Zoals beschreven in sectie 2.6 werken we in een gedistribueerde omgeving waarbinnen agents op elk moment van de ene machine naar de andere kunnen verhuizen. De nodes in het netwerk zijn verbonden door middel van een LAN/WAN, zoals de internet omgeving waarbij de wachttijden tussen de verschillende hosts serieus kan oplopen en de throughput geregeld enorm laag kan liggen. In deze uitgebreide omgeving treffen we gigantisch veel agents aan die op ireguliere basis van de ene machine naar de andere machine kunnen verplaatsen.
We hebben reeds uitgelegd dat het programmeren van agents in Java, best gedaan kan worden door elke agent voor te stellen als een instance van een Java-klasse. De voordelen hiervan worden beschreven in 3. In het kader van deze thesis, waarin we een architectuur voor impliciet mobiele agents willen bouwen, mogen we dus verwachten dat agents volledig location transparant bereikbaar zijn. Dit houdt effectief in dat we elk agent object op elke aanwezige host een globaal unieke naam moeten geven. Meer specifiek willen we dat
Een naam is een symbolische representatie van een entiteit. Dat ding kan een actie zijn om uitgevoerd te worden of een object van een bepaalde soort, bijvoorbeeld een agent. Entiteiten kunnen meerdere namen hebben. Een naam heeft enkel betekenis in een naam-context, in dit geval het refereren naar agents. Een name-space is de verzameling van alle mogelijke geldige namen. Het naam-domein is de verzameling van alle mogelijke dingen die benoemd kunnen worden in een bepaalde context. Een entiteit kan aan een naam gebonden worden. Herbinden is het toekennen van een nieuwe entiteit aan een eerder gebruikte naam.
Resolutie (ook wel name-lookup genaamd) is het omzetten van een naam naar het ding dat hij representeert. Als resolutie zorgt voor het teruggeven van een nieuwe naam die gebruikt kan worden in een andere/verschillende context spreekt men over een address. [3]
Aangezien we het in deze thesis hebben
over mobiele agents is het noodzakelijk elke verblijfplaats voor een
agent een unieke naam te geven. Een agent verblijft altijd in een
virtuele machine. Dus als we ooit een agent een unieke naam willen
geven moeten we al zeker zijn dat de virtuele machine waarop een agent
runt een unieke naam heeft. Dit kunnen we doen door de standaard hostname
te nemen en er een poortnummer achter te plakken. Het poortnummer
is nodig om meerdere virtuele machines te kunnen laten runnen op één
host. Een voorbeeld van dergelijke naam is ![]()
We mogen er vanuit gaan dat eens de naam van een VM gekend is deze
niet meer gewijzigd mag worden. Dit is een reële eis omdat het
veranderen van IP-nummer en hostname altijd pijnlijk is als we een
continu, vaak gebruikt, werkend systeem hebben. In het extreme geval
dat de naam van de machine toch gewijzigd moet worden dient dit volledig
transparant te gebruiken voor iedereen die ooit die naam opgevraagd
heeft. We kunnen hier met bestaande middelen reeds zorgen voor persistente
namen, bijvoorbeeld door gebruik te maken van DNS. In dit systeem
geeft men elke naam opnieuw een naam. Bijvoorbeeld ![]() is het adres
is het adres ![]() en deze laatste is een naam voor
en deze laatste is een naam voor
![]() die op zijn beurt het hardware-adres
die op zijn beurt het hardware-adres ![]() refereert. Door gebruik te maken van het Handle-system [4]
kunnen we hier nog extra indirecties aan toevoegen die namen toelaat,
nog veel langer te bestaan.
refereert. Door gebruik te maken van het Handle-system [4]
kunnen we hier nog extra indirecties aan toevoegen die namen toelaat,
nog veel langer te bestaan.
In deze thesis zullen we ons beperken tot gewone hostnames omdat de experimenten toch nooit lang genoeg duren.
Nu elke virtuele machine een unieke persistente
naam heeft, moeten de instances die er runnen ook een aparte naam
krijgen. Een instance kan een agent zijn of zelfs een gewoon object.
Een instance is een lokale entiteit, het maakt niet uit wat, die een
naam moet krijgen. Omdat virtuele machines uniek benoemd zijn en de
instances op die machine dit ook zijn is de combinatie van beide,
bijvoorbeeld ![]() , een globaal unieke
naam.
, een globaal unieke
naam.
We streven ernaar slechts één naam en niet meer dan één naam toe te kennen per instance. Mochten we toch toelaten een instance meerdere namen te geven schept dit problemen wat betreft het vergelijken van instances. Nu zijn we in staat instances te vergelijken op basis van hun naam. Als we toch meerdere namen voor hetzelfde object willen kunnen we dit doen door een `alias' te introduceren die refereert naar de echte instance name. Stel dat we de agent `Werner' ook `Ditmar' willen noemen. Dan kunnen we beter `Ditmar' een alias laten zijn voor `Werner'. Dus als we naar `Ditmar' refereren krijgen we onmiddellijk het adress voor Ditmar weer, zijnde Werner. Raarmee weten we perfect wat we moeten weten: over wie het gaat. Het is duidelijk dat we voldoende hebben aan exact één unieke naam per instance.
Ter vergelijking: binnen Java RMI is
instance naming ook gebasseerd op de unieke hostname met daarachter
een lokaal unieke naam. Bijvoorbeeld:
![]() . De host zorgt hierbij zelf
voor het toekennen van unieke namen aan instances door het lokaal
draaien van een naming service, rmiRegistry genaamd. Voor de virtuele
machine zelf is het hier simpel. Hij heeft een namespace die hij volledig
vrij kan gebruiken. De uniciteit naar buiten toe wordt gegarandeerd
door de unieke VM-name.
. De host zorgt hierbij zelf
voor het toekennen van unieke namen aan instances door het lokaal
draaien van een naming service, rmiRegistry genaamd. Voor de virtuele
machine zelf is het hier simpel. Hij heeft een namespace die hij volledig
vrij kan gebruiken. De uniciteit naar buiten toe wordt gegarandeerd
door de unieke VM-name.
Dergelijke host qualified namen specifieren dus wel degelijk een lokatie.
Als men de naam vast heeft weet men direct over welk object op welke
machine het gaat. Dit geld natuurlijk enkel als we met niet mobiele
objecten werken. Als objecten mobiel moeten zijn zullen we ons moeten
afvragen of deze naam mag wijzigen van bijvoorbeeld: ![]() hernoemen naar
hernoemen naar
![]() .
Het zal blijken dat dit niet wenselijk is.
.
Het zal blijken dat dit niet wenselijk is.
Tot nu toe was het betrekkelijk simpel. Zwaar
steunend op DNS hebben we ervoor gezorgd dat elke machine, en de objecten
erop, een unieke naam hebben. Objecten en andere entiteiten op een
virtuele machine zijn helaas niet het enige wat we nodig hebben. We
moeten ons ook zorgen maken over de naming van de klassen die we instantiëren.
Omdat men in Java een classloader heeft die klassen van overal zonder
specifieke naam kan laden kan men dus klasse-name-clashes tegenkomen
als we een klasse instantiëren. Bijvoorbeeld
als in een applet new Test() staat moet de klasse `test'
geladen worden. Eerst zal de omgeving dit remote proberen doen en
als dat niet gaat zal de lokale klasse genomen worden. Men heeft dus
geen zekerheid over de klasse die overeen komt met de naam `Test':
Test kan resolven naar ![]() of
naar
of
naar ![]() Dit geeft zeker problemen
op het ogenblik dat men een agent van de ene VM naar de ander laat
verhuizen, waar men dus eigenlijk geen klassen remote wil laden, of
men allesinds niet wil weten van waar ze komen. We willen dat één
klasse naam globaal overeen komt met één klasse.
Dit geeft zeker problemen
op het ogenblik dat men een agent van de ene VM naar de ander laat
verhuizen, waar men dus eigenlijk geen klassen remote wil laden, of
men allesinds niet wil weten van waar ze komen. We willen dat één
klasse naam globaal overeen komt met één klasse.
Het is duidelijk dat het idee van een ClassLoader niet orthogonaal staat op de design van de klasse naming in Java. Al de naming wordt gedaan volgens een filesystem (effectief op disk). Het laden van klassen van ergens anders, een netwerk bijvoorbeeld, met een ander naamschema, zoals de classloader toelaat, is een sterke doorbreking van de oorspronkelijke directory-structuur.11
Eigenlijk willen we naming niet overdragen aan de classloader maar nog naar een stadium vroeger. Een oplossing is dus classloaders te verbieden of zo veel mogelijk te vermijden en zich enkel te beperken tot de SystemClassLoader. Om dergelijk systeem te kunnen implementeren hebben we een virtueel filesystem nodig dat buiten Java staat en zorgt dat alle nodige klassen op tijd beschikbaar zijn. Hierdoor worden al de class-namingconflicten buiten de virtuele machine gebracht en het bied mogelijkheden tot optimalisatie (die absoluut noodzakelijk zullen zijn). Bijvoorbeeld het mirrorren van de standaard java.lang.*; Een voorbeeldfilesystem kan er als volgt uit zien:
/
/java is ftp://java.sun.com/pub/jdk1.02/classes.zip
/java/lang/*
/java/io/*
/dnx is ftp://dnx.lr.com/pub/lr1.02/dnx/*
/dnx/lr/*
/dnx/lr/node/*
/vub.we.ig/Collections staan locaal op disk
Het speciale aan dit globale filesysteem
is dat er een mounting point opgelegd wordt. Als gebruiker van het
systeem zouden we niet in staat mogen zijn ooit ![]() ergens anders te mounten dan onder /java. Dit kunnen we verwezelijken
door op dit filesysteem een juiste permissiecontrole en direct aan
de basis te zorgen dat elke klassenaam uniek is.
ergens anders te mounten dan onder /java. Dit kunnen we verwezelijken
door op dit filesysteem een juiste permissiecontrole en direct aan
de basis te zorgen dat elke klassenaam uniek is.
Wat betreft de beschikbaarheid van dergelijke systemen hebben we niets aangetroffen dat voor dit specifieke geval ontworpen is. Desalnietemin kunnen we ons behelpen door op Unix stations gebruik te maken van NFS en onder Windows gebruik te maken van de standaard shared services. Een andere mogelijkheid is het schrijven van een classloader die dit wwfs (world wide filesystem) zelf implementeerd. Dit zou helaas niet toegankelijk genoeg zijn en is veel minder algemeen. Voor de mensen die verder willen met dergelijke filesystemen is Prospero [5] zeer nuttig. We gebruiken het helaas niet omdat het filesysteem niet transparant gemount kan worden, wat wil zeggen dat het programma niet interfacebaar is met het `fysieke' filesysteem dat door de Java runtime benadert wordt.
Nu we reeds zo ver zijn moeten we zien hoe we agents een naam gaan geven. In de Infosphere heeft elke Djinn een willekeurige naam, zonder direct verbonden VM-name. In de plaats daarvan voegt men een hoop meta data toe die in html-files beschreven wordt. [12] Rekenend op de goodwill van search engines zou men zo een Djinn kunnen terugvinden. Het probleem hiermee is dat als een agent eens van plaats wijzigt de search engines direct outdated zijn. Deze benadering is dus danig ontoereikend.
Het enige waar we op dit niveau, waar we trachten naamconflicten op
te lossen, zekerheid over willen hebben is dat elke agent die in de
wereld rondloopt een unieke naam heeft. Hoe we deze agent dan terugvinden
is een zorg voor later. De voor de hand liggende oplossing is elke
agent een instance name te geven (deze zijn reeds globaal uniek).
Let wel op ! De naam van een agent wijzigt niet als hij van virtuele
machine verspringt. Een Cookie agent gecreëerd op igwe8 met de
naam ![]() heeft dus als hij fysiek verblijft
op igwe1 nog steeds de naam
heeft dus als hij fysiek verblijft
op igwe1 nog steeds de naam ![]()
Het wijzigen van een agent zijn naam als hij van plaats verhuist is op zich al een vreemd idee. Als we een pot confituur uit kast halen en op tafel zetten verandert die ook niet van naam. Als die toch van `confituur' naar `gelei' zou wijzigen kunnen we argumenteren dat we met twee verschillende entiteiten zitten, zijnde de confituur-in-de-kast en de gelei-op-de-tafel. Op het ogenblik dat we de pot verhuizen van de kast naar de tafel houd de confituur-in-de-kast op met bestaan en ontstaat er een volledig nieuwe entiteit gelei-op-de-tafel. Deze hoogst bizarre wijze van redeneren is blijkbaar heden ten dage gemeengoed in agent systemen.
In de besproken systemen werd er weinig of geen aandacht geschonken aan het verzenden van berichten. En zeker niet aan -hoe- ze er geraken. Doch hier moeten we toch voorzichtig zijn. We werken nu in een dynamische omgeving waar een agentnaam plots kan overeenkomen met een andere lokatie. De meeste mobiele-agent-systemen gaan er vanuit dat dit zorgen zijn voor de programmeur van de agent en bieden soms ad hoc oplossingen aan. We zullen aantonen dat deze benadering nodeloos blijkt te zijn en dat we een performant routing algoritme kunnen ontwikkelen voor mobiele agents.
In het voorgaande hoofstuk hebben we een globaal uniek namingsysteem
opgezet. Hierbij geldt dat agents hun naam niet mag wijzigen na een
verplaatsing, omdat we anders geen persistente referenties naar agents
kunnen doorgeven. Een voorbeeld van dergelijke naam was ![]() .
Wat we nu willen is dat we naar deze agent, door enkel gebruik te
maken van zijn naam, een bericht kunnen sturen. Als we dus een bericht
sturen naar de agent
.
Wat we nu willen is dat we naar deze agent, door enkel gebruik te
maken van zijn naam, een bericht kunnen sturen. Als we dus een bericht
sturen naar de agent ![]() moet die,
eender waar de agent zich bevindt, toekomen. Het probleem dat hierbij
natuurlijk ontstaat is dat we in de naam
moet die,
eender waar de agent zich bevindt, toekomen. Het probleem dat hierbij
natuurlijk ontstaat is dat we in de naam ![]() geen enkele informatie hebben van waar de agent zich op het ogenblik
bevind.
geen enkele informatie hebben van waar de agent zich op het ogenblik
bevind.
Een eerste gedachte die optreed om dit probleem te benaderen zijn stubs.
Een stub is een dummy-agent die een bericht dat binnenkomt doorstuurt naar de juiste agent. Soms wordt dit ook een proxy genoemd, hoewel een proxy meer functionaliteit kan bieden, zoals het activeren en deactiveren van een agent, of het monitoren van de berichten die gezonden worden naar een agent. We zullen, als we het over het location-aspect van een proxy hebben, steeds spreken van een stub.
Met stubs is het mogelijk, telkens als een agent verplaatst, een stub12 (forwarder) achter te laten. De stub is in dit geval het steentje dat Klein Duimpje heeft laten vallen.
De nadelen van dit systeem:
Ook dit stub-systeem heeft een paar nadelen:
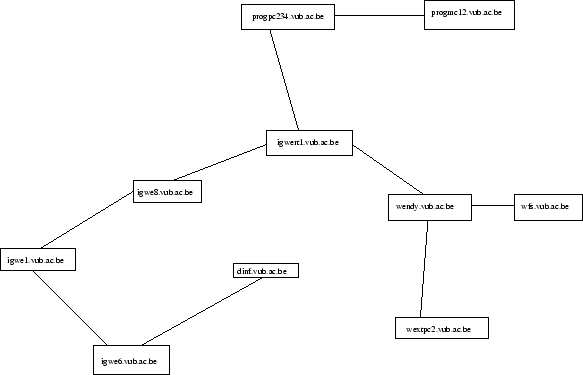
Een andere klasse van positiebepalende systemen is het gebruik maken van name servers. Bij deze zoekt men, voor men een paket kan versturen, het adres van de bestemming op door aan het een name server te vragen. Dergelijke routingmethode noemt men sourcerouting. 13
Het is denkbaar dat sourcerouting bruikbaar is in kleine systemen waar één centrale name server vlot bereikbaar is. In wide area networks is de overlast van het opvragen van een adres helaas te groot om bruikbaar te zijn. Dit kan geremedieerd worden door een reeks lokale name servers te gebruiken en die aan elkaar te koppelen: een gedistribueerde name server. Hier treden echter enorme concurentie problemen op die dit systeem onhandelbaar maken.
Een andere enorme moeilijkheid is dat tussen het opvragen van de naam, de namelookup, en het gebruiken van de naam, de agent die we willen bereiken misschien niet meer bestaat. Het opvragen van een naam en het routen van een bericht moet als atomaire operatie beschouwd worden.
Bij hop by hop routing stuurt men het bericht dat men wil versturen naar de name server. Deze kijkt wat ermee aangevangen moet worden en stuurt het bericht verder naar de volgende name server.
Bijvoorbeeld: We hebben op een bepaalde plaats twee agent systemen
runnen. Zijnde ![]() en
en ![]() .
Aan de andere kant van de aardkloot is er een systeem
.
Aan de andere kant van de aardkloot is er een systeem ![]() .
Verder zit er nog een hele hoop name-servers en hosts tussen. Voor
het gemak doen we alsof er maar één tussen zit, genaamd
.
Verder zit er nog een hele hoop name-servers en hosts tussen. Voor
het gemak doen we alsof er maar één tussen zit, genaamd
![]() . Op onderstaande figuur staan de routingtabellen.
. Op onderstaande figuur staan de routingtabellen.
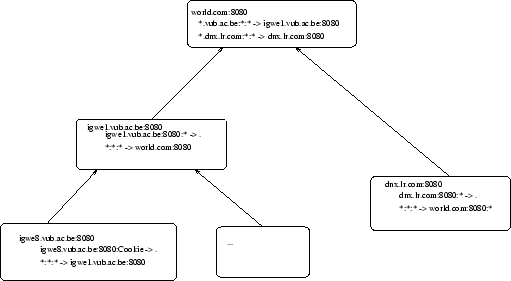
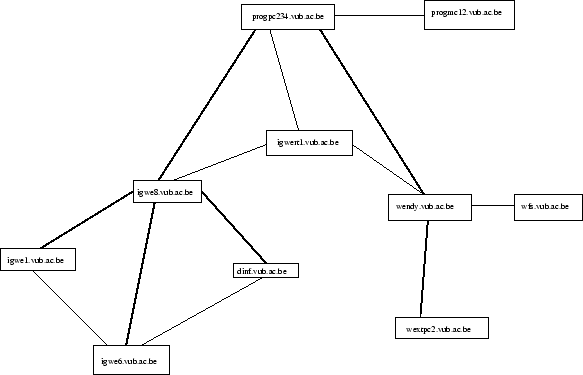
Als nu ![]() een message wil sturen naar
een message wil sturen naar
![]() , dan zal het agent systeem op igwe8 zien
dat hij niet weet waar deze zit. Het bericht wordt doorgestuurd naar
igwe1, die op zijn beurt niet weet waar de doelagent zich bevind.
Igwe1 zal dan het bericht doorsturen naar world.com. Deze ziet dat
, dan zal het agent systeem op igwe8 zien
dat hij niet weet waar deze zit. Het bericht wordt doorgestuurd naar
igwe1, die op zijn beurt niet weet waar de doelagent zich bevind.
Igwe1 zal dan het bericht doorsturen naar world.com. Deze ziet dat
![]() te vinden is binnen
te vinden is binnen ![]() en stuurt het bericht door naar die machine.
en stuurt het bericht door naar die machine.
Als we die hop by hop routing een tikje aanpassen komen we bij een systeem dat zeer bruikbaar is. Eerst zullen we het informeel beschrijven. Nadien zullen we het idee in pseudocode uitgewerkt geven.
Als een agent zich verplaatst van zijn originele positie gebeurt dit via de name server. De name server ziet dat en verandert de regel die naar deze agent verwees. Hij laat hem naar de lokatie wijzen naar waar de agent gestuurd is. Als de agent zo verder uit het domain verplaatst, wordt dit doorgegeven aan de volgende name server die weer de agentpositie update.
Na het verplaatsen van de agent zien de routers er als volgt uit.
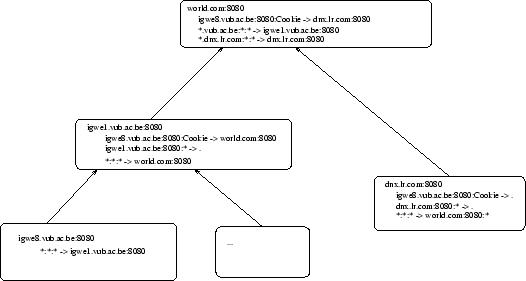
De voordelen van dergelijke systeem :
We zullen om twee redenen formeel aantonen dat dit algoritme werkt. De eerste reden is dat we zo het algoritme formaliseren, de tweede reden is dat we dan zeker van zijn dat het inderdaad werkt in algemene gevallen. Het bewijs verloopt een beetje zoals men in VDM correctheidsbewijzen geeft.
Eerst moeten we de nodige verzamelingen introduceren. Dit is vrij
eenvoudig en straight-forward. Zoals te verwachten is, hebben we eerst
een verzameling agents
![]() nodig. Deze verzameling is een reeks
`mogelijke' agents. De agents die effectief gebruikt worden zitten
in de verzameling
nodig. Deze verzameling is een reeks
`mogelijke' agents. De agents die effectief gebruikt worden zitten
in de verzameling
![]() . Aangezien we agents willen benoemen
hebben we ook een verzameling namen, zijnde
. Aangezien we agents willen benoemen
hebben we ook een verzameling namen, zijnde
![]() nodig.
Net zoals bij de agents hebben we hier de verzameling
nodig.
Net zoals bij de agents hebben we hier de verzameling
![]() die al de namen bevat die gebruikt worden. Agents leven altijd op
een of andere host die uit de verzameling
die al de namen bevat die gebruikt worden. Agents leven altijd op
een of andere host die uit de verzameling
![]() komt.
komt.
Nu we al de mogelijke entiteiten in verzamelingen hebben onderverdeeld
dienen we een aantal relaties te definiëren waarmee we allerhande
aspecten van een agent kunnen opvragen. We hebben de naam en de host
van een agent nodig en op een bepaalde host willen we weten naar waar
we onze berichten kunnen routen. Deze relaties zijn zo gekozen dat
we dezelfde restricties hebben als in gedistribueerde systemen. Om
die reden voeren we geen functie
![]() in die een agentnaam
als invoer neemt.
in die een agentnaam
als invoer neemt.
Van een agent kunnen we zijn naam opvragen. Deze functie moet injectief
zijn, we willen niet dat twee verschillende agents eenzelfde naam
kunnen hebben. Het is duidelijk dat deze functie niet op alle mogelijke
startwaarden gedefinieerd is. Daarom kunnen we
![]() (
(
![]() )
beschouwen als al de bruikbare refereerbare agents. We kunnen over
een referentieel transparant framework spreken als we
)
beschouwen als al de bruikbare refereerbare agents. We kunnen over
een referentieel transparant framework spreken als we
![]() niet moeten wijzigen van de ene statuswijziging naar de andere.
niet moeten wijzigen van de ene statuswijziging naar de andere.
Van een agent kunnen we ook opvragen op welke host de agent zich bevind
met behulp van de functie
![]() . In tegenstelling tot
. In tegenstelling tot
![]() moet deze functie niet injectief zijn. Het is mogelijk dat twee agents
op dezelfde machine runnen.
moet deze functie niet injectief zijn. Het is mogelijk dat twee agents
op dezelfde machine runnen.
Om op een lokale machine te weten naar waar we een bericht moeten
sturen hebben we een router-functie nodig. Deze functie wordt
![]() genoemd en neemt een host en een agentname als parameter. De host
is de machine waarop men wil weten hoe men de agent met naam agentname
kan bereiken. Als antwoord wordt een host weergegeven naar waar het
bericht gestuurd zou moeten worden.
genoemd en neemt een host en een agentname als parameter. De host
is de machine waarop men wil weten hoe men de agent met naam agentname
kan bereiken. Als antwoord wordt een host weergegeven naar waar het
bericht gestuurd zou moeten worden.
Met deze functies hebben we voldoende om aan te tonen dat het beschreven algoritme correct werkt, maar voor we daartoe komen definiëren we de staat van het globale systeem
De staat van het globale systeem is een 3-tupel bestaande uit een
![]() -functie, een
-functie, een
![]() -functie en een
-functie en een
![]() -functie.
-functie.
Telkens als we
![]() of
of
![]() schrijven refereren
we naar het eerste, tweede en respectievelijk derde element van het
oude tupel. Primes worden gebruikt om een nieuwe configuratie aan
te duiden.
schrijven refereren
we naar het eerste, tweede en respectievelijk derde element van het
oude tupel. Primes worden gebruikt om een nieuwe configuratie aan
te duiden.
We mogen wensen dat elke host een route heeft naar elke mogelijke andere host. Doch dit willen we niet opleggen in de definitie van een configuratie. We zullen aantonen dat, indien we met een goede startconfiguratie vertrekken en we slechts één transitie toelaten, dit systeem consistent blijft.
Deze transitie is het verplaatsen van een agent naar een naburige
host. Om de notatie te vereenvoudigen gebruiken we een dag (![]() ).
).
![]() geeft een nieuwe functie weer die de oude
overridden heeft. De nieuwe ziet er dan als volgt uit:
geeft een nieuwe functie weer die de oude
overridden heeft. De nieuwe ziet er dan als volgt uit:
![]()
![]()
Bovenstaande transitie is enkel geldig als
![]()
De eerste regel zorgt dat de routing anders verloopt. De enige twee elementen die hier gewijzigd worden zijn te vinden op de nieuwe host en de oude host. De tweede regel zorgt dat de agent inderdaad verplaatst is.
De restrictie laat enkel toe de transitie te gebruiken om een agent
te verplaatsen naar een naburige host; als we nu een agent van een
host naar een niet naburige host
![]() willen verplaatsen
gebruiken we het volgend algoritme:
willen verplaatsen
gebruiken we het volgend algoritme:
![]()
Hierin definiëren we aan wat het systeem steeds moet voldoen. Hetgeen waarvan we al zeker willen zijn is dat we elke agent die bestaat kunnen bereiken zonder dat er iets gezegd wordt over performantie, noch over concurrentie. Vanuit elke startconfiguratie die we willen gebruiken moeten we bewijzen dat het onderstaande waar is initieel en waar blijft na een transitie.
De eerste regel zegt dat we geen onperformante lussen willen zien, de tweede zegt dat het eindpunt van de route inderdaad de agent moet bevatten en de laatste geeft ons de constructie van het pad.
De startconfiguratie waarmee we verder zullen werken is diegene waarbij
elke agent verblijft op zijn host die vermeld staat in zijn naam.
![]() is op dit gebied een hulpfunctie die de host weergeeft
die vermeld staat in een agentname. In de startconfiguratie is reeds
een routing voorzien die zorgt dat we elke mogelijke host kunnen bereiken.
is op dit gebied een hulpfunctie die de host weergeeft
die vermeld staat in een agentname. In de startconfiguratie is reeds
een routing voorzien die zorgt dat we elke mogelijke host kunnen bereiken.
Nu zullen we bewijzen dat deze startconfiguratie aan de gestelde eisen voldoet:
Aangezien elke agent een naam heeft gelegen op de host zelf kunnen
we een pad maken van ![]() tot
tot ![]() met
met
![]() .
Met de gegeven start weten we dat al de hosts verbonden zijn via de
start-resolvefunctie:
.
Met de gegeven start weten we dat al de hosts verbonden zijn via de
start-resolvefunctie:
De rij die hier uit komt nemen we gewoon over als route. (3) is dan onmiddellijk bewezen. (2) kan bewezen worden als volgt:
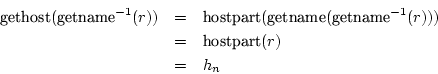
Dat er geen dubbels voorkomen wordt bewezen als volgt: Stel dat we
een lus kunnen creeren:
![]() met
met ![]() . Dan moet er een
. Dan moet er een ![]() en
en
![]() zijn zodat
zijn zodat
![]() wat niet kan
aangezien
wat niet kan
aangezien
![]() een functie is en dus geen twee beelden kan
hebben.
een functie is en dus geen twee beelden kan
hebben.
Stel dat we van ![]() naar
naar ![]() zijn gegegaan via
zijn gegegaan via
![]() dan zullen we een rij construeren die voldoet aan de gewenste eigenschappen.
Binnen
dan zullen we een rij construeren die voldoet aan de gewenste eigenschappen.
Binnen ![]() bestond reeds een rij om aan onze bestemming te geraken:
bestond reeds een rij om aan onze bestemming te geraken:
![]() .
.
![]() kan voldoen aan een paar eigenschappen. ofwel is
kan voldoen aan een paar eigenschappen. ofwel is ![]() onze doelagent, ofwel is
onze doelagent, ofwel is ![]() een andere onafhanekelijke agent. Laat
ons beginnen met
een andere onafhanekelijke agent. Laat
ons beginnen met ![]() volledig onafhankelijk:
volledig onafhankelijk:
We hebben een transitie
![]() waarbij
waarbij
![]() en we hebben reeds een rij vanuit de vorige stap
en we hebben reeds een rij vanuit de vorige stap ![]() . Deze rij
kunnen we in zijn geheel overnemen.
. Deze rij
kunnen we in zijn geheel overnemen.
(1) is waar omdat, als er in de vorige stap geen lussen in zaten er nu nog steeds geen zullen inzitten aangezien we geen wijzigingen aanbrengen.
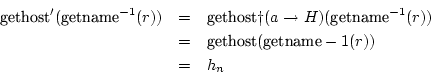

We hebben in dit geval een transitie
![]() die geschreven
kan worden als
die geschreven
kan worden als
![]() . Hierbij is
. Hierbij is ![]() ofwel een nieuwe host ofwel één die reeds in de rij voorkwam.
Als hij reeds in de rij stond knippen we de rij af op
ofwel een nieuwe host ofwel één die reeds in de rij voorkwam.
Als hij reeds in de rij stond knippen we de rij af op ![]() , in
het andere geval nemen we
, in
het andere geval nemen we ![]() . Omwille van deze constructie staan
er geen lussen in de rij en is (1) bewezen.
. Omwille van deze constructie staan
er geen lussen in de rij en is (1) bewezen.
(2) wordt bewezen aan de hand van het gebruik van de injectiviteit
van
![]() :
:
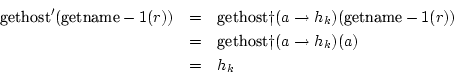
De laatste eis wordt ook voldaan:
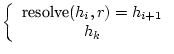 |
(4) |
Het eerste geval geeft inderdaad ![]() zoals gewenst. Het tweede
geval komt
zoals gewenst. Het tweede
geval komt ![]() uit. We weten dat dit ligt aan het koppel
uit. We weten dat dit ligt aan het koppel
![]() dat afgebeeld wordt op
dat afgebeeld wordt op ![]() . Nu moeten we bewijzen dat dit enkel
kan als
. Nu moeten we bewijzen dat dit enkel
kan als
![]() . En inderdaad dit kan niet anders.
Eer de transitie
. En inderdaad dit kan niet anders.
Eer de transitie
![]() geldig is moet
geldig is moet
![]() , dit kan enkel als in de voorgaande
, dit kan enkel als in de voorgaande
![]()
![]() vanwege
vanwege
![]()
We hebben hier eigenlijk bewezen dat als een agent zich verplaatst het pad dat een bericht volgt ofwel vanachter één element korter wordt, ofwel één element langer wordt.
Dit algoritme werd onafhankelijk van andere research-labo's ontworpen. Voor de volledigheid geven we een aantal referenties naar andere bestaande papers, die pas laattijdig doorgekomen zijn. Als we zoeken naar andere hierarchische systemen zijn referenties [35], [36], [37] en [38] nuttig. De lezer die een gedetailleerde in-depth studie van de gebruikte algoritmes wil uitvoeren neemt het best [39] vast. De location transparency beschreven in deze papers maakt deel uit van een architecturaal groter systeem, waarvan meer informatie gevonden kan worden in [33] en [34].
Een andere benadering waarbij men de statische toer opgaat wordt besproken in `Efficient Location Transparency in Concurrent Object Oriented Languages' [32], waarin men een Actor computationeel model als geschikt formalisme hanteert.
In dit hoofdstuk hebben we een routingalgortime ontworpen dat een performante manier om agents te bereiken aanreikt. Eer dit mogelijk was hebben we grondig naar de manier van naamgeven gekeken. In het kort komt het erop neer dat, als men agents en instanties binnen een virtuele machine een globaal unieke naam wil geven men moet beginnen met elke virtuele machine een unieke naam geven. Een belangrijk probleem dat daarbij optrad was dat niet alle Java-klassen uniek benoemd zijn. De basis van deze naamconflicten ligt essentieel in het feit dat men meerdere virtuele machines heeft, die elk hun eigen klasse definiëren en gebruiken. Als droom hebben we een filesysteem geformuleerd dat deze klasse-name-clashes buiten de virtuele machine bracht, maar aangezien dit het best mogelijk te wensen geval is, zullen we ons moeten beperken tot het gebruik van classloaders en shared filesystems.
Eens we deze naam-conflicten opgelost hadden, hebben we een aantal routing technieken onderzocht (zoals stubs, name servers en hop by hop routing). Geen enkele methode voldeed perfect aan de gestelde eisen, zijnde een performante location transparante routing voor mobiele objecten. Uiteindelijk hebben we zelf een algoritme geschreven dat op basis van hop by hop routing rekening houdt met de agents die verplaatsen. Om dit hoofdstuk af te sluiten hebben we bewezen dat het algoritme werkt, zonder rekening te houden met performantiecriteria of concurentie.
Nu we het gehad hebben over de routing van de data flow tussen agents wordt het tijd dat we een blik werpen naar hoe we dit zullen implementeren en aanbieden aan de programmeur van de agent. Vragen die hier rijzen zijn hoe we berichten voorstellen, hoe we berichten verplaatsen van de ene machine naar de andere, welke beperkingen we opleggen en hoe we berichten afhandelen. In hetgeen volgt betekend ``bericht'' een hoeveelheid informatie die van de ene agent naar de andere gestuurd moet worden.
Eerst zullen we ons plaatsen aan de zijde van de agent programmeur, die gemakkelijk agents wil kunnen programmeren. In het tweede onderdeel zullen we behandelen hoe we dergelijke interface implementeren.
We kunnen overwegen berichten voor te stellen als byte-arrays zoals UDP-paketjes, doch dit is een low level benadering die niet vaak meer aangetroffen wordt. Als we ons iets hoger plaatsen kunnen we er aan denken datareeksen te gebruiken waarbij we er een expliciete onderverdeling op plakken, ze dus als ``structuur'' door te sturen. Waarbij rekening gehouden wordt met de volgorde van de bytes. Een hoger niveau van abstractie treffen we aan in objectgerichte talen waarbij het doorgeven van berichten neerkomt op het doorgeven van objecten. Als we dit in een agent systeem willen steken zijn we verplicht code mee op te sturen, maar dat vormt geen enkel probleem meer.
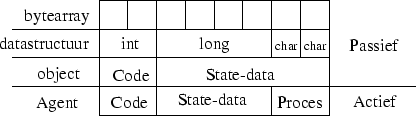
Dit brengt ons in de verleiding agents te gebruiken als message passing tussen agents, dus agents gebruiken als actieve berichten. Doch dit kunnen we niet doen omdat we dan de kern van het probleem ontwijken. Het bericht (de agent dus) is dan nog steeds niet in staat zichzelf aan te melden bij de ontvanger. Verder kan de vraag gesteld worden welk nut gevonden wordt in het actief maken van elk bericht.
Bijgevolg zullen we berichten voorstellen als passieve data, onder de vorm van een instance van een Java-klasse.
Altijd en overal waar we berichten doorsturen zijn deze expliciet of impliciet getypeerd. Het type van het bericht bepaalt wat ermee aangevangen kan of moet worden. Dus, of we nu willen of niet, berichten zijn getypeerd. Het is dus niet misplaats ons zorgen te maken over de uniciteit van de typering. We willen bijvoorbeeld niet dat twee verschillende data typen ontvangen worden als hetzelfde bericht-type. We willen dus niet dat een float en een double beiden als double worden behandelt.
Omdat we een bericht tussen agents voorstellen als een object hebben we de mogelijkheid de klassesignatuur van het object te gebruiken als typeinformatie. Hierbij moeten we, net zoals bij het laden van code, weer kijken naar de klasse-loading van Java. Een agent kan bijvoorbeeld een bericht van het type Agents.test sturen. Als de ontvanger daarvoor lokaal een andere klasse heeft staan zal de interpretatie van het type, zijnde ``dit is een test bericht'', wel juist zijn maar het gebruik ervan niet meer. De ontvanger zal ervan uitgaan dat bepaalde andere methoden gedefinieerd zijn op het bericht. Als we een globaal filesystem hebben treffen we hier geen problemen aan.
Nu we hebben uitgelegd dat we een unieke typering hebben zullen we uitleggen dat single inheritance vaak te kort schiet om types te overriden. Wat we nog extra nodig hebben zijn interfaces. Stel dat een bepaald bericht moet verstaan worden door meerdere ontvangers in een andere context, bijvoorbeeld een bericht dat naar de spooler gestuurd wordt bedoelt voor één of andere printer. De spooler krijgt berichten binnen die behandeld worden als `printjobs' terwijl elke printer op zich zijn eigen berichttype verstaat, bijvoorbeeld `postscript formaat 1' of `postscript formaat 2'. Dit kan met behulp van het typesysteem van Java uitgevoerd worden als we twee interfaces definiëren, zijnde: PrintAble en PostScriptAble. Als we dan een afstammeling maken van het message type dat beide interfaces implementeerd kunnen we het bericht op twee verschillende manieren behandelen.
Het is duidelijk dat als we deze interfacebenadering toelaten we er op voorhand rekening mee moeten houden. We hebben een methodologie nodig om berichten samen te stellen zodat nieuwe gebruikers gemakkelijk hun eigen interfaces kunnen toevoegen. Dit wil zeggen dat elk bericht behandelt moet kunnen worden als een interface van een of andere soort. Inheritance is iets dat we in deze context niet kunnen toelaten omdat dit de uitbreidmogelijkheden van objecten restricteerd (hoe raar dat ook mag klinken). Laat ons even een voorbeeld geven van deze boude uitspraak.
Stel dat fabricant ![]() postscriptprinters
maakt die berichttypes PostScript verstaan, waarbij PostScript
een afstammeling van Object is. De spooler verstaat enkel
SpoolBare berichten (ook een afstammeling van Object).
In dit geval zijn we niet in staat een bericht te construeren dat
zowel geïnterpreteerd kan worden als SpoolBare
en PostScript
postscriptprinters
maakt die berichttypes PostScript verstaan, waarbij PostScript
een afstammeling van Object is. De spooler verstaat enkel
SpoolBare berichten (ook een afstammeling van Object).
In dit geval zijn we niet in staat een bericht te construeren dat
zowel geïnterpreteerd kan worden als SpoolBare
en PostScript
Hetgeen we eigenlijk doen door te zorgen dat elke klassenaam en interfacenaam uniek is, is het opheffen van het lokale Java typesysteem naar een globaal type-systeem. Aangezien we agents in Java programmeren en het bewezen is dat het systeem flexiebel genoeg is, is dit een goede keuze.
We hebben nu reeds gesproken over het doorgeven van één getypeerd bericht, we zullen nu overwegen om meerdere parameters, samen met hun type, door te geven aan een agent. Dit in overeenstemming met objectgerichte talen waar we in staat zijn meerdere argumenten door te geven aan een methode. Het voordeel van het doorgeven en ontvangen van meerdere parameters is dat we onbenoemde ad-hoc structuren kunnen definiëren. Het nadeel is dan ook dat we een kettingreactie aantreffen als we ooit een parameter moeten toevoegen.
Het is natuurlijk zo dat het gebrek aan meerdere parameters doorgeven gemakkelijk te remediëren is door een berichttype te ontwerpen dat andere berichten bevat, zoals hieronder gedemonstreerd staat.
public class ParametersMessage extends Message
{private Message parameters[];
public ParametersMessage() {super();}
public ParametersMessage(Message m1, Message m2)
{parameters=new Message[2];
parameters[0]=m1;
parameters[1]=m2;}
public ParametersMessage(Message m1, Message m2, Message m3)
{parameters=new Message[3];
parameters[0]=m1;
parameters[1]=m2;
parameters[2]=m3;}
public Message get(int n) {return parameters[n];}
public int Aantal() {return parameters.length;}}
Samengevat hebben we genoeg aan het doorsturen van slechts één object, maar zou het handig zijn mocht het inpakken en het uitpakken van meerdere argumenten automatisch afgehandeld worden.
Differentatie van binnenkomende berichten houd in hoe we binnenkomende structuren en objecten dispatchen naar een bepaalde methode. De gemakkelijkste wijze is geen automatische dispatching te voorzien en alles te laten opvangen door een handleEvent(M) dispatcher.
Een beetje meer differentiatie kunnen we introduceren als we de dispatching van meerdere argumenten reeds automatisch afhandelen. Hierbij zouden we methoden accept1Message(M), accept2Message(M, M), accept3Message(M, M, M) hebben.
Dit heeft nogaltijd het grote nadeel dat we zelf nog moeten dispatchen op het type van de binnengekomen berichten. Hetgeen echt gewenst is is een automatische dispatching waarbij rekening gehouden wordt met het aantal parameters en de types van de parameters.
Een extra mogelijkheid bestaat eruit aan elk bericht een extra string-veld
toe te kennen. Dit stringveld kan dan bepalen welke functie eigenlijk
echt aangeroepen moet worden. Bijvoorbeeld de caller roept procedure
doSomething op met 3 parameters ![]() ,
, ![]() en
en ![]() .
Dit komt overeen met Remote Procedure Calling.
.
Dit komt overeen met Remote Procedure Calling.
Hoe we dit binnenkomende berichten ontrafelen en doorgeven aan de
agent is een ander probleem. We zijn op het ogenblik niet in staat
een bericht om te zetten naar een method-call. Om dit tekort op te
vangen kan een meta level glue hoogst aangenaam ervaren worden. Doch
op dit ogenblik is deze binnen Java nog niet voorhanden zoals beschreven
op pagina .
Hieronder treft u een stuk voorbeeldcode aan dat aantoont hoe we dergelijke glue kunnen implementeren door gebruik te maken van de bestaande middelen. Eerst en vooral worden de nodige methoden zoals sendMessages en handleMessage toegevoegd. De eerste zal zijn parameters encapsuleren en doorsturen. De tweede zal het geëncapsuleerde bericht uitpakken en de juiste methode aanroepen.
void SendMessages(Message m1, Message m2, AgentName Target)
{SendMessage(new ParametersMessage(m1,m2),Target);}
void SendMessages(Message m1, Message m2, Message m3, AgentName Target)
{SendMessage(new ParametersMessage(m1,m2,m3),Target);}
void handleMessage(Message m)
{if (m instanceof ParametersMessage)
{ParametersMessage p=(ParametersMessage)m;
if (p.Aantal()==2)
acceptMessages(p.get(0),p.get(1));
else if (p.Aantal()==3)
acceptMessages(p.get(0),p.get(1),p.get(2));}
else acceptMessage(m);}
We hebben er de voorkeur aangegeven de message passing asynchroon te laten verlopen omdat we grote fluctuaties mogen verwachten in het bereiken van andere agents. We willen hiermee de schrijver van de agent verplichten zoveel mogelijk requests tegelijk uit te vaardigen en niet onmiddellijk te wachten op een antwoord. Hier bovenop kan natuurlijk synchrone message passing gelegd worden indien dit nodig mocht blijken.
Het afhandelen van berichten hangt deels af van hoeveel threads we tegelijk willen starten en hoe we deze willen synchroniseren. We kunnen één queue maken waarvan steeds het topelement afgehaald wordt, waarbij we niet in staat zijn de eerste elementen over te slaan en onmiddellijk een element van type B op te vragen. Hierbij hebben we slechts één thread die message per message afhandelt.
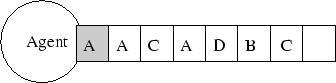
We kunnen anderzijds ook toelaten meerdere berichttypes tegelijk af te handelen, wat inhoud dat we ook meerdere threads moeten starten. Door op voorhand te specifiëren welke types verwacht kunnen worden zijn we toch in staat in te schatten hoeveel threads maximaal gelijktijdig kunnen runnen. Een bovengrens is het aantal methoden gedefinieerd op de agent klasse.
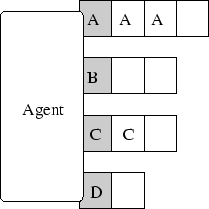
Een derde en laatste mogelijkheid is elk binnenkomend bericht (onafhankelijk van het type) te laten afhandelen in een eigen thread. Het grootste nadeel van deze methode is dat we hierbij onbepaald veel threads kunnen runnen.
Omdat het meest gebruikte systeem vandaag de dag de enkele queue zonder typering is zullen we dit systeem overnemen. Des te meer de twee andere systemen zonder problemen zelf gemakkelijk geïmplementeerd kunnen worden. De standaard event-handling routine van een agent ziet er uiteindelijk als volgt uit:
public void run()
{try {
while(keeponrunning)
{Message m;
if (!receivebox.empty())
{m=receivebox.receive();
handleMessage(m);}}}
catch (Exception e) {}}
Omdat de lijst van gewenste eigenschappen ver van exhaustief was en omdat we niet op voorhand kunnen bepalen wat ``nodig'' is (in die zin dat het onmisbaar handig is), zullen we vanuit het basisframework enkel toelaten berichten op te sturen en te ontvangen die één voor één afgehandeld worden op basis van het aantal argument-objecten.
Onderstaande tabel beschrijft met wat we genoeg hebben, wat we zullen implementeren en wat we in de limiet kunnen verwachten.
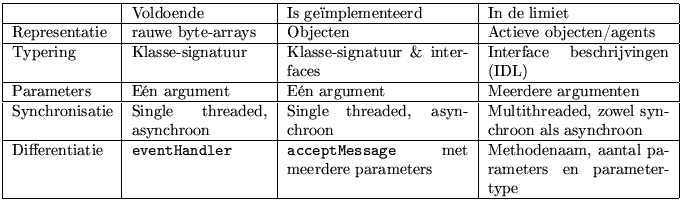
De implementatie bestaat uit twee lagen. De eerste zorgt voor het interne transport van berichten binnen een mailsysteem en maakt gebruik van bestaande netwerk-voorzieningen. Hierbij trachten we een interconnectie tussen agent systemen te verwezelijken. De tweede laag situeerd zich daarboven en creëert een eigen hierarchische topologie nodig voor de name-services. Hierdoor kunnen agents met elkaar communiceren.
De berichtenafhandeling tussen de agent systemen wordt gedaan met behulp van de info.net package die bijgeleverd is bij de Infosphere van Caltech. Zowel het versturen van agents als het versturen van berichten gebeurt hierlangs.
Het versturen van berichten gebeurt asynchroon. Dit wil zeggen dat men gebruik moeten maken van queueing. Verder zal elk bericht dat verstuurd wordt zal toekomen binnen een eindige tijd. Dit is het allom bekende fairness-begrip. Het voordeel van het gebruiken van deze package is dat deze fout-tolerant is, gebruik maakt van serialisatie en zijn berichten zelf reeds typeerd. Als de ontvanger niet meer bestaat wordt automatisch een foutboodschap gestuurd naar de zender.
Door gebruik te maken van deze package kan een interconnectie verwezenlijkt worden die niet noodzakelijk overeen moet komen met bestaande routers en routings-algoritmen. Dit is exact hetgeen we ermee zullen aanvangen. Dit ziet u in volgende figuur.
 Elk agentsytsteem heeft één info.net.mailDaemon draaien
naar waar al de requests (zowel administratieve als andere) naar gestuurd
worden. De routing gebeurt zoals beschreven in het voorgaande hoofdstuk
en ligt bovenop de info.net package.
Elk agentsytsteem heeft één info.net.mailDaemon draaien
naar waar al de requests (zowel administratieve als andere) naar gestuurd
worden. De routing gebeurt zoals beschreven in het voorgaande hoofdstuk
en ligt bovenop de info.net package.
Het agent systeem maakt voor elke agent een standaard mailbox aan die gebruikt kan worden om berichten naar de agent te sturen. Na de (her)constructie van een agent kent de agent zijn eigen mailbox. Het verplaatsen van een agent van de ene machine naar de andere levert hier geen problemen. Het systeem vraagt eerst aan het doel-systeem een nieuwe mailbox en stuurt dan de agent in kwestie er naartoe. Het is dus mogelijk om berichten te sturen naar een agent die net nog niet toegekomen is.
In dit hoofdstuk bespreken we hoe we een agent maken en vernielen, hoe een agent kan uitvoeren en verplaatsen, en hoe processen behandelt worden. Dit wordt vaak als de levensloop van een agent omschreven. Verder bespreken we van welke services agents gebruik kunnen maken en hoe ze die services moeten bereiken.
Dit hoofdstuk bevat een hele reeks voorbeelden die aantonen hoe een agent systeem gebruikt kan worden. We zullen vaak praten over actieve files zijn in plaats van passief. Een actieve file is er een waarbij een proces geassocieerd wordt met een hoop data. 14
Een agent kunnen we maken door aan het lokaal runnende agent systeem te vragen een agent te instantiëren. Elke agent die gecreëerd wordt heeft dus een agentnaam waarvan de instance name naar de lokale machine verwijst en het agent field zelf gekozen kan worden. Deze naam zal hij steeds blijven behouden, zelfs na het verplaatsen naar andere machines. Onderstaande maakt een agent van het type ``Agents.fileAgent'' en geeft hem de naam ``TestFile''.
agentSystem.createNewAgent("Agents.fileAgent","TestFile");
Het agent systeem zal als hij de agent Agents.fileAgent wil
maken een standaard instantie van deze klasse aanmaken door new()
aan te roepen. Nadien zal hij de nodige fields, zoals de agentnaam
![]() , invullen en mailboxen creëren.
We zijn niet in staat parameters mee te geven bij de constructie van
een agent. Dit omdat we evengoed de agent een bericht kunnen sturen
dat als initialisatie kan doorgaan. Dit maakt de scheiding agent laag
en Java laag duidelijker. De initialisatie van een agent is iets dat
expliciet moet gebeuren en niet op basis van een taal-feature, zoals
constructors.
, invullen en mailboxen creëren.
We zijn niet in staat parameters mee te geven bij de constructie van
een agent. Dit omdat we evengoed de agent een bericht kunnen sturen
dat als initialisatie kan doorgaan. Dit maakt de scheiding agent laag
en Java laag duidelijker. De initialisatie van een agent is iets dat
expliciet moet gebeuren en niet op basis van een taal-feature, zoals
constructors.
Onderstaand is een deel van de FileAgent. Hierin ziet u hoe we berichten kunnen versturen naar andere agents en hoe we zelf berichten moeten dispatchen. De creatie verloopt zoals hierboven beschreven. De initialisatie kan gebeuren door het bericht `LOCALFILE' op te sturen. Data kunnen we opvragen met behulp van `GETDATA' waarachter de naam van de ontvanger-agent moet komen. `SETDATA' herschrijft de data die de agent bij zich draagt.
public class FileAgent extends Agent
{private String fileName;
public void localFile(String filename)
{fileName=filename;}
void SetData(DataMessage dm)
{if (fileName!=null)
dm.writeToFile(fileName);
else fileName=dm.writeToFile();}
void GetData(AgentName m)
{DataMessageImpl dm;
dm=new DataMessageImpl();
dm.readFromFile(fileName);
SendMessages(new StringMessage("DATAOF"),getAgentName(),dm,m);}
public void acceptMessages(Message m1, Message m2)
{if (((StringMessage)m1).data().compareTo("GETDATA")==0)
GetData(AgentName.parseString(((StringMessage)m2).data()));
if (((StringMessage)m1).data().compareTo("SETDATA")==0)
SetData((DataMessage)m2);
if (((StringMessage)m1).data().compareTo("LOCALFILE")==0)
localFile(((StringMessage)m2).data());}}
Een eerste drawback die we tegenkomen is dat we een agent niet zomaar
remote kunnen aanmaken. Stel bijvoorbeeld dat we een file `remotefile'
hebben, waarvan we weten dat hij op een andere host, bijvoorbeeld
![]() , aan te treffen is. Indien we voor deze
file een remote agent willen maken zijn we daartoe niet in staat.
We moeten altijd een lokale agent maken en die dan verhuizen naar
het andere agent systeem. Dit wil zeggen dat we geen remote execution
hebben omdat het overbodig wordt geacht.
, aan te treffen is. Indien we voor deze
file een remote agent willen maken zijn we daartoe niet in staat.
We moeten altijd een lokale agent maken en die dan verhuizen naar
het andere agent systeem. Dit wil zeggen dat we geen remote execution
hebben omdat het overbodig wordt geacht.
Er treed natuurlijk wel een ander probleem op.
Als een agent op verplaatsing gaat werken en op een andere host agents
begint te spawnen, hebben we het probleem dat er name-clashes kunnen
optreden. Bijvoorbeeld: als agents ![]() en
en ![]() beide op
beide op ![]() toekomen en daar allebei een agent willen creëeren met de naam
toekomen en daar allebei een agent willen creëeren met de naam
![]() hebben we een geweldig naam-conflict.
Met andere woorden: als we toelaten dat agents op andere hosts dan
hun lokale machine zomaar willekeurig benoemde agents kunnen aanmaken
wordt onze name-space aan flarden gerukt.
hebben we een geweldig naam-conflict.
Met andere woorden: als we toelaten dat agents op andere hosts dan
hun lokale machine zomaar willekeurig benoemde agents kunnen aanmaken
wordt onze name-space aan flarden gerukt.
Om de namespace op een bepaalde
machine niet uit te putten zijn we dus genoodzaakt de eigenaar en
de creatie-machine beide in één agentname te steken. Hiervoor
kunnen we nog steeds de agentnames gebruiken die we beschreven hebben.
Zijnde ![]() . We moeten enkel
de lokale agentname expanderen naar
. We moeten enkel
de lokale agentname expanderen naar ![]() .
Het toevoegen van deze extra ``created-by'' informatie gebeurt
automatisch door het agent systeem.
.
Het toevoegen van deze extra ``created-by'' informatie gebeurt
automatisch door het agent systeem.
Als nu agent ![]() 15 een andere agent creëert op een remote machine
15 een andere agent creëert op een remote machine ![]() dan zal de gecreëerde agent het volgende patroon hebben:
dan zal de gecreëerde agent het volgende patroon hebben:
![]() .
.
Het agent systeem zorgt dus dat aan een naam een agent gebonden wordt. We kunnen nu ook toelaten een agent zijn naam te herbinden. Dit stelt ons in de mogelijkheid een agent zijn gedrag radicaal te wijzigen. Aangezien een agent zelf verplicht is binnenkomende calls af te handelen kan zijn levensloop op transparante wijze verdergezet worden. Het nut van dergelijke ``self''-wijziging zal duidelijk worden in de paragraaf over proxy agents.
We zullen nu een voorbeeld geven dat het nut van deze herbinding duidelijk maakt. Binnen een groot netwerk is het vanwege efficiëntieredenen niet ver gezocht bepaalde files te dupliceren. Hier bestaan grosso-modo twee benaderingen voor. Enderzijds het mirrorren van een file en anderzijds het repliceren door een master.
Het mirrorren van een file is een methode waarbij de client updates vraagt aan een server. Het synchronizerern van de mirror met zijn master gebeurt dus volledig aan client-zijde.
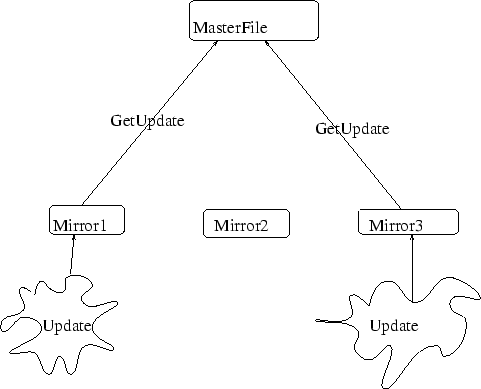
Bij een replica worden de updates zelf opgestuurd door een master-file. Het repliceren van een file bied de mogelijkheid dat de eigenaar van de master alle mirrors van een file update indien cruciale aanpassingen gebeuren.
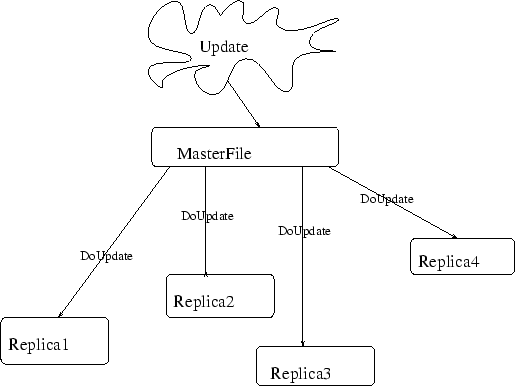
De owner van een replica komt overeen met de owner van de master. Dit in tegenstelling tot een een mirror waarbij de replicatie zelf gecontroleerd kan worden. Nu kan het nuttig zijn op een bepaald ogenblik een replica om te zetten naar een mirror om zelf ``owner'' te worden van een file. Hiervoor blijk een self-rebind zeer nuttig te zijn. Hieronder staat de methode becomeMirror uit de klasse ReplicatedFileAgent die demonstreert hoe dit gedaan kan worden.
public void becomeMirror()
{
// loskoppelen van de master-file
unregisterReplica();
// een mirror maken
MirroredFileAgent mfa=new MirroredFileAgent(MasterFile);
// mezelf bevriezen en alle processen stoppen
Freeze();
// self wijzigen
changeSelf(mfa);
// en de nieuwe agent leven inblazen
mfa.Thaw();
}
Nu we reeds agents kunnen maken en herbinden zijn we bijna in staat agents te verplaatsen. We hebben enkel nog een beschrijving nodig van de processen die zich afspelen binnen een agent. Voordat een agent namelijk kan verplaatsen moeten we in de mogelijkheid zijn al zijn gestartte processen te stoppen. We zouden de processen zelf prompt kunnen afbreken en een perfect migratie uitvoeren, maar dat is iets dat buiten het bereik van de Java VM ligt. Dus zijn we verplicht de agent te betrekken in het stoppen en starten van zijn processen.
De Freeze methode is er een die voor het stoppen van de agent moet zorgen. Eens de controle teruggegeven wordt van Freeze mogen we alle processen killen en de agent als serialiseerbaar beschouwen. Als we een agent weer willen ontdooien, na het stilleggen van zijn processen, kunnen we de Thaw methode aanroepen. In deze methode kan een agent zelf initiatief nemen om meerdere processen te starten, zoals gevisualiseerd staat in volgende figuur.
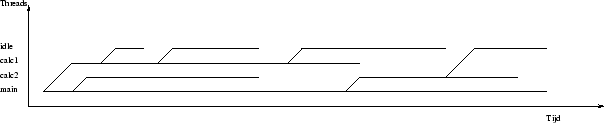
Zowel freeze() als thaw() moeten de controle teruggeven eens hun werk verricht is. Bij thaw() wil dit zeggen dat de nodige agentprocessen gecreëerd zijn, bij freeze() wil dit zeggen dat de agent beschouwd mag worden als stilgelegd.
Ter illustratie tonen we hoe de refresh-loop van de MirroredFileAgent wordt bevroren en ontdooit. Deze refresh-loop is nodig om bijvoorbeeld om het uur de data weer te updaten.
public void Thaw()
{
super.Thaw();
refresh=new RefreshLoop(10000);
refresh.start();
}
public void Freeze()
{
refresh.stopasap();
super.Freeze();
}
Nu zijn we aanbeland aan de sectie waarin we bespreken hoe een agent verplaatst. Essentieel komt het erop neer dat we de Java serialisatie gebruiken om een agent te serialiseren, eens al zijn processen gestopt zijn. Om de bovenbeschreven fileagent te verplaatsen kunnen we volgende code schrijven:
AgentSystem.MoveAgent(Agent,new VMName("igwe8.vub.ac.be",8080));
We hebben ooit gekozen berichten niet voor te stellen als agents (9.1.1), nu zullen we ook verbieden agents door te sturen als berichten, juist omwille van de moeilijkheden die we hebben om de processen stil te leggen en te herstarten. Het verbod tot het verplaatsen van agents als bericht treffen we ook aan in het Actor computationele model waarbinnen we geen actors mogen versturen als bericht. (Zie [31])
Dit niet kunnen doorsturen van agents als bericht is op zich geen probleem omdat we steeds de naam van een agent kunnen doorsturen. Hetgeen wel een probleem vormt is hoe een agent zich moet loskoppelen van zijn omgeving. Als bijvoorbeeld een actieve webpage (een actieve .html file) een lokale mailer gebruikt dan zal deze webpage na een verplaatsing naar een andere host een andere mailer moeten gebruiken om zijn doel te bereiken.
Dit herbinden van services is iets wat we niet transparant kunnen aanbieden. We zullen, telkens voordat een agent verplaatst wordt, hem inlichten dat hij verhuist gaat worden door de methode preMove() aan te roepen. Hierbij kan hij zich ontrekken aan de omgeving waarbinnen hij zich geïntegreerd had. Als een agent aankomt op een host wordt de methode postMove() aangeroepen zodat de agent zichzelf weer kan integreregen binnen het nieuwe systeem.16 Een agent wordt nooit geactiveerd op zijn tussenstations, en dus worden zijn preMove en postMove methoden ook niet aangeroepen. De enige impact die hij daar heeft is een lokale wijziging van de routing-tabellen.
Ter illustratie van deze preMove en postMove tonen we hoe binnen deze methoden een message gestuurd kan worden naar een algemene tracer die bijhoud waar de agent zich op dat ogenblik bevind.
public class FileAgent extends Agent
{
public void preMove(VMName from, VMName to)
{
SendMessage(new StringMessage("LOCATION -> "+ to),
new AgentName("igwe8.vub.ac.be",8080,"Printer"));
}
public void postMove(VMName now)
{
SendMessage(new StringMessage("-> LOCATION "+ now),
new AgentName("igwe8.vub.ac.be",8080,"Printer"));
}
}
We kunnen nu agents verplaatsen en aan procescontrole doen. Hetgeen we nu nog willen is dat we aan planning kunnen doen en op een hoger niveau beslissen wanneer een agent naar waar moet verhuizen. We willen dit op een flexiebele wijze aanbieden zonder de distributie te doorbreken. De idee van proxy agents is hier uitermate geschikt voor. (waarbij proxy enkel gebruikt wordt als interface-omleiding en niet meer om location transparency te voorzien).
Stel bijvoorbeeld dat we een actieve webpage hebben, die afhankelijk van de binnenkomende requests, verhuist naar de meest vragend host. Enerzijds moeten we in staat zijn een proxy agent op transparante wijze tussen de agent en het omliggende systeem plaatsen. Hiervoor kunnen we de self-rebind gebruiken, zoals geïllustreerd in onderstaand code fragment.
public class FileAgent extends Agent
{
public void setProxy()
{
ProxyFileAgent pfa=(ProxyFileAgent)
createAgent("Agents.agent3.ProxyFileAgent",MyName+"_nonproxy_");
pfa.setContact(MyName);
swapNames(this,pfa);
}
}
En anderzijds moet de proxy agent een zekere planning verwezenlijken. De proxy moet aan de hand van het omleiden van berichten bepalen wanneer de agent moet verhuizen. Onderstaande is een hyperactieve manier waarbij de agent, bij elke request die binnenkomt, naar de oorsprong van de request verhuist.
public class ProxyFileAgent extends Agent
{
void GetData(AgentName m)
{
SendMessages(new StringMessage("MOVETO"),
new VMName(m.getHost(),m.getPort()),contact);
}
public void acceptMessages(Message m1, Message m2)
{
if (m1=="GETDATA") GetData((AgentName)m1);
SendMessages(m1,m2,contact);
}
}
Met behulp van dergelijke proxy agent kunnen we dus aan caching van resultaten doen, replicatie management kan erin voorzien worden en planning wanneer een agent naar waar moet verhuizen is mogelijk.
Het ontbinden is de laatste fase in de levensloop van een agent. Hierbij moet de agent zorgen dat hij al zijn resources die hij gebruikt weer vrij geeft en al de nodige instanties inlicht. Een lokaal werkende agent heeft hier gene probleem mee. Die licht zijn agent systeem in dat hij niet langer meer hoeft te bestaan. Een op afstand werkende agent heeft ook het pad naar hem weg te werken. Al de name servers en routingstabellen die naar hem wijzen moeten geupdated worden.
Om dit te verwezelijken zouden we kunnen opleggen dat de agent enkel mag sterven op de machine waar hij gecreëerd werd, doch we zullen dit niet doen omdat dit een aspect is van de location control dat door het agent systeem zelf afgehandelt moet worden. Agents moeten dus steeds verwijdert kunnen worden door aan het agent systeem deleteAgent te vragen.
Het definiëren wanneer een agent de geest moet geven is een aspect dat nader besproken dient te worden. Het blijkt onmogelijk te zijn een garbagcollector te schrijven die zegt wanneer een agent verwijdert mag worden. Dit enerzijds omdat we geen vast gedefinieerde root hebben en anderzijds omdat de agent zijn eigen verantwoording vormt voor zijn bestaan.
In dit hoofdstuk hebben we expliciet de levensloop van een agent in ons framework beschreven. Samengevat wordt een agent geboren, waarna hij zijn processen kan beheren en aan zijn taakuitvoering werken. Indien nodig kan hij verplaatsen of verplaatst worden. Uitdeindelijk kan hij ook nog vernield worden.
We hebben laten aanvoelen dat het onmogelijk is gebruiker resources en resource binding transparant te maken omdat de gebruiker vaak zelf in de pap wil brokken. Daartoe hebben we preMove en postMove methoden geïntroduceerd. We hebben ook duidelijk gemaakt dat we onmogelijk een garbage collector kunnen schrijven voor agents, zonder extra voorzieningen toe te voegen aan deze agents. Het bepalen wanneer een agent moet sterven is iets dat door de auteur van de agent zelf moet worden beschreven.
In deze thesis hebben we getracht een agent systeem te ontwikkelen op basis van een reeks bestaande agent systemen. Als voertaal hebben we Java genomen, hoofdzakelijk omdat deze voldoende technisch support bied om op hoger niveau te kunnen redeneren over mobiele code. Zonder Java als backbone zou deze thesis er heel anders uitzien, heel wat dikker, omdat we verloren zouden lopen in allerhande low-level technische details.
Om een eigen framework te kunnen ontwikkelen hebben we een reeks agent systemen zoals Mole, de Aglet Workbench en de Infosphere onderzocht. Elk framework had zijn eigen voor en nadelen die we samengevat hebben in Hoofdstuk 7. Uitgaande hiervan hebben we een agent systeem geconstrueerd dat er als volgt uit ziet.
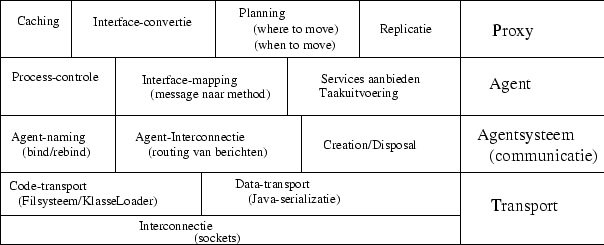
We treffen op het laagste niveau de transportlaag aan, waarbinnen gefocuseerd wordt op het verplaatsen van data en datastructuren van de ene machine naar de andere. (dit werd behandeld in Hoofdstuk 3). Een niveau hoger treffen we het agent systeem aan dat zorgt voor een unieke globale naming strategie (Paragraaf 8.1) en een globale agent interconnectie. (Paragraaf 8.2) Verder zorgt het agent systeem ook voor het aanmaken en vernielen van agents.
Tot daar is het werk achter de schermen verricht. Vanaf nu moet men als schrijver van een agent tussenbeide komen. Dit houd in dat men zelf de process controle van de agent moet doen. Een aspect waarmee we nog verveeld zitten is de interface mapping17, die ook nog moet gedaan worden door de auteur van de agent.
Een niveau hoger kan een auteur zijn eigen agent monitoren en bijsturen door een proxy agent te installeren die zich niet meer bezig houd met wat er moet gedaan worden maar wel met wanneer iets uitgevoerd moet worden. We kunnen verwachten dat caching, interface convertie, planning en replicatie hieronder zullen gebracht worden. De idee van zulk een proxy agent is enkel mogelijk als we toelaten de self pointer te wijzigen, wat er in een agent systeem op neerkomt dat we een agentname moeten kunnen herbinden.
Eén zaak die zeer sterk naar voor kwam in deze tekst is dat we dringend moeten nadenken hoe we geschikte routingtopologiën ontwerpen die toelaten dat multi agents met elkaar kunnen communiceren op een positie onafhankelijke basis. We hebben aangetoond dat dergelijke algoritmen gemaakt kunnen worden en hebben er ook zelf één ontworpen. Nadien zijn we verder gaan kijken naar huidige bestaande gedistribueerde mobiele object systemen. Het is blijkbaar een tendens bij de ontwerpers van agent systemen dat men alle bestaande kennis van gedistribueerde systemen vergeet en moedwillig weigert deze ter hand nemen. Aangezien het duidelijk is dat agent systemen sterke analogieën vertonen met gedistribueerde object systemen kan men er duidelijk in de leer gaan.
Een gedachte die naar voor kwam is dat we, indien we in een Java agent omgeving werken, we geen klasse inheritance willen gebruiken om berichten tussen agents door te geven. Om berichten voor te stellen maken we beter gebruik van interfaces. De idee hierachter bestond eruit dat we niet noodzakelijk in staat zijn af te stammen van het berichttype dat één van de ontvangers verwacht. We hebben dus een stelregel uitgevaardigd die zegt dat elk bericht volledig bereikbaar moet zijn door een interface erop gedefinieerd.
We zullen nu trachten een aantal gebreken van dit agent systeem op te sommen. De meeste onvolkomenheden zijn te wijten aan de beperkte tijd en aan het veel te open domein van agents. We hebben onszelf op vele plaatsen dus moeten beperken.
Een eerste zaak die verloren gelopen is, is replicatie van agents. De hoofdreden om hiermee geen rekening te houden, is dat replicatie inhoud dat we weten wat het doel van een agent is, dat we dus zijn services kunnen ontdubbelen, en dit op zulk een wijze dat alle duplicaten semantisch consistent blijven. Dit is een topic dat niet onmiddellijk haalbaar is.
Het aspect security is er één waar we zwaar over gekeken
hebben. Dit is een domein dat zo verschrikkelijk complex is dat we
zelfs niet getracht hebben een minimale security te voorzien. Het
probleem van security doet ons trouwens licht denken aan het deadlock
probleem. Systeem ![]() ken perfect deadlockvrij zijn, systeem
ken perfect deadlockvrij zijn, systeem ![]() kan dat ook zijn, doch de combinatie van beide kan een deadlock veroorzaken.
Hetzelfde geld voor security. Systeem
kan dat ook zijn, doch de combinatie van beide kan een deadlock veroorzaken.
Hetzelfde geld voor security. Systeem ![]() kan perfect secure zijn,
systeem
kan perfect secure zijn,
systeem ![]() kan dat ook zijn, maar systeem
kan dat ook zijn, maar systeem ![]() (vertrouwd door beide)
kan de security van beide grondig doorbreken.
(vertrouwd door beide)
kan de security van beide grondig doorbreken.
Andere zaken waarmee we in deze thesis geen rekening gehouden hebben, zijn het specifiëren van protocols en de interfacing met andere talen dan Java. Bij de routing hadden we misschien kunnen nadenken over een mogelijke multi cast feature. We hebben ook maar één routing-topologie bestudeert en niet verder gezocht op mogelijke betere topologiën. De voorgestelde hierarchische stervorm is nogal beperkt.
Alhoewel de fysieke verandering van lokatie van software (zijnde programmatuur en toestand) technisch reeds mogelijk is, blijft de migratie strategie een open vraag. In de huidige stand van zaken ligt deze beslissing volledig bij de agent zélf: de agent zal tot migratie overgaan op basis van beschikbare hardware resources, interactie met andere agents of de eigen inwendige toestand. Het gedrag van zo een agent is dus volledig vastgebakken binnen de code en omwille van zijn autonomiteit is deze zijn enige migratiestrategie.
Deze zuiver autonome voorgeprogrammeerde migratiestrategie zal meestal aanleiding geven tot een alles behalve optimale globale verdeling van agents over een computernetwerk. Dit zal dan ook tot gevolg hebben dat de lokale performantie van de agent hieronder lijdt. Dit is analoog aan de klassieke spanning tussen bijvoorbeeld micro- en macro-economie en wordt ook geïllustreerd door het bekende prisonner's dilemma. In beide gevallen moet het gebrek aan globale kennis gecompenseerd worden door een leerproces. Voor onze agents betekent dit dat lokale waarnemingen via verwerving van kennis dienen omgezet te worden in een negotiatie- en migratiestrategie. Klassieke computernetwerken bezitten dit soort van strategie op het niveau van de host machines, van routers of bridges. In ons geval moet deze vervat zijn binnen individuele softwarecomponenten die totaal onafhankelijk van de onderlinge hardware evolueren. Op dit ogenblik ontbreken de formalismen of programmatie-idiomen om dergelijke nieuwe vormen van routing en load-balancing te bestuderen of te verwezenlijken.
Een allereerste doel van een eventueel verder onderzoek zal bestaan uit een uitputtende studie van de parameters die het probleem bepalen: welke factoren bepalen de performantie van een potentieel migrerende agent? Hierbij kan men zowel denken aan performantieaspecten van de beschikbare hardware (geheugen, schijfruimte, cpu-tijd, netwerk toegangstijden...), als aan samengestelde performatiebegrippen zoals de gemiddelde doeltreffendheid van agents of een sommatie van verschillende formele performantie-eigenschappen van agents [23]. Deze laatste moeten toelaten om op een macroscopische schaal formeel te kunnen redeneren over de performantie van agents of clusters van agents.
Eens de relevante criteria vastgelegd kunnen worden, dienen deze gekoppeld aan de handelingen die kunnen genomen worden om zowel de lokale als globale performantie op te drijven. De vraag die zich hier stelt is welke agent wanneer [21] waarheen moet of mag migreren. Om het verband tussen deze criteria en handelingen beter te begrijpen dient de speltheorie zich aan als kandidaat-formalisme. Deze reeds dikwijls toegepaste benadering geeft een goed inzicht in de verbanden tussen het lokale en globale niveau wanneer een reeks wedijverende agents handelingen dienen te ondernemen op basis van een reeks vooropgestelde beslissingscriteria. Om het verband tussen de criteria en de handelingen echter computationeel op te lossen, is een klassiek-algoritmische benadering niet aangewezen: zelfs in het statische geval (begrensde en niet evoluerende topologie) is het probleem NP-compleet. Zodoende zullen we onze toevlucht moeten zoeken tot heuristische benaderingstechnieken zoals genetische algoritmen [24] en/of neurale netwerken [25].