.
The main reason why adaptors are necessary within mobile agent systems is that migration itself leads to situations where the communication partners' implementations are unknown. They can offer the same API, but the implementation itself will give rise to subtle semantic differences that might lead to incorrect behavior. In section 1.3, after presenting the thesis statement, we will discuss in more detail an example of such semantic differences.
As embedded systems become more powerful and new demands are created, the wireless interconnection of different embedded systems is unavoidable. Indeed, it can be expected that, in the near future, technologies such as bluetooth and wireless Ethernet (IEEE 802.11) will lead to an ever further integration of domotics, PDA's, cellular phones and so on. This is referred to as interconnected embedded systems [DBS+01]. This evolution will bring about new conflicts since one no longer knows what the neighboring embedded system will be (is it a television or is it another cellular phone we just happened to detect ?). Anticipating all potentially encountered interfaces is simply impossible.
As explained in [BK01] conflicts arise not only because the interfaces are different, but also because the burden of extra non-functional requirements is all too often neglected. Many of the problems involved with embedded systems come from the requirement to do as much as possible with as little resources as possible. This of course depends on the market for which the embedded systems are made. Consumer devices such as remote controls and mobile phones are under much more pressure to reduce the hardware requirements than mid-scale and large-scale embedded systems such as routers and set-top boxes. Requirements such as real-time requirements (the device should be able to guarantee certain deadlines), speed requirements (the device should be able to deliver a certain bandwidth), memory requirements (the device should be able to work with a limited amount of memory), size requirements (the device should be not larger than ...) and other non-functional requirements lead programmers to re-engineer their software, make it smaller and/or more efficient. This often results in behavioral changes within the software. One such a conflict could for instance arise from the modification of counting semaphores to binary semaphores, simply to reduce the memory requirements.
Essentially, the problems are similar to the ones found in mobile multi agent systems. However the difference between interconnected embedded systems and the agent systems discussed above, is that migration from one environment to another is physical migration of the device, instead of migration of the software only, resulting in a very volatile environment in which a developer cannot exhaustively support every possible interface one might encounter.
This wraps up the third motivation that illustrates the need for automatic adaptors between conflicting interfaces. The three contexts outlined above are the three reasons why we investigated the problem of conflicting interfaces.
BEFORE GIVING AN OVERVIEW OF THE CONTENT OF OUR WORK in the following section, let us first shed some light on the methodological side. First we will propose the thesis statement. Second we will clarify our scientific methodology and validation strategy.
As explained in section 1.1.1 companies are currently faced with the problem of linking to all kinds of frequently changing third party interfaces and, as seen in section 1.1.2 and 1.1.3, with the advent of open peer to peer networks and interconnected embedded devices, this problem will become even worse because interface conflicts will occur more frequently. Solving such interface conflicts is generally done by inserting adaptors at the appropriate places. However, in very volatile environments creating such adaptors manually & marketing them might be very expensive. Therefore we will investigate how one can create intelligent adaptors that adapt their behavior when new interfaces are encountered. This intelligent adaptor should be able to learn how to resolve interface conflicts in such a way that a) the required behavior of the involved components can be executed over the adapted interconnection and b) the adaptor is able to work on-line in an open system. With on-line we aim at the penalty involved when making an error. In an on-line setting, every wrong decision (that possibly brings an entire application down) is far more catastrophic than the same decision in an off-line setting. This can be because end-users have started the application and are waiting for something to happen, or because a wrong behavior has indirectly an indirect impact on end-users because it introduces and invalid state within the application. It is clear that an on-line setting is far more delicate than an off-line setting.
In the following sections we will explain which methodology we will use to validate this claim and which case we will use throughout the dissertation.
Regretfully, a lot of research in the context of open distributed systems and peer to peer networks is based on unrealistic assumptions, such as `the Internet is fully interconnected' or 'latency will be neglected for the sake of the argument'. During the course of our work we have been constantly taking heed not to make such assumptions. Hence, the methodology used throughout this work is to take into account the boundaries imposed by open distributed systems, such as high latencies, low speeds and unreliable networks. It is within those boundaries that we have tried to create an intelligent interface adaptor.
To construct the intelligent adaptor we tried to use deterministic reasoning algorithms as much as possible. However, when these were not available (because of intractability), or inadequate (because of NP-completeness or worse) we used learning algorithms with 'less certain' outcome. However, a plethora of learning algorithms exist, each with their own characteristics and prototypical problems and/or solutions. Therefore we had to find out which are suitable ones and which are not. As such, we investigated the use of genetic algorithms, genetic programming, neural networks, reinforcement learning and a lot of variations on them. As we will demonstrate in the dissertation, it turns out that they can be useful if used in the correct context and modified accordingly. E.g., in our experiments we noticed that, although some forms of genetic algorithms in theory are perfectly applicable, their practical deployment in the context of open distributed systems was extremely limited because of their off-line nature.
To validate our thesis statement practically, we have selected a particular case for which we show how to create an intelligent interface adaptor, namely an interface adaptors to solve concurrency conflicts. It is in the context outlined above, that we have empirically validated which algorithms were practically feasible, based on certain requirements, in order to overcome unanticipated concurrency conflicts of two or more communicating components.
When two or more components interact concurrently, essentially two kinds of problems can occur which we might call functional conflicts and non-functional conflicts. Functional conflicts emerge when the interacting components are speaking a different language with regard to their functionality. E.g. one component might be 'about' booking flights and another might be 'about' reserving library books. Clearly the interfaces of these components are completely incompatible and it is not the goal of our work to do something about it. Non-functional conflicts emerge when the components are essentially speaking about the same thing, but in a different way. Examples of non-functional problems are concurrency problems such as race-conditions, deadlocks, livelocks, starvation and others. These typically occur when the order in the message interaction is wrong. To solve these problems every participating party implements a so-called concurrency strategy. However, when different concurrency strategies do not cooperate in the right way, a conflict arises. Having stated this, we can now repeat the thesis statement given in section 1.2.1 in its full context.
It is possible to create, for certain categories of concurrency interface conflicts, a concurrency-adaptor that learns how to resolve the conflict in such a way that a) the required behavior of the involved components can be executed over the adapted interconnection and b) it is able to work on-line in certain categories of open system. We validate this by constructing such a concurrency-adaptor.
IN THIS SECTION WE INTRODUCE a preliminary example of the problem we will investigate. In particular this example concerns a concurrency conflict between a client and a server. After presenting the example, we will discuss what we consider to be a conflict and what requirements we pose upon an adaptor. Throughout this section we will give forward references to those chapters that discus the matter in more detail.
For clarity, we assume that the only way through which the state and/or behavior of a component can be altered is through one of its access points. Such an access point (or group of access points) will be called an interface. (See chapter 2). Below we describe the interfaces of our two example components by means of incoming and outgoing messages with some extra non-formal documentation.
The server is a whiteboard that allows multiple clients to lock certain position before they can act upon these position.
The server's API:
The server component also offers some behavior on another port. This behavior is as simple as possible.
The API of the client component:
incoming lock(x, y, result)
// lock(*, *, true) or lock(*, *, false) are received whenever a
// lock request comes in. Before performing an act operation the
// server will be locked by sending out a lock.
outgoing unlock(x, y)
// will unlock the resource. No message is returned.
// This operation always succeeds.
incoming act_done(x, y)
// will perform some action on the server
If we look at both interfaces, we see immediately 2 essential differences between the client and the server. First, whenever the client requests a lock there will occur a syntactical conflict: the client expects the server to return a lock(x, y,result) message, while the server will return a lock_true or lock_false message. A second similar conflict can be found when looking at the unlock operation. The client will only send out an unlock request, while the server will send back an unlock_done message. This message will not be understood.
To solve this problem one can easily insert an adaptor between both communicating components. This adaptor will offer two interfaces: one interface aimed at the server side, another interface aimed at the client side:
outgoing lock(x, y)
// when a client requests a lock, this lock will be sent
// through to the server
incoming lock_true(x, y)
incoming lock_false(x, y)
outgoing lock(x, y, result)
// when the server responds with lock_true this request will
// be translated towards the client as lock(x, y,true).
// When the server response with lock_false this request will
// be translated towards the client as lock(x, y,false).
incoming unlock(x, y)
outgoing unlock(x, y)
incoming unlock_done(x, y)
// when a client requests an unlock, this message will be
// forwarded to the server when an unlock_done() message
// arrives from the server this message will be silently ignored
incoming act(x, y)
outgoing act(x, y)
incoming act_done(x, y)
outgoing act_done(x, y)
// similarly, the action request will be translated by simply
// passing any act or act_done message.
Aside from the syntactical conflicts between both interfaces, that in this case, can be easy mediated, semantic differences can also occur. The documentation does not state how the components implement their locking strategy. For instance, one can implement a counting semaphore or a binary semaphore as a concurrency strategy.
![\includegraphics[%
height=6cm]{SimpleConflict.eps}](img22.png)
|
In the above example we gave an example of a conflict between a counting semaphore and a binary semaphore. However, this conflict only pops up when the client makes use of certain possibilities hidden within the semantics. Specifically, the client needs to decrease a lock-counter, without bringing it to zero and then act upon the supposedly locked resource. A behavior such as this is not necessarily present within the client component. A client component might also simply lock a resource multiple times and then unlock it again until the lock-counter reaches zero. If the client behaves as this, we can barely say that there is a conflict between the two interfaces (aside from the obvious syntactical conflict).
In other words, depending on the behavior of the involved components, a possible conflict might be a real conflict or not. This leads us to define an interface conflict in terms of the required behavior:
If the overall required behavior of a set of components cannot be executed by only using the interfaces between the different components then the interfaces of these components are in conflict.
This definition should be clarified to a certain extent. We mention 'the overall required' behavior. This implicitly means that we assume that all the involved components have agreed to follow a certain behavior. For instance, if all component agree to not follow a concurrency strategy then we cannot say that the previously mentioned interfaces are in conflict. If both components have agreed to follow a locking strategy then we can declare the interfaces to be in conflict. However, if not all components agree to follow a certain behavior then this definition of interface-conflicts is useless because it will be virtually impossible to resolve the conflict. E.g.: if the server requires a concurrency strategy but the client does not agree to follow any concurrency strategy at all, then the notion of an interface-conflict is useless because it cannot be measured against a required overall behavior.
In this dissertation we will assume that the involved components have already agreed to provide/require a similar behavior. In chapter To better understand the kind of conflicts we are dealing with we will discuss different concurrency strategies and define an implicitly agreed overall behavior in chapter 5. After doing so, we will investigate in chapter 6 the conflicts that can arise in such a situation.
To verify whether it is possible to generate an intelligent adaptor we need to specify the requirements for such an adaptor. Below we present the requirements which an adaptor should satisfy. In chapter 7 we will do this in detail for the concurrency-adaptor.
Given the definition of interface conflicts, together with the notion of overall required behavior we can easily understand that an adaptor works when it is
The reason why we require the adaptor to work at runtime is mainly because this embodies a more realistic approach. In open distributed systems, one component might suddenly need to talk to a previously unknown component. If the adaptor is able to work and mediate conflicts at runtime, then it will also be able to learn how to behave when such a new communication partner is encountered in an open system. however, if the adaptor is only able to learn a suitable behavior off-line, then it might not be possible to adapt correctly in a running open system.
The reason why we only want to modify the message flow between the components is because in an open system it might not always be possible to modify the source of the involved components. Therefore, the only thing that such an adaptor can be allowed is modifying the message flow between the different components.
The high-level definition of interfaces, conflicts and the requirements given in this section can also be found in [VHT00].
AS WE WILL DEMONSTRATE IN THE DISSERTATION, the technical characteristics of the reasoning algorithms and the learning algorithms we experimented with, lead us to formulate every adaptor as a suite of three cooperating modules. The basic idea is that a concurrency conflict interface adaptor will consist of one 'central' module that contains the actual solution for the concurrency conflict; together with two peripheral modules whose task is to mediate between a component and the central module in some way. In the following sections, will elaborate on the requirements we impose on the developer of the interacting components in order to facilitate the construction of the mediating modules. Furthermore we will shed some light on their functionality and on the reasoning and learning algorithms we adopted in order to construct them.
We will now briefly sketch how an intelligent adaptor can be constructed. This adaptor will be placed centrally between all communicating components. To a certain extent this is contradictory to the motivation of open distributed systems. However, without the ability to intercept all communication it is often impossible to solve concurrency conflicts between multiple partners. We will come back on this issue in section 12.7.1 and in section 6.4 where we will discuss possible solutions to this.
As explained, the adaptor will learn how to mediate conflicting concurrency strategies between running components. Typically this will be achieved by trying out different actions within different situations and learning which action is appropriate at what moment in the message sequence of those components. However, this learning-phase also happens at runtime, so the adaptor must be sure that no chosen action interferes with the correct working of the application. This forms a general problem because an adaptor does not have this knowledge available. Therefore we will require that all components offer a full formal documentation of their interfaces. This formal documentation will be under the form of colored Petri-nets and statically placed checkpoints within the source code (the yellow boxes 2a and 2b in figure 1.2). We will further elaborate on the documentation in section 1.4.5. With the availability of this documentation, an adaptor can readily experiment in a runtime system with the assurance that no chosen action will corrupt one of the running components.
As already stated, the adaptor itself (depicted as the central white box in the green box in figure 1.2) is a chain of three smaller connected modules (the blue boxes 3a, 3b and 3c in figure 1.2), each responsible for a different role in adapting the concurrency conflicts that might exist when one component tries to communicate with another through non-compatible interfaces. A component that initiates a communication uses a certain required concurrency strategy in order to communicate with the second component, which offers a provided concurrency strategy. In general the idea is that the different concurrency strategies will be converted to an intermediate protocol which will be used to order incoming functional requests.
The enforce-action module (blue box 3b in figure 1.2) will automatically bypass the provided concurrency strategy. This is done by analyzing the possible future traces and finding out how certain actions (or states) can be enforced upon the component. The formal analysis we use to bypass the concurrency strategy is done by means of a prolog program and requires a formal documentation of the provided concurrency strategy. (yellow box 2b in figure 1.2). Bypassing a concurrency strategy is of course a dangerous thing to do because race conditions can happen from then on. To avoid these race conditions, all communication with the bypassed component should henceforth go through the concurrency adaptor. In chapter 8 we explain how we do this.
The liveness module (blue box 3a in figure 1.2) will automatically learn what kind of messages the required concurrency strategy would like to receive back at a certain moment during the communication. To illustrate this, one can easily see that a component would like to receive back a LockTrue message when it requests a lock. A LockFalse would also be possible of course, but it is clear that in this case, this is not the answer that is favored by the component. As we will explain in chapter 9 learning this required behavior is done by means of reinforcement learning (Q-learning more specifically). The answer favored by the component is used to create a suitable reward/punishment for this learning algorithm. Of course, the algorithm itself cannot determine the favored answer such that we will have to rely on the developer to specify this. As we will show in section 9.2, this is done by means of checkpointing the source (yellow box 2a in figure 1.2).
The concurrency module (blue box 3c in figure 1.2) is placed in between the liveness module and the enforce-action module (hence, between the required and provided concurrency strategies). As explained before, this central module contains the 'actual' concurrency strategy used between the components adapted by the other modules. The specific concurrency strategy plugged into this module is actually outside the scope of our work: it can be any strategy of choice which works well in the particular environment in which our techniques will be deployed in. These contents of the module can thus be taken from a repository of 'good working concurrency strategies' or can be a learning concurrency strategy that learns how to optimize the locking strategy to avoid rollbacks and livelocks. In chapter 10 we will elaborate further on the possibilities of filling up this module.
In section 1.4.1 we explained that the reasoning and learning algorithms we used to make a working interface adaptor, are based on formal documentation that has to be provided by the programmer of the communicating components. More concretely, in the realization of the above three modules, we relied on extra input, supplied by the programmer of the required and provided concurrency strategies: he has to specify when his component is 'alive' and he has to document the interface in a formal way. The formal documentation we use are so-called colored petri-nets [Jen94,Lak94,KCJ98,EK98]. This formalism is suited for specifying which actions are enabled at some moment in time, and, has some additional properties that are both highly favored by human readers, and are well-suited for automatic interpretation by algorithms:
IN CONTRAST TO PHYSICS, CHEMISTRY AND OTHER DISCIPLINES, computer science often lacks an objective and fixed scientific method. The non formal characteristics of many problems often leads to a lack of investigation depth and rigor. Furthermore, given the current possibilities of computers, it is very easy to create layers of abstraction upon layers of abstraction, often without having the scientific yardsticks to verify their value and how they contribute to the progress of the field. According to [MSBW94] there are three possible things one can contribute in the field of experimental computer science.
This dissertation makes no claim whatsoever about performance. Solely for the interested reader some performance estimates are given, but these should be read as purely informative.
The research presented in this dissertation, as well as the research that leads to this dissertation has been reported on internationally:
THE MOTIVATION THAT LEAD TO THIS RESEARCH has also motivated other researchers to investigate similar problems. In this section we discuss similar approaches such as adaptor generation by means of state machines and adaptor repositories. Afterwards we discuss alternative approaches such as languages for writing adaptors, fundamental problems of open protocols, ontologies and others. Related work that is technically relevant will be discussed when appropriate. Section 3.3.1 discuses alternative approaches to Petri-nets. With respect to the problem of conflicting concurrency strategies there is, to the best of my knowledge, nothing to be found.
In this approach an adaptor is considered to be a program that is generated when a description of the different interfaces is known. To make the required behavior executable over the conflicting interfaces, a lot of research focuses around the generation of finite automata. The work of [Wyd01,Reu] covers how such an automata-adaptor can be generated. The work itself is aimed at the composition of software components in closed systems. The strategy used relies on the availability of place-holders that abstractly describe what kind of interaction is required, while an finite state machine (written down as an MSC) describes the behavior of the interfaces themselves. In our work we have actively sought for an example where such place-holders cannot be written easily, i.e., where the requirements cannot easily be expressed as a finite state machine. We believe concurrency is such an example because a requirement such as 'no race conditions should occur' is difficult to write down as a finite state machine. The work of [Wyd01] also relies on the availability of a learning algorithm, however not much detail has been given on this algorithm. This kind of approach also has the problem of 'non-symbolic operation', which means that the finite state machines cannot express actions on arguments, such as 'add those two arguments together and pass it through'. In short, finite state machines are limited in their expressive power.
Another approach relies on a repository of adaptors that ought to work in a certain application domain. Creating such adaptors is done off-line whenever a conflict arises. For every occurring conflict one can develop an adaptor manually. The strength of this approach is that a) a better quality control can be enforced upon the entire adaptation process, b) there virtually no limitations are on the requirements posed upon the adaptors because they are manually written and c) in the name of efficiency, only real occurring conflicts will be solved. The biggest limitations of such techniques are their scalability. On one side, for every new component there exist potentially as many conflicts as there exist other components. This means that the number of adaptors might be quadratic to the number of components. By defining a common ground on which adaptors can be written, thus by exploiting domain specific features, one might be able to reduce the problems of managing this growth.
The biggest reason why we didn't investigate this track further is because it is more a process towards a solution than a solution in itself. Nowadays, companies such as IBM are selling 'integration' and are efficiently creating adaptors by relying on domain specific features.
In this section we cover research that uses another approach than the one we have created.
The idea of creating self-adapting protocols is certainly not new. Open protocols are protocols which optimize the communication themselves by modifying the protocol they are using at runtime. However, research done by Vreeswijk [Vre95] shows that in general it is impossible to create a fully open protocol. Certain restrictions will always be in place. In our dissertation this is also the case. We had to make assumptions that limit the applicability of our work to the field of concurrency problems and open distributed systems. Other research approaches the problem of conflicting interfaces more philosophically by testing the boundaries and possibilities offered by open protocols. The Talking Heads experiments is one such an experiment. Here robots learns the 'meaning' of words by communicating about similar objects [SKML].
An alternative approach towards interface conflicts is to avoid them. By carefully tagging different components with a version-number one might be able to reduce a large number of unanticipated conflicts. Instead of using any component available to offer a certain functionality, it becomes possible to select the correct version of a component. However, this does not solve the problem, it only manages it better. After a while, different versions will be working together, thus not necessarily avoiding conflicts. Software evolution research has pointed out that seemingly harmless upgrades to software implementations may result in unanticipated behavior within other parts of the system [LSMD96]. An explicit example of this is given in this dissertation in section 6.1.1.
With respect to versioning, [WMC01] discusses a number of different tools and approaches toward the software versioning problem. The paper itself present a unified approach towards versioning. [Sug98] discusses what kind of extensions should be added to .DLL's to make runtime upgrades possible.
From a practical point of view, ontologies [Gru93] try to describe information contained within a system. The representations of this information can be different from system to system. Some research groups investigate how this information can be exchanged between different systems. One such an example is the 'knowledge interchange format', or KIF [GF93]. Nowadays, KIF is being mapped onto XML [ES] such that the use of a DTD can help in interchanging data in real-world environments. However, this kind of approach typically does not allow for active processes. [CP95] covers an agent based ontology approach to integrate different applications with each other. [NU97] argues that the availability of a communication channel over which agents communicate over the language they are speaking is essential together with the availability of a shared ontology.
Another approach to the problem of conflicting interfaces is the creation of a language in which one can easily express how the adaptor should work.This approach is taken by Picolla [ALSN01], CSP [Hoa85], which is specifically suited for concurrency. Other approaches handle the problem of conflicting interfaces by investigating how interface conflicts can be avoided by offering a type system that allows for 'open' communication [GK99,JB99] and others. [JB99] also explains why standard object oriented language constructs do not easily allow for easy adaptor creation. KQML [FFMM94] is a language that is designed to allow agents to share and communicate information with each other. [CFL+99] presents a system that uses KQML and Java as an underlying language to write adaptors between conflicting components within enterprises. [BBT01,BBC] discusses a language to coordinate the interaction between different components. Its language is mainly based upon CSP.
In this dissertation we have investigated in what kind of language our adaptor should be written. However, instead of creating (or using) a human accessible language, we have been looking for a language that is better suited for automatic generation by means of computers.
THE ORIGINAL GOAL OF THIS DISSERTATION, which is to create an intelligent adaptor between conflicting interfaces, represents a very difficult problem. Therefore we have tried to get a grip on it by choosing appropriate techniques and identifying important subproblems. Once a problem was identified we have restricted ourselves to it. During our work we have always tried to minimize the number of restrictions and have tried to keep the solutions as general as possible. However, before we were able to create a concurrency adaptor we have tried a number of different paths to tackle the problems involved. The path we have followed is as interesting as the solution itself. Therefore we have tried to retain as much information as possible, such that, if an intelligent adaptor needs to be developed for other domains, this dissertation can be used as a guide. To help the reader in understanding the structure of this work, we will now summarize the path we have taken. Note that this path is in chronological order and not in the order of chapters.
However, the presentation of this research has been molded into a standard format, resulting in a text which is divided into four parts: I) preliminaries, II) the case, III) our approach and IV) validation. Part I, the preliminaries covers the event based model we use (chapter 2), explains how Petri-nets can be used to describe interfaces (chapter 3) and introduces the learning algorithms we need later on (chapter 4). The presentation of our cases (part II) covers two chapters. Chapter 5 explains which concurrency strategies we investigate, chapter 6 contains the conflicts we use. The presentation of our approach (part III) starts with presenting a general overview of the solution in chapter 7, after which the different modules are presented in chapters 8, 9 and 10. The last part of this dissertation (part IV), validates our initial claims. We will not only verify the working of our adaptor in chapter 12 and conclude our thesis in chapter 13, but we will also give an overview of the preliminary experiments that have lead to the current setup of the adaptor (chapter 11). Figure 1.3 shows the dependencies between the different chapters.
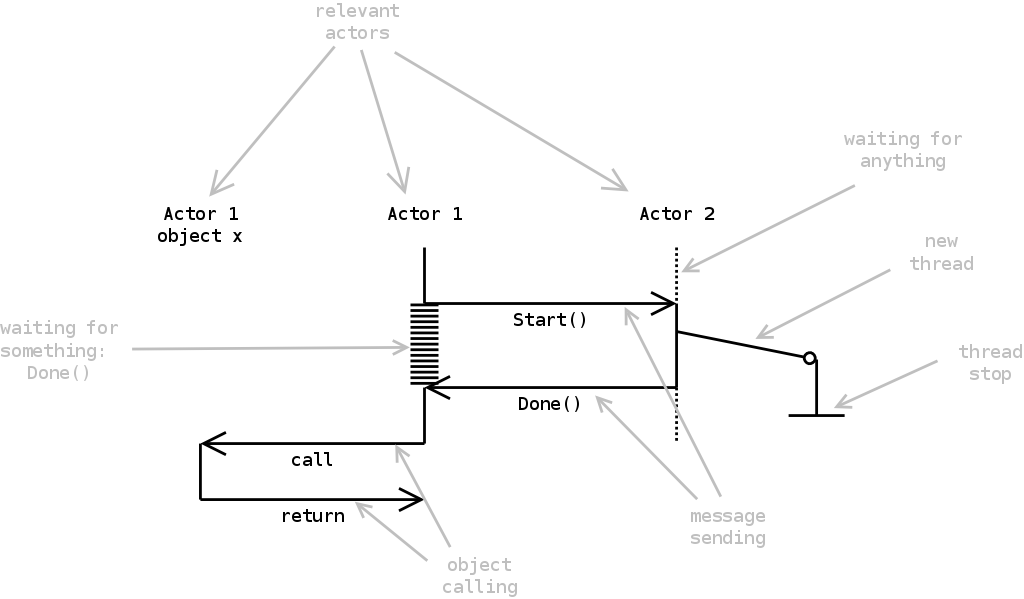
We will make use of a sort of message sequence diagram. The message diagrams are loosely based upon UML, with the difference that we have added some notation to support different threads and better illustrate concurrency problems. Figure 1.4 contains a message sequence chart in which we explain the different notations used:
![\includegraphics[%
width=1.0\textwidth]{Overview.eps}](img23.png)
![\includegraphics[%
width=1.0\textwidth]{Roadmap.eps}](img24.png)