Next: Bibliography Up: IV. Validation Previous: 13. Conclusions Contents
JAVA WAS ORIGINALLY CONCEIVED BY SUN MIRCOSYSTEMS to be used on embedded systems. However, it turned out to be a better language for the Internet because it offered a virtual machine that could run Java applications on all kinds of different architectures. Java is an object oriented programming language that supports automated memory management (= garbage collection), threads, and interfaces. Libraries like Java RMI (remote method invocation) are available to support semi transparent remote accessibility. This model, a typical thread based, transparent distribution model, is the focus of this appendix. We will investigate the suitability of Java and its thread based model for writing adaptors. This chapter explains why we opted for an event based model. It gives also isnight into the problems of creating adaptors for such models.
THE FIRST THING EVERY distributed application has to do before connecting a remote object, is looking up what object it should connect to. For this purpose Java RMI uses a special server which should be started on the machine where remote objects will be exported. This server is called the RMI registry.
If an object wants to export itself it can use the Naming class to export its own name to the registry. From then on all applications can ask the registry a reference for the object with that name.
It is clear that such a mechanism is very rudimentary, because we still need to know the name of the machine where the registry (and the objects as such) are running. To support new technologies, such as wireless embedded devices, Sun developed JINI, which allows peers (clients) to look up other peers (servers) using a description of the required capabilities, instead of a simple name. The initial lookup to find a JINI directory server is done with a broadcast.
JAVA PROCESSES can communicate by using Java RMI. Note that Java RMI can only communicate between Java Processes, which is a major drawback of RMI.
Sun's serialization and deserialization interface to Java [CFKL91] helps with exporting an object graph to a byte stream. The standard behavior for serialization is to serialize the object and all the objects it contains. If we want to modify this behavior we have to implement an externalizable interface which describes how the object is to be exported.
To be able to contact a remote object, as if it were a local object, one should create stubs for all the remote objects which will be contacted.14.1 Such a stub will implement all the methods the remote object supports and filling in the bodies with code which contacts the remote object. The logic of such a stub body is quite simple:
ANOTHER POINT TO MAKE with respect to stubs and skeletons is that they are generated by a compiler, called rmic. This means that stubs and skeletons are created at compile time. As a direct consequence we cannot easily communicate with an unknown process at runtime. In the setting of this dissertation, this is not acceptable because we don't know the interface we will link to.
One could think of a solution by creating stubs and skeletons as needed: any time a connection to another machine is needed, the interface description could be downloaded from the server and compiled into a stub class that would connect to the appropriate skeleton at the server. This compilation phase would require a compiler or Java byte code assembler, and would consume a lot of time for simply setting up a link to a remote object. It is clear that this is not practical and not a good approach at all.
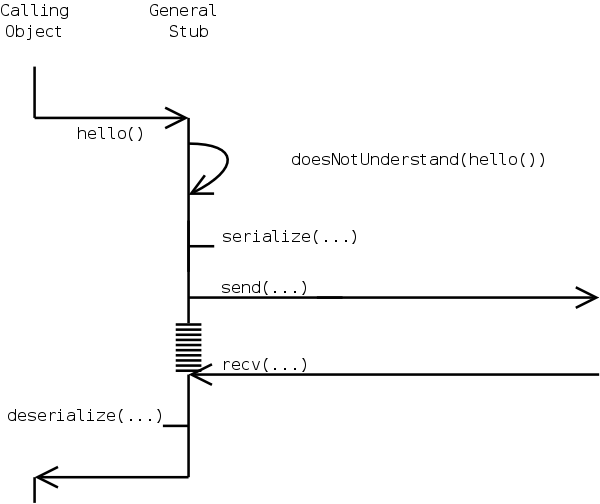
Another approach, as used by Smalltalk [AGR83] users, is using the meta-level interface and overriding a method such as doesNotUnderstand. With this a simple and general stub could be created. The only method of the stub would be the doesNotUnderstand. This method would be called every time an undeclared method is invoked upon the object as can be seen in figure 8. The doesNotUnderstand in turn would look at the actual method invocation and pass it along to the skeleton. However, as it turns out, this is impossible with Java because the meta-level interface of Java is not strong enough.
IN MANY ASPECTS JAVA is an innovating language. One of these innovations is the introduction of a standard threading library.14.2 A thread is an execution context which can run together with other threads in the same environment. The difference with processes is that threads do share memory, while processes don't share memory.
The availability of threads in Java is of crucial importance for the
internal workings of Java RMI as we will explain now. Java RMI, as
already seen, waits before returning an answer: a client can ask the
server to execute a method and return the answer. In the meantime
the client simply waits. Now, let's have a look at the Java program
in algorithm 27 (page ![[*]](crossref.png) ).
).
The FacApp class exports a FacCalcer interface. A FacCalcer is an object that calculates the factorial of a certain number by performing a recursive call. To do the recursive call the FacCalcer needs to receive another FacCalcer as can be seen in the definition of the fac method. When such a FacCalcer starts, it either becomes the master FacCalcer (by binding itself in the registry) or a slave FacCalcer, which will initiate the calculation of a factorial.
To start this program, first an rmiregistry should be running and afterwards two instances of the FacApp should be started. The last facapp (faccalcer2 from now on) requests the first faccalcer1 to calculate the factorial of 3. In return faccalcer1 will request faccalcer2 to calculate the factorial of 2... But how is this possible ? How can the original requester be interrupted while he is still waiting ? The answer lies in the Java threading mechanism. Every time an RMI call comes in, the server-thread will spawn a new thread which handles the request. This can be seen in figure 9.
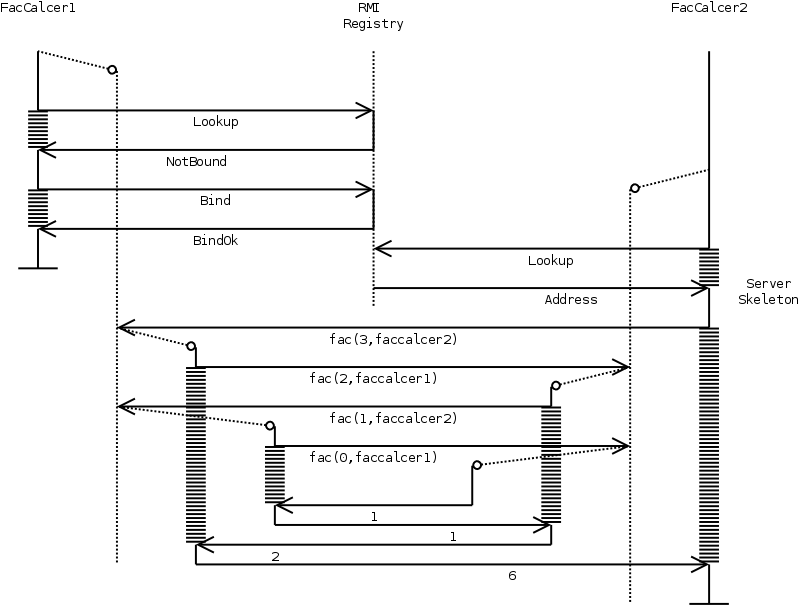
|
The result of this behavior is nicely what a programmer would expect. The problem is that this application suffers from a number of conceptual problems, which are essentially grounded in the inherent problems of distributed systems: concurrency and partial failure. We will explain this below.
LET'S HAVE A LOOK at how failures of the underlying network and failures of processes are caught. Java has a well-known language construct of exceptions and uses this to report errors that occur when contacting a remote object. Technically, RMI achieves this by letting the stub throw an appropriate exception. When, on the other hand, the skeleton fails while executing the incoming message (because the program throws some kind of exception) it will simply serialize the exception and send it back to the client.
Although, this solution looks nice, there is not much that can be done when such an exception is caught. Do we reconnect with the server, do we inform the user, or what should we do ? The main problem programmers encounter here is how to handle those exceptions in a structured way.
To illustrate these problems, suppose we have a process ![]() that
calls another process
that
calls another process ![]() , which in its turn will contact process
, which in its turn will contact process
![]() again. What will happen when process
again. What will happen when process ![]() dies at the
moment
dies at the
moment ![]() is sending back its result to
is sending back its result to ![]() ? Will process
? Will process ![]() know in what state
know in what state ![]() is ? How will the exceptions cascade ?
Figure 10 illustrates this. At the moment
is ? How will the exceptions cascade ?
Figure 10 illustrates this. At the moment ![]() ,
i.e. at the moment process
,
i.e. at the moment process ![]() received a broken pipe exception from
the underlying socket layers, it does not know anymore that it originally
received a call from process
received a broken pipe exception from
the underlying socket layers, it does not know anymore that it originally
received a call from process ![]() . Process
. Process ![]() cannot easily know
that an internal thread
cannot easily know
that an internal thread ![]() is still executing or not. The net
result is that process
is still executing or not. The net
result is that process ![]() ends up to be in an unknown, probably
invalid, state.
ends up to be in an unknown, probably
invalid, state.
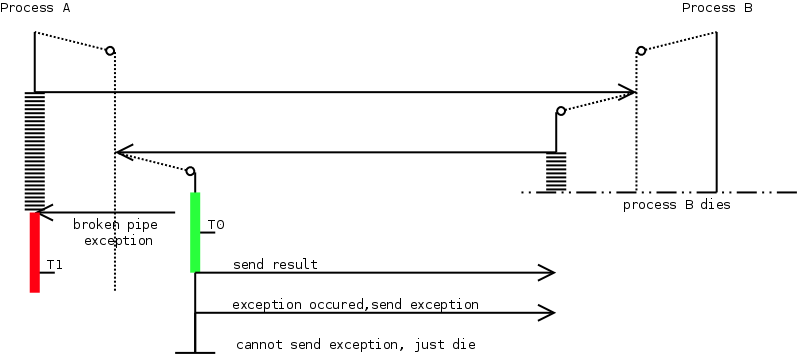
|
SINCE JAVA IS A LANGUAGE with native support for threads, we need to investigate how concurrency can be managed and what kind of language constructs are available. The first and most important language construction is synchronized.
synchronized(foo)
{
int val=foo.read();
foo.write(val+1);
}
In Java all objects can have a lock, when an object is synchronized
the current thread will try to obtain a lock on that object, and if
the lock is obtained, the statement block will be executed. When leaving
the block statement the lock is released again. The object locks are
reentrant, so the same thread can lock the same object multiple times.
With this construct one can easily implement a critical section. However,
it is still allowed that other accesses to the foo object
are not synchronized, thereby ignoring concurrency behavior.
A second construct is the possibility to synchronize methods in an object. For example:
synchronized public void increase()
{
...
}
Which means that the increase method will only execute when the this
object is locked. In fact we can write exactly the same as follows:
public void increase()
{
synchronized(this)
{
...
}
}
Now, although a nice construct it suffers the same problems as all
concurrency primitives in object oriented languages: the inheritance
anomaly. Suppose, we specify a method in a class to be synchronized,
this means that all overriding methods must be synchronized too. This
effectively means that a subclass cannot choose to be not synchronized
for its own actions, and be synchronized for the super calls. Aside
from this annoying problem, there are a lot of other problems with
respect to synchronization and concurrent object oriented languages.
Note that, aside from these (relatively low level) synchronization mechanisms, there are other solutions like wait-notify mechanisms, the Java Transaction interface which offers a much more high level approach to concurrency strategies and others. For a more detailed discussion about concurrency management and Java see [Lea00].
THE JAVA THREADING MECHANISM and the way Java RMI uses it, makes it possible for one remote object to be invoked multiple times by different threads on a concurrent basis. This means that the object's state will be soon invalid if we don't guard access to the remote method.
If we now use the standard Java keyword synchronized to guard access to the remote object, we see that only one thread can enter the remote object at a time, thereby placing all other threads in wait until the object becomes available again. However, this still raises some problems.
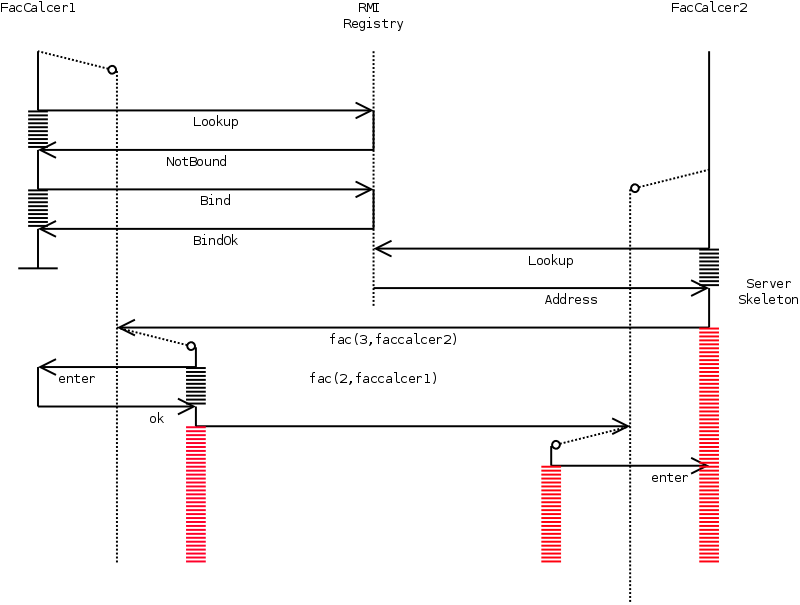
|
For example, let us take the previous factorial example and assume that the fac method is synchronized. What will happen ? One would expect the program to produce its standard result 3,2,1,... and so on. In practice this will not happen because the thread that comes back from the first faccalcer is different from the thread that is waiting inside a synchronized block. So this new thread will have to wait for the lock to be released and finally deadlock because this new thread is supposed to offer an answer before the calling thread will release the lock. In figure 11 we see the control flow of this program.
This example illustrates that we still need some active form of session management in distributed systems. It also illustrates how concurrency problems cannot simply be solved by synchronizing methods. In distributed systems every remote interface will need to export some kind of concurrency interface, and the implementation will need to have a well thought off concurrency management strategy. This concurrency management is typically larger than the actual actions to perform. We will come back on these issues in detail in chapter 5.
WE HAVE NOW SEEN how Java RMI works. We have seen how concurrency is managed and how threads are used. Writing adaptors with Java RMI is clearly not as easy as with the component system we have been using.
![\includegraphics[%
width=0.80\textwidth]{StubSkeletonFlow.eps}](img487.png)
![\begin{algorithm}
% latex2html id marker 7699
[!htp]
\begin{list}{}{
\setlengt...
...ar
}\end{list}\par
\caption{
A distributed recursive factorial.}
\end{algorithm}](img489.png)