De inleiding van dit Deel bestaat uit het definiëren van een referentiekader voor agent frameworks. Nadien kijken we naar de taal Java en zijn virtuele machine en onderzoeken we in hoeverre deze taal de voorzieningen, beschreven in de introductie, ondersteunt. Daarna zijn we in staat bestaande agent systemen, die geïmplementeerd zijn in Java, onder de loep te nemen, waaronder Aglets (Hoofdstuk 4), Mole (Hoofdstuk 5) en de Infosphere (Hoofdstuk 6). Nadien zullen we in Deel II een eigen systeem ontwerpen en schrijven.
In dit hoofdstuk bespreken we allerhande aspecten van agents zoals persistentie, mobiliteit, intelligentie, autonomiteit en communicatie. Deze en andere eigenschappen dienen in acht genomen te worden als we een agent framework willen implementeren. We definiëren zo dus een referentiekader waarbinnen we agent systemen kunnen evalueren.
In het wetenschappelijk domein van de artificiële intelligentie zijn agents geen vreemden. Het begrip agent is daar weliswaar een rekbaar iets, maar drie aspecten waar toch altijd opnieuw naar gerefereerd wordt en die beschreven worden in de IBM Open Blueprint [14] zijn:
Bovenstaande aspecten laten ons aanvoelen wat we met een agent bedoelen en wat het bereik van mogelijke software agents is. Doch, om het begrip mobiele agent beter te verstaan is nood aan verdere opdeling en beschrijving.
Uit hetgeen we reeds beschreven hebben blijkt dat een agent een software entiteit is die een actie moet uitvoeren voor zijn eigenaar. Het is dus te verwachten dat een agent een proces ten uitvoer brengt en bijgevolg dus ook zelf een proces bevat. Omdat we met meerdere processoren zitten en elke agent autonoom moet kunnen handelen zullen we aan een agent altijd moeten vragen om zijn status te wijzigen. Deze vraag tot statuswijziging gaat over machines heen en wordt het best verwezenlijkt met behulp van asynchrone communicatie. Synchrone communicatie met voorspelbare vertraging kunnen we niet verwachten omdat we enorme fluctuaties zullen zien in de wachttijden nodig om een agent te bereiken. Daarom definiëren we een mobiele agent als een code bevattende actieve autonome entiteit die tussen twee agent systemen getransporteerd kan worden en in staat is asynchroon berichten naar andere agents te sturen.
Wat betreft het gebruik van deze mobiliteit kunnen we een agent zelf laten beslissen wanneer en naar waar hij verhuist. In dit geval spreken we over expliciet mobiele software agents. Als er expliciet mobiele agents zijn, zijn er vanzelfsprekend ook impliciet mobiele agents die zelf geen initiatief zullen nemen om zich te verplaatsen. Tussen deze twee uitersten heerst een continuüm (een agent kan bijvoorbeeld `hints' geven aan het agent systeem). Een voorbeeld van impliciete mobiliteit is een framework waarbinnen een agent verplaatst wordt omdat dit de algemene performantie ten goede komt.
Afhankelijk van de context waarin we denken, ontdekken we andere toepassingen. Als we bijvoorbeeld aan de mobiliteit denken doemt onmiddellijk mobile access op. Dit is de meest voor de hand liggende toepassing aangezien gebruikers vandaag de dag zeer mobiel zijn. Stel dat een gebruiker zich met zijn laptop van Europa naar Amerika verplaatst, dan wil die gebruiker al de resources waar hij normaal aan kan, kunnen bereiken en gebruiken op veilige wijze. Zijn mobiliteit zou zo transparant mogelijk gemaakt moeten worden. Hoe de communicatie met remote resources verwezenlijkt wordt kan gaan van modem communicatie tot satelliet verbindingen. Zelfs docking stations zijn mogelijk. De autonomie en de intelligentie van dergelijke agents moet dermate hoog zijn dat ze zich aan nieuwe omgevingen gemakkelijk kunnen aanpassen. Het zou bijvoorbeeld nuttig zijn mocht een remote user zijn resources, bijvoorbeeld een demo van een project, naar hem kunnen roepen.
Net zoals de structuur van het net van plaats tot plaats zeer snel wijzigt, wijzigt ook de structuur van bedrijven en organisaties zeer snel. Men verhuist van statische fixed person/fixed tasks naar dynamische snel evoluerende structuren waarbij men vluchtige crisisgroepen heeft die tijdelijk resources aanspreken om een bepaalde taak uit te voeren. Voorbeelden hiervan zijn crisis management, teams voor proposal review en research collaboration. In netwerk gecentraliseerde omgevingen bieden intelligente agents een uitkomst om deze snelle herstructurering op te vangen. Meer specifieke voorbeelden zijn meeting makers en de collaboratieve design van formele specificaties. Hierbij worden de wensen en eisen van iemand zo goed mogelijk verdedigd. We kunnen ons dus verder concentreren op deze interactie met de omgeving en streven naar Vloeiend aanpasbare virtuele organisaties en samenwerkingsverbanden [11] met behulp van mobiele agents.
De hierboven beschreven snelle wijziging van inter-coöperatieve verbanden treffen we ook aan op niveau van systeem management. Systeembeheerders houden er niet van repetitief werk uit te moeten voeren. Soms moet men een machine configureren of diagnostiseren waar men fysisch niet aan kan. In deze gevallen willen we eigenlijk een actief netwerk dat systeem en netwerk management zoals Remote diagnostics heel wat vereenvoudigd. David L.Tennehouse beschrijft hetgeen hiervoor nodig is in `Toward an active network architecture' [15]. De ordinaire pakketjes die over ethernet gestuurd worden, worden in dit voorstel vervangen door `capsules', miniatuurprogrammaatjes die in elke netwerknode geïnjecteerd worden en daar actief kunnen deelnemen aan de routing van berichten.
Als we uit een heel ander vaatje tappen komen we aan de kant van intelligente agents te liggen, die door het opstellen van patronen van de gebruiker de nodige informatie proberen te filteren. FireFly is een voorbeeld van een intelligente agent die zich voorziet van dergelijke modellen en daarmee een muzieksmaak patroon van een gebruiker opstelt om zo na een tijdje zelf naar voor te komen met voorstellen. Dergelijke agents bevragen de enorme hoeveelheden informatie die voorhanden zijn steeds vanaf hun lokale machine. Hier kunnen mobiele agents zeker al zorgen voor snellere toegangstijden door op de servers hun filtering door te voeren in plaats van op de clients. Het actief vinden van informatie vraagt natuurlijk wel de nodige infrastructuur met voldoende meta data bevat om te beschrijven wat bepaalde resources inhouden. [18]
Als we bovenstaande scenario's bekijken komen we tot de constatatie dat we steeds de wachttijden voor de gebruiker proberen te beperken. In het eerste geval willen we de remote gebruiker snel bedienen door zijn software naar hem te verhuizen, in het tweede geval willen we de lokale interacties tussen clusters opdrijven door ze te herorganiseren. In het derde geval trachten we netwerk management te vereenvoudigen door de routing gemakkelijk aanpasbaar (lees: optimaliseerbaar) te maken en in het vierde scenario willen we de constante querying die optreedt bij opzoeken van informatie reduceren.
Een tweede aangename eigenschap van mobiliteit die gevonden kan worden in de paper `Process Migration' [7] heet fault resilience. Als we in normale omstandigheden verplicht zijn een machine af te zetten, dan kunnen de mensen die hiervan gebruik maakten tijdelijk niet meer aan hun resources en/of tools. Door het automatisch verplaatsen van hun werkomgeving die ze gebruikten kan het uitvallen van die machine sterk verborgen worden.
Nu we het eens zijn over het nut dat verplaatsen van agents heeft, is het tijd om na te denken hoe we een agent en zijn bijbehorende proces(sen) van de ene machine naar de andere machine kunnen verplaatsen. Ruwweg genomen zijn er twee manieren om processen te verplaatsen. [16]
We kunnen een volledig nieuw proces creëren op de nieuwe lokatie: remote execution. Hierbij wordt de programmacode en zijn bijhorende data verplaatst naar de doellokatie. Daar wordt een nieuwe thread gestart die dan zelf moet zorgen dat al de nodige data opnieuw ingelezen wordt. Het uitvoeren van een nieuw proces kan gebeuren door de ontvangen code te compileren en te runnen of door ze onmiddellijk te interpreteren. Tegenwoordig is hier een mix tussen interpreteren en compileren aan te treffen, zoals JIT's (Just In Time Compilers) aantonen. De resultaten na een remote execution zijn een nieuw proces en een nieuwe status. Net zoals een fork onder Unix.
Migratie zorgt dat de huidige execution state volledig verplaatst wordt naar een andere virtuele machine. Het belangrijkste verschil met remote execution is dat het nieuwe proces zelf zijn data niet meer moet inlezen en dat dit op een transparante wijze plaats grijpt. De stappen waarin dit kan gebeuren zijn:
Als we in staat zijn onze processen en hun bijhorende data te verplaatsen komen we natuurlijk in de problemen wat betreft eigendom van resources en agents. In tegenstelling tot client/server, waar alleen maar de vraag rijst hoe we een server beschermen tegen aanvallen van buitenaf, snijdt hier het mes aan beide kanten. Op het ene moment willen we een agent systeem beschermen tegen aanvallen van binnenkomende agents die teveel resources vragen en op een ander ogenblik willen we een agent en zijn data beschermen tegen bepaalde eventueel vervalste agent systemen. Bijvoorbeeld het verwijderen en inpluggen van een nieuwe agent of het sturen van berichten onder naam van een niet aanwezige agent zorgt voor de nodige paranoia. Een typerend voorbeeld om systeem resources op te gebruiken is het recursief genereren van agents.
Samen met het gebruik van resources ontdekken we dat onze agents moeilijk
persistent te maken zijn. Kan machine ![]() voldoende in vertrouwen
genomen worden om agent
voldoende in vertrouwen
genomen worden om agent ![]() er zijn data op te laten stockeren ?
Deze vraag is eigenlijk geen nieuwkomer en heeft juist aanleiding
gegeven tot de situatie waarin we vandaag de dag verkeren. Omdat weinig
mensen bestaande servers vertrouwen voor persistente data storage
gebruiken ze hun eigen machine en zijn ze verantwoordelijk voor hun
eigen data.
er zijn data op te laten stockeren ?
Deze vraag is eigenlijk geen nieuwkomer en heeft juist aanleiding
gegeven tot de situatie waarin we vandaag de dag verkeren. Omdat weinig
mensen bestaande servers vertrouwen voor persistente data storage
gebruiken ze hun eigen machine en zijn ze verantwoordelijk voor hun
eigen data.
Omdat niet alle agents tegelijkertijd nodig zijn en gebruikt worden is het nuttig de mogelijkheid te bieden agents achter te laten op een spoolmedium en te (her)activeren als er een bericht voor hen binnenkomt. In bestaande agent systemen heeft men expliciete activatie- en deactivatie methoden zodat het agent systeem zelf niet moet raden wanneer een agent geactiveerd/gedeactiveerd mag worden. Dit komt architecturaal overeen met het runnen van inetd onder Unix systemen. Deze daemon zal andere services beschikbaar maken op het ogenblik er een vraag voor binnen komt. Httpd wordt bijvoorbeeld enkel gestart als er een http request binnenkomt.
We praten nu wel over mijn machine en jouw machine, maar deze naamresolutie is een tikje te ad hoc. Stel dat een machine ineens van eigenaar verandert en dat al de agents daar moeten verhuizen. Hoe lossen we dit dan op ? Hoe kunnen we zorgen dat deze agents, die dan tijdelijk moeten verhuizen, bereikbaar blijven zonder absurd veel manuele updates te moeten doen ? Het probleem zelf is tweedelig, enerzijds willen we een agent kunnen refereren door een naam te gebruiken, anderzijds willen we de agent kunnen bereiken door een naam te gebruiken.
Hoe we agents en agent systemen een eigen naam geven en hoe we naar een agent refereren op een unieke wijze is essentieel. Dit kan gaan van globaal unieke naming waarbij elke agent op het net een strikt unieke naam heeft tot unieke naming binnen bepaalde domeinen. Een ander aspect van een agentname is de duur waarin de naam zelf geldig blijft. Dit kan gaan van agentnames die onmiddellijk ongeldig worden na een verplaatsing tot namen die over meerdere virtuele machines en eventueel meerdere runs heen worden meegedragen. Afhankelijk van het agent systeem dat we onderzoeken zullen we andere benaderingen aantreffen.
Zoals reeds opgemerkt is naming niet het enige probleem dat optreedt. Eens we de naam van een agent kennen, willen we deze agent ook kunnen bereiken. Dit liefst op een wijze waarbij een verplaatsing van een agent geen of toch zo weinig mogelijk impact heeft op de naam die we gebruiken. We willen dus de positie van een agent transparant maken ten opzichte van de gebruikers van de agent, die enkel berichten kunnen sturen naar andere agents. Het is dus duidelijk dat location transparency enkel nodig is als we met andere agents communiceren. Dit kan verwezenlijkt worden door de routing van berichten voldoende slim te maken, of door de programmeurs van agents zelf de nodige voorzieningen te laten treffen.
Eén manier om location transparency te voorzien is de idee van proxy agents. Hierbij leidt men de toegang tot een agent om door een zogenaamde proxy. Hierdoor kunnen we de agent in kwestie laten verhuizen zonder dat dit merkbaar wordt. De proxy zorgt er dan voor dat alle berichten geforward worden naar de juiste positie.
Een ander nut van deze proxies wordt gevonden in het zelf definiëren van een interface tot een agent. We kunnen bijvoorbeeld een proxy maken die aan ontvangen berichten een prioriteit toekent en zo dus een front end vormt voor de agent. Een proxy, gebruikt als interface tot een agent, kan bijvoorbeeld ook enkel de berichten die de agent wil ontvangen doorlaten. Als agent A enkel berichten wil ontvangen van `hisFather' en niet van `hisMother' kan de proxy hiervoor zorgen. Activatie- en deactivatie-methoden passen zeer goed in deze context. De proxy kan dan zelf kiezen wanneer de agent geactiveerd moet worden.
Andere mogelijkheden tot location transparency en naming worden besproken in Deel 2 waarbinnen we een eigen framework uit de grond stampen.
Berichten sturen is de enige manier voor agents om elkaars status te wijzigen. We kunnen niet zoals in de meeste objectgerichte systemen een object hardhandig binnendringen met een proces om er zijn status te wijzigen. Hoe we de message passing tussen agents implementeren is een ander vraagstuk. De communicatie tussen agents wordt vaak gebaseerd op asynchrone message passing. Zoals geweten is kan hier synchrone message passing over gelayerd worden. Daaruit volgt dat we niets missen door ons te beperken tot asynchrone message passing.
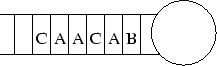
Algemeen komt asynchrone message passing neer op het aaneenschakelen van queues. Als we dit doen volgens het Actor message passing systeem [31] hebben we één queue waarbij men niet kan wachten op een bepaald type, waarbij men steeds het eerste bericht van de queue moet halen, in dit geval `B'. Als we aan het Maisie [30] message passing system denken zouden we in staat zijn een bepaald message type uit de queue te halen en zo bijvoorbeeld berichttype B over te slaan en onmiddellijk het eerste `A'-type te nemen.
In dit hoofdstuk hebben we getracht een beeld te schetsen van het vage begrip `agent'. We hebben hieromtrent niets formeel kunnen vastleggen omdat het begrip zelf zo vaak in andere contexten gebruikt en misbruikt wordt. Wij zullen, telkens we over een agent spreken, het hebben over een mobiele actieve autonome software entiteit die bepaalde opdrachten moet volbrengen. Hiertoe kan hij op asynchrone basis communiceren met andere agents. Om een beeld te schetsen van wat een agent is hebben we een aantal toepassingen uitgelegd en hebben we geconstateerd dat het steeds de factor performantie is die komt bovendrijven.
Op het ogenblik dat we zelf begonnen na te denken over agents en agent systemen bleken er een aantal problemen op te doemen. Het eerste probleem op zich was het verplaatsen van de nodige processen. Een tweede probleem omvatte het geven van namen aan agents en het bereiken van agents door gebruik te maken van die naam. Onafhankelijk van deze voorzieningen moet overdacht worden hoe agents `communiceren', met andere woorden, hoe berichten tussen agents behandeld worden. Het laatste probleem dat we geïdentificeerd hebben is het secure maken van agents en agent systemen.
In dit onderdeel bespreken we in hoeverre de taal Java voorzien is om agent frameworks mee te implementeren. We gaan er onmiddellijk vanuit dat de agent description language dezelfde is als de taal waarin het framework geschreven is. Op het einde van deze sectie worden implicaties van het doorbreken van deze benadering overschouwd. Maar eerst en vooral moeten we onderzoeken wat de Java virtuele machine ons te bieden heeft.
Elke Java virtuele machine heeft een byte-code die zeer standaard geworden is. Elke www-browser, elke machine kan vandaag een Java bytecode interpreter runnen. We gaan er vanuit dat de lezer vertrouwd is met de Java VM maar vermelden toch nog even dat het een stack-machine is voor een object geöriënteerde taal waarbij de code zelf wordt bijgehouden in klasse-files. Eén enkele klasse-file komt overeen met één klasse voor de virtuele machine. De enige lijmstructuur zijn deze klassen en bijgevolg ligt het voor de hand te overwegen een soort agent voor te stellen als een klasse en de agent zelf als instance van deze klasse. Het eerste voordeel is dat de klasse-files veel compacter zijn dan de meeste gecompileerde native-code en veel kleiner dan de ongecompileerde source-files. Een ongedocumenteerde Java-file van 3K komt gemakkelijk overeen met een klasse-file van 900 bytes. Deze naar een nog lager niveau compileren mondt vaak uit in grotere data files. Dit biedt duidelijk voordelen voor snel transport over een netwerk.
Een ander voordeel van de bytecode is dat hiermee de heterogeniteit tussen verschillende machines opgeheven wordt, dit niet alleen op niveau van hardware, zoals big-endian en little-endian,4 maar ook op gebied van aanwezige API's. Het virtualiseren van system calls naar het operating systeem om windows te creëren of het aanspreken van files en dergelijke zijn hiervan goede voorbeelden. In Java wordt dit met behulp van een standaard AWT opgelost.
Doordat deze bytecode geïnterpreteerd wordt kunnen we eveneens een sterke veiligheidscontrole uitvoeren wat betreft bescherming van de eigen hardware. De virtuele machine kan alles wat gebeurt, elke instructie die uitgevoerd wordt, controleren of laten controleren door een security manager. Dit houdt ook in dat we de runnende processen kunnen monitoren en beschermen tegen elkaar. De vertraging die ontstaat door het interpreteren wordt door betere technologie zoals `Just In Time Compilers' teruggeschroefd naar zeer aanvaardbare snelheden.
De class files moeten in een virtuele machine geladen worden. De bytecode
heeft hier een paar natives voor die op hoger niveau gebracht worden
door Classloaders die de data van een of andere medium laden (bijvoorbeeld
netwerk, het lokale filesysteem, http, ![]() ) en deze dan in geheugen
dumpen. Deze class loading kan gebeuren op een willekeurig moment
als de virtuele machine aan het runnen is. De nauwe interactie tussen
de classloader en de virtuele machine zorgt ervoor dat enkel
de klassen die nodig zijn geladen worden. Hierdoor komen we in een
situatie waarbij enkel de nodige code geladen wordt. De idee van een
classloader wordt verder in detail besproken in Hoofdstuk 8.1.
) en deze dan in geheugen
dumpen. Deze class loading kan gebeuren op een willekeurig moment
als de virtuele machine aan het runnen is. De nauwe interactie tussen
de classloader en de virtuele machine zorgt ervoor dat enkel
de klassen die nodig zijn geladen worden. Hierdoor komen we in een
situatie waarbij enkel de nodige code geladen wordt. De idee van een
classloader wordt verder in detail besproken in Hoofdstuk 8.1.
Tesamen met het in het geheugen laden van klassen willen we deze klasse, het stuk code dat uiteindelijk de representatie van het soort agent zal worden, kunnen uitvoeren. Dit kunnen we doen door het main proces binnen te laten dringen in nieuw gemaakte instances, met het grote nadeel dat we de control flow niet meer in handen hebben. We zijn in dit scenario dus verplicht tot coöperatief multitasken, en de ervaring wijst uit dat dit meestal oneerlijk uitdraait. Er zullen processen zijn die te veel resources vragen en de control flow amper teruggeven en er zullen moedwillige processen zijn die het hele systeem blokkeren. De virtuele machine biedt hier uitkomst door zijn multi-threading waardoor we een geladen klasse kunnen starten in een eigen thread. De multitasking tussen agents kan nu preëmtief uitgevoerd worden in één namespace. Dit wil effectief zeggen dat we elke agent autonoom kunnen starten door een agent een eigen thread toe te kennen.
Om objecten persistent te maken in doorlopende applicaties (over meerdere runs heen dus) is het nodig de status van objecten (of een graph van objecten) te representeren in hun doorlopende geserialiseerde vorm. JVM en Java bieden de nodige voorzieningen hiervoor door objecten te serialiseren en op een stream te schrijven [1]:
Bijvoorbeeld:
// Het schrijven van de huidige datum naar een file
FileOutputStream f = new FileOutputStream("myfile");
ObjectOutput s=new ObjectOutputStream(f);
s.writeObject("Today");
s.writeObject(new Date());
s.flush();
// Het lezen van string en datum
FileInputStream in = new FileInputStream("myfile");
ObjectInputStream s = new ObjectInputStream(in);
String today = (String)s.readObject();
Date date = (Date)s.readObject();
Het proces waarbij objecten op een stream worden geschreven noemt
men marshalling. Het proces waarbij ze van een stream worden
gelezen noemt unmarshalling. Als een object gedeserialiseerd
wordt, wordt altijd een nieuw object gecreëerd. Java
serialisation kan dus niet gebruikt worden om hetzelfde object te
maken. (dus ![]() , waar
, waar ![]() het deserialiseren is,
het deserialiseren is, ![]() het serialiseren en
het serialiseren en ![]() de vergelijking van de referenties is)
de vergelijking van de referenties is)
Een object is serialiseerbaar als hij de interface Serializable implementeert. Als we zelf willen bepalen hoe een object weggeschreven wordt, moeten we Externalizable implementeren.
Het zou prettig zijn mochten we de runtime stack als serialiseerbaar object kunnen beschouwen zodat we deze mee kunnen serialiseren. Mocht dit kunnen zouden we threads kunnen serialiseren en de coroutine verhuizen naar een andere VM. In dit geval zouden we processen samen met hun execution state kunnen verplaatsen, telescripting met andere woorden. Het verplaatsen van een agent thread zou bijvoorbeeld bestaan uit
FileOutputStream f = new FileOutputStream("tmp");
ObjectOutput s=new ObjectOutputStream(f);
s.writeObject(agent.getCurrentThread());
s.flush();
Doch, op het ogenblik is de stack van de Java virtuele machine een intern object waar we niet direct aankunnen.
Op dit ene minpunt na blijkt de Java virtuele machine voldoende technische ondersteuning te bieden voor het implementeren van agent frameworks. We moeten ons nu de vraag stellen in hoeverre de taal Java tekort schiet voor het schrijven van gedistribueerde applicaties. Eerst en vooral bekijken we een aantal van SUN's benaderingen om distributie te lijf te gaan.
Een feature van de nieuwe Java VM (JDK1.1) is Remote Method Invocation. Dit is een gedistribueerd object model voor de Java virtuele machine dat zoveel mogelijk de huidige semantiek van het Java object model behoudt.5 Hierdoor kan men op eenvoudige wijze gedistribueerde objecten implementeren en gebruiken. Het systeem combineert aspecten van het Modula-3 Network Objects system en Spring's subcontract (aldus []).
Net zoals Remote Procedure Call (RPC) gebruikt wordt om synchroon te communiceren met een server, dus vragen stellen, kan men in Java RMI gebruiken om met objecten op afstand synchroon te communiceren. De doorsnede tussen server en client wordt gedefinieerd in een Java-interface die voor beiden bereikbaar moet zijn. Bijvoorbeeld
public interface RmiServer extends java.rmi.Remote
{Object Print(Object toprint) throws java.rmi.RemoteException;}
Het opvangen van de conversie van interne message passing naar remote message passing wordt gedaan door het genereren van stubs en een skeleton. Een stub is de client-side proxy voor een remote object. Een skeleton van een remote object is een entiteit aan de serverkant, verantwoordelijk voor de dispatching van binnenkomende berichten naar method-calls. De server ziet er in dit geval als volgt uit:
public class RmiServerImpl
extends java.rmi.server.UnicastRemoteObject
implements RmiServer
{private static String MyName=null;
static RmiServerImpl RmiServerken=null;
public Object Print(Object toprint)
{System.out.println(toprint);
return toprint;}
public static void main(String argv[])
{System.setSecurityManager(
new java.rmi.RMISecurityManager());
MyName = "rmi://IGWENT2/RmiServer";
RmiServerken = new RmiServerImpl();
java.rmi.Naming.rebind(MyName, RmiServerken);}}
In de bovenstaande voorbeeldcode zal de main functie een
server instantiëren. De server implementeert de Print
methode die door een client aangeroepen zal worden. Merk ook op dat
na het creëren van een server deze server aan een naam gebonden
moet worden; in dit geval ![]() .
.
De programmastructuur van de client kan hieronder aangetroffen worden. In de main-functie wordt eerst een representatie van de server gecreëerd. Dit wordt gedaan door een stub-klasse (aangemaakt door de bijgeleverde stub compiler: rmic) te instantiëren en te benaderen als interface. (RmiServer in dit geval)
public class RmiClient
{private static RmiServer RmiServerken=null;
protected static void Initialize()
{System.setSecurityManager(
new java.rmi.RMISecurityManager());
String ChannelName;
RmiServerken =(RmiServer)java.rmi.Naming.lookup(
"rmi://IGWENT2/RmiServer");}
public static void main(String argv[])
{Initialize();
RmiServerken.Print("Test");
RmiServerken.Print("Testbis");}}
Javaspaces [2] zijn een andere benadering van SUN om in een gedistribueerde omgeving voor communicatie te zorgen. Hierbij is er een ruimte, een markt, waarbinnen allerhande objecten uitgestald kunnen worden. De ene client kan nu op het gepaste ogenblik een object op de markt gooien en andere objecten kunnen dit eraf nemen. Dit is te vergelijken met een shared memory waar verschillende processen op concureren, zei het in een grotere internetomgeving. Om deze markten te implementeren maken ze gebruik van RMI. De idee achter dit coördination model is duidelijk te lezen in [29] waar Paolo Ciancarini aan de hand van het taal-framework `Linda' allerhande toepassingen demonsteert.
Zoals we opgemerkt hebben bij RMI moeten we in gedistribueerde omgevingen vaak stubs en skeletons genereren. Dit is een vervelend tijdrovend werkje dat automatisch uitgevoerd kan worden door een zogenaamde stub-compiler. Bijvoorbeeld rmic wordt gebruikt om stubs en skeleton paren te genereren voor RMI.
Omdat we in een skeleton object geen jump table van methoden kunnen maken zijn we verplicht de mapping van incoming message naar method call hard te coderen, met als groot nadeel dat het hard coderen van een reeks condities onnodig veel code inneemt en dat deze harde codering hoogst onflexibel is, in die zin dat we niet snel een bericht kunnen toevoegen aan de interface van een object.
Als we met agents werken die een veel dynamischere interface hebben dan methode signatures zullen we berichten moeten afbeelden op eventueel andere, op voorhand onbekende, methoden. Zeker als we op meta niveau over mogelijke onderneembare acties willen redeneren. We hebben duidelijk een perform of apply nodig.
Een ander nadeel van dergelijke stub-generatie is dat deze stubs nog te statisch zijn. We kunnen niet gauw een methode hermappen op een ander nummer. Deze onflexibiliteit wordt nog verder benadrukt als we dynamisch, terwijl een systeem aan het runnen is, een stub willen genereren voor één of ander remote object.
Een ander gebrek van de taal Java op zich is dat we geen meta level controle kunnen doen wat betreft het versturen van berichten. Als we bijvoorbeeld elk bericht, dat van object A naar object B gestuurd wordt, op een eigen speciale wijze willen doorsturen zijn we verplicht gebruik te maken van deze stub/skeleton benadering. Een oplossing zoals Smalltalk waarbij de messageNotUnderstood wordt overschreven is nog niet ingeburgerd.
Door rekening te houden met dit eventueel gebruik van de VM, zijnde dat we een perform nodig hebben, en zijn huidige gebreken, zijnde dat we geen perform hebben, kunnen we de virtuele machine uitbreiden met de nodige primitieven. SUN heeft dit ook bedacht en vanaf JDK1.1 is de notitie van reflectie geïntroduceerd en kunnen we methoden als een object behandelen (first class methods). Helaas is er nog steeds geen messageNotUnderstood voorziening.
Laat ons er nu even vanuit gaan dat we een andere taal dan Java zouden gebruiken om de agents te programmeren. Een mogelijke benadering is dat we scriptjes hebben die van de ene machine naar de andere verplaatsen. Een voorbeeld hiervan is AgentTcl [28], dewelke overigens ook een prachtige demonstratie is van telescripting. Hieronder vindt u een stuk voorbeeldcode van een dergelijke script agent. Het script in kwestie zal één agent maken die van machine naar machine springt om er de lijst van ingelogde users op te vragen.
proc who machines
{global agent
set list ""
foreach m $machines
{agent_jump $m
set users [exec who]
append list "$agent(local-server):\n$users\n\n"}
return $list}
set machines "bald.cs.dartmouth.edu \
tuolomne.cs.dartmouth.edu"
agent_begin
agent_submit $agent(local-ip) -vars machines
-procs who -script {who $machines}
agent_receive code message -blocking
puts "\nWHO'S WHO on our computers\n\n$message"
agent_end
Een voordeel van dergelijke scripting agents is dat ze zeer gemakkelijk bereikbaar zijn voor de eindgebruiker. Dit omdat er geen code gecompileerd moet worden, hoewel dit slechts een psychologische drempel is. Nu de agents niet gecompileerd worden komen we wel tot de vaststelling dat deze agents veel plaats innemen wat betreft code, dit natuurlijk in vergelijking met de Java classfiles. In tegenstelling tot de code-loader (classloader) van Java moeten we ook altijd het volledige programma doorsturen, wat performantieverlies kan betekenen.
Stel nu dat we zulke agents willen runnen in een framework geschreven in Java. In hoeverre gelden de bovenvermelde features van de JavaVM en kunnen we er op steunen ? Wat zeker al vaststaat is dat we een eigen interpreter zullen moeten schrijven om deze scripting-code te vertolken. Dit wil zeggen dat we over geheugenbeheer zullen moeten nadenken.
We kunnen overwegen de garbage collector van de VM te gebruiken om automatisch geheugenbeheer voor de scriptingtaal te voorzien. Dit blijkt inderdaad mogelijk te zijn zolang we er voor zorgen dat elke referentie binnen de scriptingtaal exact overeen komt met één referentie binnen de interpreterende taal.
Omdat de agent scripting en het framework veel verder uiteen staan dan bij het scenario waar een agent een klasse is, komen we tot de constatatie dat we de interface tussen script-taal en framework nauwkeurig moeten definiëren. Dit niet alleen op het gebied hoe we een agent laten verplaatsen of hoe een agent zich aanmeldt, maar ook op gebied van hoe een agent zijn acties onderneemt. Hoe een agent bijvoorbeeld een dialogbox op het scherm krijgt. In feite moeten we hier één grote API voorzien die vragen van de scriptingtaal omzet naar method calls. Ook hier zouden higher order methods een handig geschenk zijn. Doch dit is gemakkelijk te omzeilen door een enorme skeleton te schrijven. Eens dit gedaan is hebben de agents onderling geen last meer van stub en skeleton problemen.
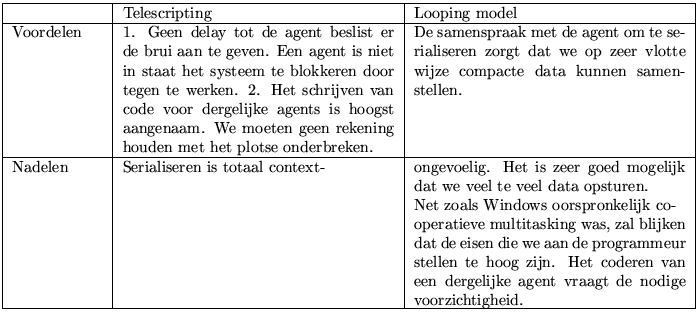
Nu kunnen we het looping model afwegen ten opzichte van het telescriptingmodel. Indien we het looping model nemen moeten we het serialiseren van de execution state zelf doen. We kunnen hierbij duidelijk gebruik maken van de Java serialisation, maar dan moeten we wel zorgen dat elke agent, gerepresenteerd in het geheugen, een eiland vormt dat in één blok opgestuurd kan worden naar de doelmachine. Eens we toch de serialisation van agents grondig hebben onderzocht en we een expliciete runtime stack voorzien hebben kunnen we ons nog moeilijk afwenden van de sublieme telescripting.
In dit onderdeel is gebleken dat interpreters een perfecte basis vormen voor agent systemen. Meer bepaald blijkt de Java virtuele machine nog een paar aangename eigenschappen zoals multithreading, serialisation en classloading te bevatten die het programmeren van agent frameworks heel wat vereenvoudigen. Als we de taal Java beschouwen, kunnen we RMI niet onopgemerkt voorbij laten gaan. Het nadeel aan RMI is dat dit zuiver synchrone communicatie is. Maar het heeft SUN wel verplicht aspecten zoals reflectie te introduceren.
Of we nu interpretatie van een scriptingtaal kiezen of de voorstelling van agents als objecten is een andere keuze. Beide methoden hebben hun voordelen en nadelen. In deze thesis hebben we bewust gekozen voor het schrijven van agents als objecten in Java omwille van de technische mogelijkheden die de Java VM biedt.
We zullen nu overgaan naar het onderzoeken van een aantal bestaande agentframeworks, geschreven in Java.
De Aglet Workbench ontwikkeld door het `IBM Tokyo Research Laboratory' beschrijft en implementeert een agent framework waarbinnen expliciet mobiele agents (Aglets) kunnen verplaatsen van de ene agent context (machine) naar de andere, hierbij code en data transporterend. Hiervoor werd een Agent Transfer Protocol [17] (ATP) ontwikkeld, waarvan agents gebruik kunnen maken. Het protocol is er één waarbinnen naming van agent services en agent identifiers beschreven wordt. Agent verplaatsing en simpele agent bescherming werden in acht genomen. Op het ogenblik wordt de standaard nog uitgewerkt. In de toekomst zouden een query mechanisme, agent authentification, access permissions en agent registry (!) voorhanden moeten zijn.
Omwille van al de beschreven voordelen die de Java VM biedt heeft men een agent gerepresenteerd als een instance van een klasse. De interface tot deze klasse bestaat zowel uit methoden die imperatief een actie uitvoeren op de agent (Creation/Disposing, Activating/Deactivating, Dispatching/Retracting), als uit methoden die aangeroepen worden als dergelijke actie plaats heeft gegrepen. Verder is er nog de handleMessage() methode die aangeroepen wordt door de proxy van de agent als er een bericht binnenkomt.
Onderstaande voorbeeld Aglet toont aan hoe een agent een nieuwe agent creëert, deze verplaatst en er berichten naar stuurt.
public class test3 extends Aglet
{int i=0;
boolean vader;
AgletProxy child; //vader heeft een referentie naar zijn kind
public void onCreation(Object init)
{if (vader=init==null)
child=(AgletProxy)getAgletContext().
createAglet(new URL("file://awb/aglets/public/")
,"MailSys.test3",this);}
public void run()
{if (vader)
{for (int i=0;i<100;i++)
child.sendAsyncMessage(new Message("hello"));
child=child.dispatch(new URL("atp://134.184.49.51")); (***)
for (int i=0;i<100;i++)
child.sendAsyncMessage(new Message("hello"));}}
public boolean handleMessage(Message msg)
{if ("hello".equals(msg.kind))
System.out.println("Hello World");
return true;}}
Aglets verhuizen in dit framework volgens het looping model. Men maakt natuurlijk gebruik van de Java serialisatie om objecten (zowel agent objecten als berichten tussen agents) over te sturen. Code wordt overgebracht door een zelf geschreven classloader. De Aglet Workbench bied zowel synchrone als asynchrone communicatie 6 tussen agents.
Persistentie wordt verwezenlijkt door alle Aglets die persistent moeten zijn lokaal te runnen. Dit wil zeggen dat deze agents zich niet kunnen verplaatsen. Signalisatie tot persistentie wordt gegeven door activation & deactivation methoden. Zolang een agent gedeactiveerd is kan hij op een of ander spool-medium bewaart blijven.
In dit framework treffen we proxy agents aan. Deze proxies laten toe te filteren welke berichten binnenkomen. Hier kunnen we bijvoorbeeld kiezen of we alle berichten van `mummy-agent' negeren, of alle berichten van `teacher-agent' omleiden naar `mummy-agent'. Het systeem verplicht de programmeur al de vragen die hij normaal direct aan de Aglet zou stellen te richten aan de bijhorende agentProxy. Dit is vooral handig als we een gedeactiveerde agent weer willen activeren. Een agentProxy is altijd resident in een agentContext en kan deze niet verlaten.
Zoals we beschreven hebben kan een proxy gebruikt worden om location transparency te voorzien. We zullen dit nu trachten te implementeren. Eerst moet opgemerkt worden dat, als een Aglet van agentContext wijzigt, zijn bijhorende proxy van een localproxy naar een remoteproxy wijzigt. De grote onvolkomenheid hierin schuilt in het feit dat deze verandering van proxy absoluut niet transparant aanwezig is. Stel bijvoorbeeld dat we een agent hebben op machine `Sambal' en op `Oelek' hebben we een AgentProxy naar deze agent gedefinieerd. Op de figuren worden proxies voorgesteld als aureooltjes (ellipsen), de agents zijn de doosjes...
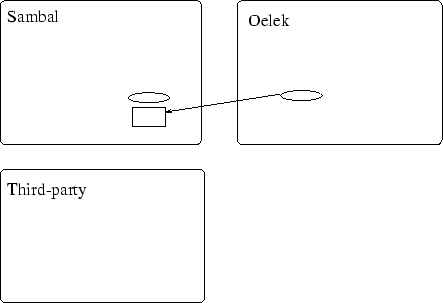
Als we de agent nu verhuizen naar een derde machine zullen we merken dat de proxy op `Oelek' ongeldig geworden is omdat de proxy daar blijft wijzen naar een niet aanwezige agent op Sambal.
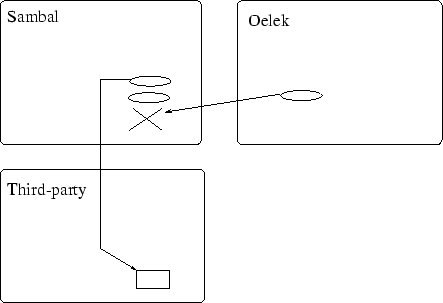
We hebben dus helaas geen location-transparency. Een nog groter probleem bestaat erin dat de referentiele transparantie die we met proxies proberen te halen zelfs binnen de virtuele machine niet geldig is. Als we een agent verhuizen door naar zijn proxy dispatch te sturen kunnen we nadien aan het oorspronkelijke proxy object niets meer vragen omdat de referentie binnen de virtuele machine naar de proxy ook gewijzigd is. (Dit zie je in de voorbeeldcode waar staat child=child.dispatch(...)). We krijgen dus een nieuwe proxy weer na een dispatch !
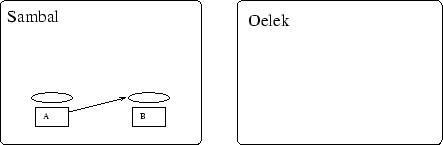
Na de verhuis van Aglet ![]() van Sambal naar Oelek geeft dit binnen
Sambal een referentie naar een proxy die niet meer geldig is omdat
er een nieuwe gemaakt is.
van Sambal naar Oelek geeft dit binnen
Sambal een referentie naar een proxy die niet meer geldig is omdat
er een nieuwe gemaakt is.
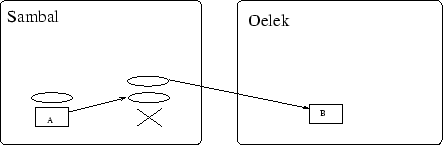
Een ander probleem bestaat erin dat agentproxies niet te serialiseren
zijn. Dit zou nochthans een zeer elegante manier zijn om de verplaatsing
van een agent op te vangen. Als een agent bijvoorbeeld verhuist en
al de proxies die hij nodig heeft meegenomen worden, zouden deze nieuwe
proxies zich bij aankomst weer kunnen verbinden met het juiste remote
object. Dit wil zeggen dat bepaalde localproxies na een
verplaatsing remoteproxies worden. Bijvoorbeeld bij de
verplaatsing van agent ![]() naar `Oelek', waar zowel
naar `Oelek', waar zowel ![]() als
als ![]() op Sambal stonden, zouden we volgend resultaat hebben:
op Sambal stonden, zouden we volgend resultaat hebben:
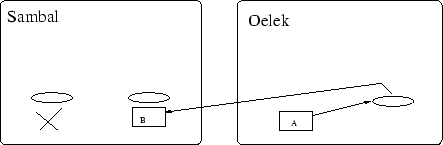
We moeten dus duidelijk concluderen dat proxies binnen de Aglet Workbench enkel nut hebben als interface-omleiders. Location transparency zullen we ergens anders moeten zoeken. Laat ons daartoe eens kijken naar de naming
Naming
in dit systeem wordt op het ogenblik nog op algoritmische basis gedaan.
Elke agent krijgt een computer-gegenereerde naam die de string representatie
is van een hexadecimaal getal. Uniciteit wordt verzekerd door voor
elke identifier een hostname te plakken. (ter illustratie:
![]() is een typerende naam voor
een agent) Wanneer een agent van plaats verandert, wijzigt zijn naam.
is een typerende naam voor
een agent) Wanneer een agent van plaats verandert, wijzigt zijn naam.
Zoals reeds werd opgemerkt is een groot probleem in dit framework hoe we een bepaalde agent kunnen bereiken. Dit probleem wordt nog vergroot omdat we geen enkele agent kunnen benoemen als we code aan het schrijven zijn omdat elke agent identifier gekozen wordt door het systeem. We hebben met andere woorden nood aan één of andere indirectie zoals een name server. Doch hier treedt het probleem op dat we eveneens niet in staat zijn de centrale agent die dienst doet als name server te benoemen en dus zijn we zelfs niet in staat onze name query naar iemand te richten. Een oplossing hiervoor is ervoor te zorgen dat er één factory is waarbinnen al de agents geïmplementeerd worden. Deze factory zou dan aan elke agent die hij creëert zijn eigen adres moeten meegeven zodat het kind de centrale name service kan bereiken.
Zoals men zelf vermeldt zou deze voorziening, een name service dus, aanwezig moeten zijn in een nieuwe uitgave van de Aglet Workbench.
Hoewel deze naming een vreemde zaak is en veel nadelen heeft, zorgt ze ook voor een zeer originele benadering van security.7 Door elke agent identifier algoritmisch te genereren zijn we niet in staat zomaar naar andere agents berichten te sturen omdat we gewoon de naam nog niet kunnen opvragen. Dit wil zeggen dat we steeds kunnen weten wie naar een agent refereert en dus wie potentieel kwaad kan berokkenen. Stel dat een kraker toch de naam van een agent heeft kunnen achterhalen, dan zal die naam de eerst volgende keer dat de agent verhuist weer ongeldig worden. Dit belet natuurlijk niet dat het onmogelijk is dit systeem te kraken, maar de moeilijkheid om een agent te benoemen en te blijven volgen vormt een onmiddellijk beletsel. Een eventuele indringer zal een niveau lager moeten gaan en protocols analyseren om zo fake agents te introduceren die leven op basis van bestaande lokaal runnende agents (die reeds voldoende permissies verkregen hebben).
We hebben nu het eerste framework onder de loep gelegd en gemerkt dat het zodanig veel restricties oplegt dat het onhandelbaar is in het gebruik. Dat we een agentname niet zelf mogen kiezen is het grootste gebrek, dat wel kan leiden tot een grotere security. Location transparency is onbestaande en bijna onmogelijk te implementeren, zelfs met het gebruik van de voorziene AgletProxies. Deze proxies kunnen enkel gebruikt worden om de interface tot een agent te reguleren. Er zijn geen voorzieningen die toelaten meta data en interface beschrijvingen te exporteren.
Het belangrijkste wat we uit dit framework kunnen onthouden is de wijze waarop security behandeld worden.
Mole [8] is een agent framework ontwikkeld aan `the Institute for Parallel and Distributed Computer Systems' aan de universiteit van Stuttgart onder leiding van professor Rothermel. Wat Mole betreft gaat men er vanuit dat mobiele agents, tesamen met hun mogelijkheid tot verplaatsing naar afgelegen hosts, moeten gerund worden in een veilige omgeving. Op deze afgelegen plaatsen/hosts vraagt men services die men lokaal niet onmiddellijk kan benaderen. Uiteindelijk zal men met behulp van agents aan client code distributie doen. Meer bepaald kan agenttechnologie gebruikt worden door klanten om ingewikkelde taken te delegeren naar autonome agents op andere hosts, die deze agents dan asynchroon kunnen runnen. Na het verzamelen en berekenen van de resultaten kan al de data teruggestuurd worden naar de klant.
Mole wordt op het ogenblik gebruikt in een aantal subprojecten zoals
AIDA, ASAP en ATOMAS. In AIDA wil men bestuderen
hoe groepen van agents zich gedragen en hoe deze
in een veilig omgeving gerunt kunnen worden. ASAP loopt in samenwerking
met het zwitserse Media project, waarmee men een commerciële
databank en de documenten daarin bevat, beschikbaar wil maken. Het
praktische onderdeel dat ASAP zou moeten aanbieden is een uitvoeringsplatform
voor mobiele agents. In ATOMAS wil men een soort Linda-systeem (een
systeem zoals de JavaSpaces, uitgelegd op pagina )
implementeren door gebruik te maken van Mole.
Een Mole is een agent gemodelleerd als een cluster objecten zonder referenties naar andere objecten. Die groep als geheel kan verplaatst worden van de ene host naar de andere. Dit wil zeggen dat alle objecten waarvoor een agent direct of indirect kan refereren, de transitieve afsluiting van het main agent object, zijn eigendom zijn.
Dankzij dit eilandconcept kunnen agents door serialisatie gemakkelijk van de ene machine naar de andere verplaatst worden. Moles verhuizen in dit framework volgens het looping-model, zoals te verwachten is, gezien de voorzieningen die de Java VM biedt. De code wordt op het ogenblik net zoals in de Aglet Workbench overgebracht door een zelf geschreven classloader.
Deze mobiliteit laat toe dat agents vrij bewegen naar een zelf gekozen lokatie. Een lokatie komt overeen met de URL van een host. Agents kunnen en moeten zichzelf registreren bij een name service die enkel lokaal draait. Laat ons een voorbeeld geven van een typische Mole, gebaseerd op een voorbeeld geschreven door Fritz Hohl:
public class Flooder extends UserAgent
{public Flooder() {}
public Flooder(String einString, AgentName aName)
{selfdescription = einString;
myname = aName;}
public void start()
{Flooder son = new Flooder("son of " + selfdescription, myname);
Engine.debug("Flooder: my name is " + myname.toString());
try {Thread.sleep(5000);} catch (Exception e) {}
actuallocation.createAgent(son);}}
Men ziet in dit voorbeeld dat een Mole een public constructor heeft die twee parameters neemt. Deze constructor wordt gebruikt om een Mole te maken met een bepaalde naam en beschrijving. De start methode wordt opgeroepen na een migratie of creatie en zal in dit voorbeeld onmiddellijk een nieuwe flooder maken. Na het maken van de agent moet hij nog geregistreerd worden binnen het omringende agent systeem. Dit wordt gedaan door createAgent aan te roepen.
In Mole zijn messages expliciet gemaakt. Als we van agent ![]() naar
agent
naar
agent ![]() een bericht willen sturen creëren we een message object
dat we meegeven aan de agent engine om op te sturen. Dit is op zich
asynchroon omdat we niet wachten op onmiddellijk antwoord. Maar zoals
algemeen geweten, kunnen we hier
synchrone message passing over leggen. Een communicatie voorbeeld
vindt u hieronder.
een bericht willen sturen creëren we een message object
dat we meegeven aan de agent engine om op te sturen. Dit is op zich
asynchroon omdat we niet wachten op onmiddellijk antwoord. Maar zoals
algemeen geweten, kunnen we hier
synchrone message passing over leggen. Een communicatie voorbeeld
vindt u hieronder.
public class MessageTester extends UserAgent
{static messagenumber=0;
public MessageTester() {}
public MessageTester(String einString, AgentName aName)
{selfdescription = einString;
myname = aName;}
public void start()
{Message m=
new Message(myname, actuallocation.locationName(),
new AgentName(1,2,3,4,5,6,7,10),
new LocationName("location2.mole.informatik.uni-stuttgart.de"),
1,"Test");
m.messageid = messagenumber++;
actuallocation.message(m);}
public void receiveMessage(Message m)
{Engine.debug("MT Test from "+ (m.sender).toString());}}
Een message wordt geconstrueerd door zowel van de zender als de ontvanger de naam en positie op te geven. Wat hierin onmiddellijk opvalt is dat we net zoals in de Aglet Workbench de lokatie moeten opgeven naar waar we een bericht sturen. In dit framework hebben we dus helaas ook geen onmiddellijke location transparency want als de agent beweegt moeten alle eventuele gebruikers weten naar waar hij verhuisd is.
Zoals we weten kunnen proxies gebruikt worden om location transparency
te voorzien. Dit framework heeft helaas geen proxies. Wat we wel kunnen
is berichten automatisch laten forwarden naar een andere agentname
als een bepaalde agent niet meer lokaal aanwezig is.
Dus als agent ![]() van plaats
van plaats ![]() naar plaats
naar plaats ![]() verhuist is, kunnen
we op
verhuist is, kunnen
we op ![]() een representant achterlaten die alle berichten automatisch
forward naar de nieuwe agentnaam op plaats
een representant achterlaten die alle berichten automatisch
forward naar de nieuwe agentnaam op plaats ![]() . Men is dus in staat
lokaal een representant te maken voor een remote agent. De representant
is een Mole die we zelf nog moeten implementeren.
We zijn dus in staat zelf te experimenteren met het updaten van positie-gegevens.
. Men is dus in staat
lokaal een representant te maken voor een remote agent. De representant
is een Mole die we zelf nog moeten implementeren.
We zijn dus in staat zelf te experimenteren met het updaten van positie-gegevens.
Representanten bieden de mogelijkheid een reeks van algoritmes te testen. We kunnen bijvoorbeeld een agent maken die slechts één representant heeft staan op de masterlokatie en aan iedereen die een referentie naar de Mole nodig heeft, het adres van de master-representant weergeven. Deze master representant zal dan de berichten doorsturen naar de juiste agent in kwestie. Eigenlijk hebben we zo toch onze eigen proxy, onder de vorm van een agent, gecreëerd. In het hoofdstuk routing wordt een andere mogelijkheid besproken.
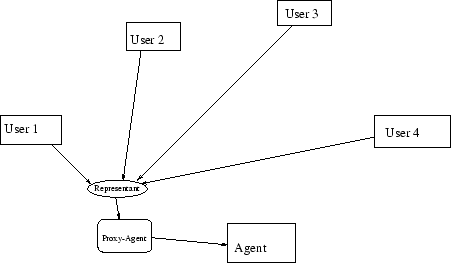
Het Mole framework biedt de mogelijkheid Moles en de toegang tot Moles te monitoren, met behulp van MoleViews en MoleProts. Een MoleProt is een monitor die voor elk bericht dat binnenkomt voor de agent een kopie van dat bericht krijgt. Zo kunnen we dus het gedrag van een agent monitoren. Dit kan helaas alleen als we de agent die we willen monitoren laten afstammen van MoleViewAgent. Met behulp hiervan wil men een grafische representatie maken van de binnenkomende/buitengaande berichten en zo performantietesten visualiseren.
Om agents op te zoeken hebben we de mogelijkheid de interface tot een agent op te vragen met behulp van de functie serviceProvidedBy, en analoog hiermee serviceProvidersOf. Een extra stuk meta informatie kan gestockeerd worden in de selfDescription field van de agent. Dit is uiterst handig als we resources, die een agent gebruikt, moeten herbinden na een verplaatsing.
In dit hoofdstuk hebben we het Mole framework onderzocht. Dit framework bied geen location transparency aan, maar we zijn wel in de mogelijkheid er zelf voor te zorgen. Dit onder de vorm van zelf geschreven proxies. We kunnen agents opzoeken door lokaal de providers van een bepaalde service op te vragen. Deze vorm van meta data is een sterk pluspunt voor dit framework, zeker wanneer we aan resource binding willen doen. Over persistentie is niet nagedacht.
De Infosphere is een agent framework ontwikkelt door de Caltech Infosphere Group (in California). Onderstaande is vrij vertaald en geciteerd uit `The Caltech Infosphere Project: an Overview' [10] en beschrijft wat men wil aanvangen met het framework:
``Iedere gebruiker op het netwerk heeft een Infosphere die gedefinieerd kan worden als zijn huidige status en verzameling middelen die hij heeft. Een hulpmiddel kan de status van medewerkers in een interactie wijzigen. Internet (en specifiek het web) ondersteund dergelijke interacties tussen Infospheres. De gemiddelde gebruiker zijn Infosphere omvat zijn files (persistent storage), zijn tools (browers, object brokers, compilers, editors) en processen die voor hem runnen (notifiers). Een wetenschapper zijn Infosphere kan bestaan uit apparaten zoals microscopen tot en met interfaces zoals secretaresen, collegas in de werkgroep, projectmanagers en zo verder.
Iemand zijn Infosphere verandert wanneer die persoon van plaats tot plaats rijst. De bandbreedte tot een bepaalde service kan sterk teruglopen of verhogen als we op een vliegtuig zitten, per modem inbellen of naar een andere universiteit trekken.
Net zoals iemands Infosphere wijzigt door te verplaatsen, wijzigt iemands Infosphere ook als die persoon zich in een andere rol moet inleven. Wanneer iemand uit zijn rol van coordinator in een multi-instituut research project stapt en in de rol van lesgever stapt verandert zijn Infosphere. De eerste Infosphere omvat instituten en interageert met andere instituten in het researchproject, de budgetten die toegekend zijn, PERT charts etc. De tweede Infosphere omvat interactie met studenten en de werken waarmee ze bezig zijn. Het is zo dat de beide Infospheres niet volledig onafhankelijk zijn omdat sommige delen van hun status gemeenschappelijk zijn voor beide rollen. (bijvoorbeeld de agenda die de persoon in kwestie gebruikt)''
De bedoeling van de Caltech groep is deze interacties tussen Infospheres te modelleren en te virtualiseren door een Infosphere Infrastructure te bouwen.
In tegenstelling tot voorgaande frameworks zijn agents hierin niet mobiel. Niettegenstaande heb ik het framework toch opgenomen in de tekst omdat men zich niet blind gestaard heeft op de mobiliteit maar wel aandacht schenkt aan geheel andere aspecten van agents zoals meta data en communicatie.
Een Djinn 8 is de naam die men op Caltech toegekend heeft aan hun agents. Een Djinn bestaat uit een verzameling mailboxen voor asynschrone communicatie en een interne status, die persistent gemaakt kan worden. Laat ons eens naar een voorbeeld kijken. Hieronder staan twee Djinns. De eerste speelt server voor de tweede. Het enige wat aan de server gevraagd kan worden is de datum weer te geven van de host waar hij draait. In de question methode zien we hoe de datum opgevraagd wordt en hoe die teruggegeven wordt.
public class DateServer extends Djinn
{boolean wasQuestioned = true;
static DateServer djinn = new DateServer();
static {
djinnTrueName = new DjinnTrueName (
"Infospheres Group, Caltech", // org
"W. Tanaka", // author
"infospheres@cs.caltech.edu", // email
1, 0, // release 1.0
"beta1", // release beta1
"Fri, Nov 1 1996", // release date
"DateServer Example Djinn", // name
"http://www.infospheres.caltech.edu/" // url
);}
public Answer question (Question q)
{if (q instanceof TimeQuestion)
{TimeQuestion tq = (TimeQuestion)q;
Date d = new Date();
return new TimeAnswer (d);}
else return new TimeAnswer();}}
De client ziet er ver hetzelfde uit, met dit verschil dat de client niet moet wachten op een vraag maar onmiddellijk van start kan gaan door een vraag op te sturen.
public class DateClient
{public static void main (String args[])
{Lamp lamp = new Lamp();
DjinnName djinnToSummon = new DjinnName (args[1], args[0],
8080, "DateServer");
DjinnName djinnName=lamp.summon(djinnToSummon, null, null);
TimeQuestion q = new TimeQuestion();
Answer a = lamp.question (djinnName, q);
System.out.println ("The remote date is: " +
((TimeAnswer)a).getDate());}
Hoewel het framework zelf geen mobiele Djinns ondersteunt is er toch een belangrijke vorm van mobiliteit aan te treffen in het verplaatsen van de berichten. Elk bericht is een afstammeling van een berichtklasse die serialiseerbaar moet zijn. Op het ogenblik is deze serialisering nog zeer expliciet door middel van writeData en readData methoden, maar het is te verwachten dat bij een nieuwe release van de JDK dit probleem opgelost zal worden door gebruik te maken van de Java serialisation. Als we nu dus een bericht van DateClient naar DateServer willen krijgen moeten we een gepaste instance van een messageklasse (in dit geval TimeQuestion) opsturen naar de DateServer-Djinn, die dan op zijn beurt een TimeAnswer terugsturen:
public class TimeQuestion extends Question
{public void writeData (DataOutputStream dout) {}
public void readData (DataInputStream din) {}}
Men kan zien dat de TimeQuestion absoluut niets serialiseert en dus niets van potentiële interne status wordt opgestuurd. Het enige dat effectief wordt opgestuurd met dergelijke messageklasse is de type-informatie9. De server zal als hij dergelijk bericht ziet enkel moeten controleren op de klassenaam om te weten wat ermee aangevangen moet worden. Het antwoord daarentegen bevat toch wat meer eigen data dan enkel type-informatie:
public class TimeAnswer extends Answer
{private Date date;
public TimeAnswer () {}
public TimeAnswer (Date d) {date = d;}
public void setDate(Date d) {date = d;}
public Date getDate () {return date;}
public void writeData (DataOutputStream dout)
{long time = date.getTime();
dout.writeLong (time);}
public void readData (DataInputStream din)
{date = new Date (din.readLong ());}}
Een Djinn kan zelf mailboxen maken naar believen. De term mailbox refereert zowel naar in-queue's als out-queue's. Elke out-queue kan verbonden worden met meerdere in-queues zoals gevisualiseerd staat in onderstaande figuur.
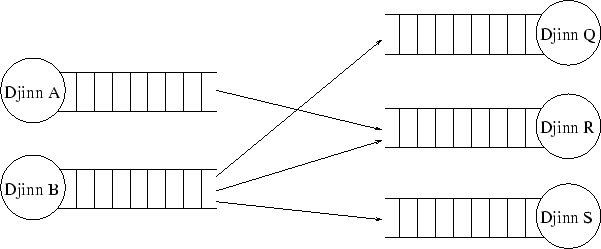
Elke mailbox kan getypeerd worden. Zo kan een mailbox enkel objecten van type A bevatten en een andere mailbox enkel objecten van type B. Voor elke Djinn is er slechts één maildaemon die zorgt dat alle binnenkomende berichten in de juiste mailbox gestopt worden.
Het type van een mailbox komt overeen met het klassetype van
de objecten die we er willen insteken. Als klasse ![]() een afstammeling
is van klasse
een afstammeling
is van klasse ![]() kunnen we zeggen dat mailbox
kunnen we zeggen dat mailbox ![]() afstamt van mailbox
afstamt van mailbox
![]() . De maildaemon zal dan automatisch de meest specifieke mailbox
kiezen. Verder zorgt hij er ook nog voor dat elk bericht binnen een
eindige tijd toekomt. Er zullen anders gezegd geen berichten eeuwig
gequeued blijven.
. De maildaemon zal dan automatisch de meest specifieke mailbox
kiezen. Verder zorgt hij er ook nog voor dat elk bericht binnen een
eindige tijd toekomt. Er zullen anders gezegd geen berichten eeuwig
gequeued blijven.
Agents kunnen in dit framework geactiveerd en gedeactiveerd worden, met het natuurlijke voordeel dat een gedeactiveerde agent op een spoolmedium achtergelaten kan worden. De eenvoud in dit framework, met name dat agents niet mobiel zijn, laat toe de persistentie op doeltreffende wijze op te vangen met eenvoudige freeze en thaw methoden. Ook hier kunnen we in de toekomst rekenen op serialisering door de Java virtuele machine, hoewel dit natuurlijk niet altijd gewenst is, bijvoorbeeld het doorsturen van een sparse matrix kan veel efficiënter gebeuren als we de serialisatie zelf in de hand nemen. Als we zelf de serialisatie in de hand hebben kunnen we eventueel zelfs een voor de mens leesbare representatie gebruiken.
De idee van proxy agents treffen we ook in dit framework aan, zij het onder de naam `Lamp'. Met een `Lamp' kan je een remote agent oproepen. We denken hier natuurlijk onmiddellijk aan Java-agents, doch dit is niet absoluut noodzakelijk. Het is zelfs mogelijk Java klassen te gebruiken die niet afstammen van een Djinn. Voorwaarde is wel dat deze zelf gemaakte klassen de Summonable interface implementeren. We kunnen dus een interne Java representatie maken op de lokale machine van ongeveer elk denkbaar remote object, eventueel zelfs niet-Java programma's.
Naming in de Infosphere bestaat uit de hostname met daarachter de naam van de Djinn en het poortnummer waarop men hem kan bereiken. Deze naam is globaal uniek en wordt de DjinnName genoemd. Een Djinn heeft verder een DjinnTrueName die meer informatie bevat over de Djinn. Hierin treffen we de auteur en de organisatie van de Djinn aan. Het emailadres, de releasedate, het versienummer en een leesbare name zijn eveneens beschikbaar. Uiteindelijk moeten we ook de URL waar de Djinn leeft meegeven. Deze info is niet meer echt relevant om een Djinn te benoemen maar ze is wel nuttig om een bepaalde Djinn terug te vinden op het WWW met behulp van search engines.10 Een extreem voordeel van de Djinntruename is dat we in staat zijn Djinns te mirrorren en te dupliceren. Een aspect waar andere agent systemen vaak te kort schieten.
Nu we toch in de buurt van meta data beginnen komen kunnen we onmiddellijk ook interface beschrijvingen toevoegen aan elke Djinn. Dit kan een beschrijving zijn op mailbox niveau, of dit kan een beschrijving zijn op methode niveau. Meer info hieromtrent vind de lezer in `Leveraging the World Wide Web for the Worldwide Component Network' [12]. Een typisch voorbeeld vind u hieronder:
<META name="component_identifier" content="http://components.cs.caltech.edu/calendar/kiniry/1.0/"> <META name="description" content="This is the standard Calendar component used at Caltech. It provides for interactive and automatic scheduling of meetings between arbitrary groups of participants at arbitrary locations."> <META name="keywords" content="calendar, scheduling, distributed, component, infospheres, caltech, java, tcl, corba">
De Infosphere is een framework waarbinnen sterk nagedacht is over communicatie tussen agents onderling. Het is tot nu toe het enige communicatiesysteem aangetroffen binnen agent frameworks dat toelaat berichten te typeren en te differentieren op basis van het type.
De meta data die men toevoegd aan Djinns laat toe snel bepaalde services op te zoeken. Het nadeel is wel dat Djinns niet verplaatsbaar zijn, wat wil zeggen dat we geen last hebben om proxies te creëren en location transparency te voorzien, juist omdat Djinns niet kunnen verhuizen.
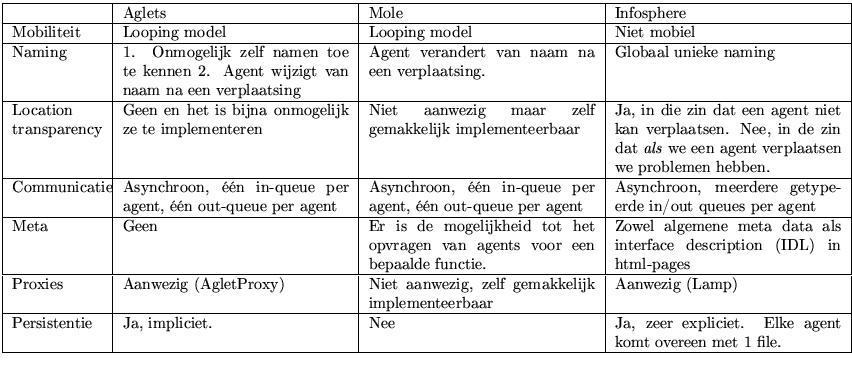
In het eerste deel van deze thesis hebben we besproken wat belangrijk is aan agentframeworks en waar er problemen optreden. Het blijkt zo te zijn dat Java in deze context een onverwacht handig hulpmiddel is om te redeneren over en te experimenteren met mobiele agents. Om ons in te werken in deze materie hebben we een drietal frameworks grondig uitgespit. De eerste noemt de Aglet Workbench, de tweede heet Mole en de laatste is de Infosphere. De eigenschappen van elk van de drie systemen staan hieronder samengevat.
We kunnen concluderen dat location control het grootste gebrek is aan bestaande agent systemen. Een ander enorm probleem is dat van security en resource misbruik. Het eerste probleem zullen we trachten oplossen. Het probleem van security is er een probleemdomein op zich vanwege zijn complexiteit. We zullen hier dan ook niet verder over uitwijden.