Below my simulation of the 4 cases: The yellow line is the lens. The blue pattern is the simulated interference pattern
Option A & B are the concave lenses. Options C & D the convex lenses. In figure A we see the fast phase trend in front of the bulge, with a low phase trend behind it. These are not visible in the three other options. However: the difference between A & C (concave vs convex) is not necessarily easy to spot in this simulation. To figure that out very likely the 2D interferogram has to be looked at to figure out which lines are ‘pulled straight’
All in all: great video which inspired me to write some code.
BpmDj… my brainchild… bringing in no money… So I am looking for free tools.
ClickOnce
ClickOnce is a technolog by microsoft to easily start and upgrade an application. It is remarkably similar to the packaging solution I created in Java. At start time it will check what is available and download it if the user wants so. I like this.
ClickOnce of course requires ‘code signing’ certificates, which are really difficult to make. And without shelling out money, windows smartscreen will always copmplain when the application is installed or upgraded. Yet… I will not spend 100EUR/Year just to remove that dialog.
A solution would be to use no installer, and then secretly upgrade the application behind the users back. Nevertheless, even then I will get the ‘untrusted application’ message, so I will assume BpmDj users are smart (they are) and will probably realize that it is pointless to spent so much money on something they will accept anyway.
BpmDj… my brainchild… bringing in no money… So I am looking for free tools.
In order to figure out how much information assemblies throw around, just have a look at https://www.jetbrains.com/decompiler/ It basically returns me the original source code, including all variable names and everything else that could have been thrown out. Therefore, an obfuscator is really necessary. http://www.dotnetstuffs.com/best-free-obfuscator-to-protect-net-assemblies/ had a list of interesting possibilities.
Dotfuscator (A Lead to Sell)
The microsoft site refers to ‘DotFuscator’; and let me tell you.. the community edition is bullshit. The entire thing is one big lead to sell you their product. It starts with a forced registration (you have to give a valid emailaddress). Then when you are in the application, you only see advertisment, not a lot of real useful obfuscation going on. And lastly, when I ran it on BpmDj it wasn’t even able to go through it because ofg ‘mixed assemblies’ I am sure I could set up a joint project with preemtive solutions, in which I would of course pay them, but honestly… don’t bother with this bullshit. The community edition doesn’t do what it pretends it will do.
Obfuscar (No XAML)
Obfuscar tries to map as many input names to as few output names as possible. ‘Massive overloading’ as they call it. https://code.google.com/archive/p/obfuscar/
At first glance this seems a dead end.. Last release was 11 years ago. However stack overflow posts still discuss it in 2018. Ha no, it seems to have moved to https://github.com/obfuscar/obfuscar
Amazingly enough, after getting a simply configuration it actually ran through the entrire shebang of assemblies and generated 1 output. That output could even start ! Yet it did hang at the splashscreen. Attaching a debugger showed that all threads had been started properly, so I assume either I access a dynamic resource by name (I do have some explicit invokes laying around), or the XAML bindings were seriously fucked up. This is something I should test somewhat further, because if this works we are done.
Oh the horror. The default configuration doesn’t actually obfuscate shit. All identifiers were still present, despite the fact that it claims it had a ‘mapping’. Probably it kept all public properties public as they were without renaming them.
I also figured out that the BAML/XAML tree is still stored in the assembly as it was present in the original solution, so no reordering takes places in any way. Not a total failure, but not great either because of this.
ConfuserEx (Abandonded)
Finally something that is not a landing page. Huray ! Last update… 26 January 2019.. still it might work and it is open source. The projecct has indeed be discontinued since 1. July 2016.
In any case, a run of it did behave similarly as Obfuscar. The application started and didn’t get further,probably because of the missing DLL’s. I might need to fix that problem if no obfuscator gets through it. In any case, the XAML was effectively gone after obfuscating; or the dotPeek decompiler stopped trying. I am not entirely sure what it is yet.
After spending some hours on this problem, the problem seems to be in the renaming strategy used. I am not yet sure whether I will blame confuserex or my own program, given that Obfuscar had exactly the same error as this one. Then again maybe they both are based on the same source, so they might both be suffering from the same bug.
In any case, performing a ‘none’ protection did not damage the original assembly, which is already a good sign. Also nice was that there was a debug protection in place which caused the applciation to bark when a debugger tries to connect.
Skater Light (Does not obfuscate at all)
Also Skater is a piece of software to buy. They do have a free version, named SkaterLight. Oddly enough… this feels a lot like chinese spyware. Seriously.
it worked at the first attempt. So I was a bit skeptical… I decompiled the generated assembly and lo and behold the thing was just not obfuscated whatsoever.
after installing it, it actually ran with elevated privileges (I know that because I could not read the generated assembly)
Yes… ‘Full Obfuscation’Just don’t believe it
Dead Ends
Eazfuscator (not free) – Next is Eazfuscator because they seem very eager to actually deal with the WPF/XAML issue. Oh well.. forget it. Not free anymore. This is the point where I considered whether it would be possible to use a decompile tool to decompile an obfuscator, remove the licensing restrictions and continue. There is a certain beauty to this approach: if the obfuscator sucks, then we can easily do that, which makes it pointless to actually use then
CodeFort (disappeared) – was mentioned as another option which works well with XAML. Yet, latest udpate on the twitter feed was 2010 and the domain itself became a lnading page.
Agile.NET (non free)
FXProtect (disappeared)
ILProtector (not free) – has gone commercial since version 2.0.17
CodeVeil – encrypts the DLL before executing it. In the end this might be a better option than ‘obfuscating’ it. Drawback is of course that we have a single point of failure. Another drawback is that it is a chinese product and only a trial version.
In BpmDj we load objects on demand: every time a particular object is accessed we load it from the database. This process happens automatically, and is implemented through a dictionary which maps an object id to a runtime representation.
In Java, this dictionary was a WeakDictionary, which is a dictionary from which values can be removed by the garbage collector. When when they got removed and the program accessed that object again, we would load it fresh from the database. This poor man caching is not particularly good because any garbage collect will remove all loaded (but unreferenced) objects, forcing the program to reload those object again. Even if the particular object is often used.
To solve that, we could force references to stay in memory by means of a round robin queue. Every time an object is accesed it is put in the next position in the buffer. As such, we ensure that the cache keeps X instances alive.
Sadly that strategy is unable to deal with a burst of requests. Any often used object will simply be pushed out of the buffer when a batch of new objects is loaded (like for instance when the song selector opens).
To alleviate this problem, we can, with each access, gradually increase the stickiness of a cache item. This idea turned out to be fairly efficient:
every entry has a position in the buffer. Whenever the entry is hit, it moves to half its original position.
every new element is placed in the middle of the buffer.
This strategy leads to a distribution where often used elements are in front of the buffer. Lesser used elements slowly walk their way out of the buffer until they are evicted. To avoid that items become too sticky (e.g: there can be items that have just enough been accessed to never leave the buffer again), it is useful to add a random element to this
reposition an element to a random position between 0 and ratio * originalRank.
One could argue that having too many object id’s and too few actual objects would be a cause of concern, and it clearly is. Nevertheless, there often is a space tradeoff between holding on to an object and using its id.
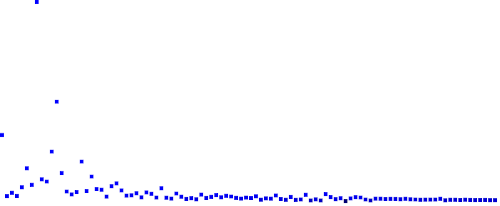
The image shows the buffer of a cache of capacity 100, with 800 distinct element randomly accessed. The access pattern was shaped according to a power law distribution. The front of the cache are those that are more sticky than the later part of the buffer. The height of each entry indicates its priority in the emitter.
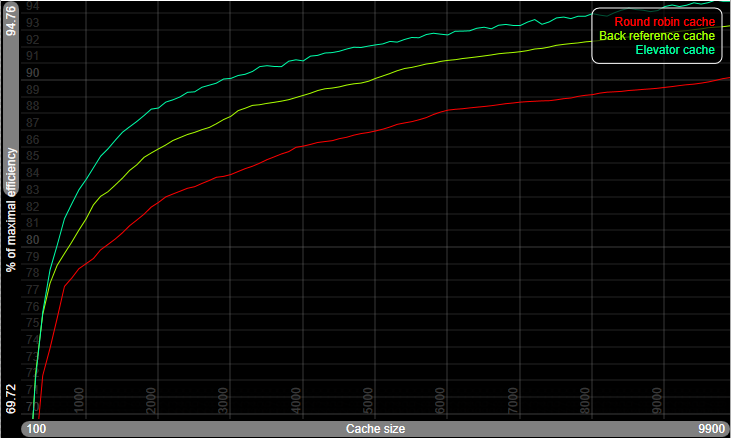
The following picture shows the difference between 3 types of cache. The first is the roundrobin mentioned earlier, the second is a cache which keeps backreferences and the elevator cache is the one implemented here.
The data on which this was ran was the retrieveal of all startup objects BpmDj need, including the opening of the song selector. The total object count was 133632, of which 70291 unique ones.
After having tested both of them extensively I can draw the following conclusion: MSTest is definitely the winner. Why ?
XUnit
buggy as hell. For a testframework this is kinda weird
very very slow
really confused about the tests that are available
No standard output. Yes I know you can redirect it, still they should not steal my debug output in the first place.
Different assertions than MSTest, and they are badly implemented at that (E.g: an assertion finding the content of a collection will simple iterate over all elements. It is truly painful to see how far computer scientists have sunken)
crashes VS2019 when in auto-hide
Talks about [Theories] and [Facts] instead of [TestMethod], just some ‘cool’ jargon and indeed far removed from reality.
MSTest
Does not have the same level of ‘we are so cool but can’t program’ fuckery as Xunit
Allthough this post is small, nobody seems to care to say how bad xUnit exactly is.
At the moment the style is created, NormalTextColor is not defined yet. And so it stays whenever later that style is applied. If we swap the NormalTextColor definition and the Style then it will be a fixed yellow.
Dynamicresources are resolved whenever necessary
If we modify the StaticResource in a DynamicResource, then that example will behave correctly, and every textblock will have a yellow foreground.
This means that any textblock within the stackpanel will be colored red, while the textblocks outside the stackpanel yet inside the window will be orange. And ifg the application.xaml is defined as in our first example, then any other window will be yellow.
It might be necessary to restyle multiple controls
Whenever a textblock is used it will have the provided style. A label however has its own foreground color defined, and so requires an extra style.
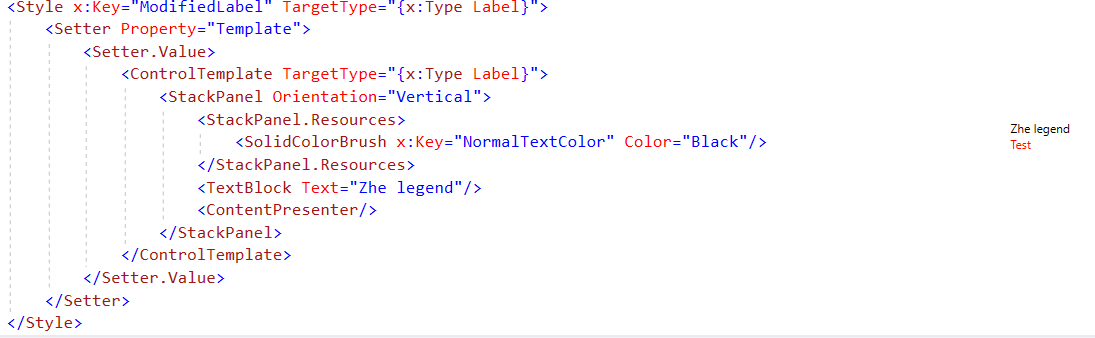
ControlTemplates provide a way to render a particular element differently. The dynamic lookup still goes from the lexical point of insertion up the logical tree. Thus the following fragment
Will render both the ‘Zhe legend’ as well as the actual content of the label using the same dynamicresource: that is they will both have the same color, even if the controltemplate was defined in a different file. (One could expect that ‘Zhe Legend’ would follow a lookup hierarchy going from the definition of the template, while the ContentPresenter would follow a different hierarchy)
The logical parent with controltempaltes
The logical parent of the contentpresenter is the controltemplate, which is the same as the control being templated. Thus if we set the template of a label to something, and then define a resources in the controltemplate (as ControlTempalte.Resources), then these resources are part of the label, and thus are visibly to dynamicresources applied to the contentpresenter.
Yet, if we place the resources to a subelement within the controltemplate, then they are not part of the label, and thus not part of the logical chain of parents from the contentpresenter.
Under the assumption that the default color has been set to red in the App.xaml, we have two ways to define a controltemplate, with two different results
Who has priority ?
Because both the ControlTemplate and the original instantiation both access the same resource dictionary frame, it is useful to figure out who has priority. The answer is: the controltempalte its resources are applied first, afterwards those defined in the actual instantiation of the control.
Most people used an internal javafx FontMetrics class, which has been deprecated in version 9 of the jdk. That means that your app that relied on this will simply not work anymore. Below is a simple replacement that will provide the computeStringWidth as well as ascent, descent and lineHeight. The produiced values are exactly the same as if they were called from the FontMetrics class itselve.
I have been struggling with an “interesting” javafx render problem. In BpmDj, given enough updates, the rendertree would partially stop updating. It was clear this was a concurrency bug, yet one that was not my fault. As a preliminary solution to fix this I would grab a screenshot everytime I would add a node. Recently however that solution no longer worked and the dirty logic would be so fucked up that elements which should be visible were not visible. It was even possible to have a font change its color halfway through its rendering.
So I started to look around for javafx options, and there are a few of them that proved to be useful.
What
Flag
Default
VSync
prism.vsync
true
Dirty region optimizations
prism.dirtyopts
true
Occlusion Culling
prism.occlusion.culling
true
dirtyRegionCount
prism.dirtyregioncount
15
Scrolling cache optimization
prism.scrollcacheopt
false
Dirty region optimizations
prism.threadcheck
false
Draws overlay rectangles showing where the dirty regions were
prism.showdirty
false
Draws overlay rectangles showing not only the dirty regions, but how many times each area within that dirty region was drawn (covered by bounds of a drawn object).
prism.showoverdraw
false
Prints out the render graph, annotated with dirty opts information
prism.printrendergraph
false
Force scene repaint on every frame
prism.forcerepaint
false
disable fallback to another toolkit if prism couldn’t be init-ed
prism.noFallback
false
Shape caching optimizations
prism.cacheshapes
complex
New javafx-iio image loader
prism.newiio
true
Verbose output
prism.verbose
false
Prism statistics print frequency, <=0 means “do not print”
prism.printStats
0
Debug output
prism.debug
false
Trace output
prism.trace
false
Print texture allocation data
prism.printallocs”
false
Disable bad driver check warning
prism.disableBadDriverWarning”
false
Force GPU, if GPU is PS 3 capable, disable GPU qualification check.
prism.forceGPU
false
Skip mesh normal computation
prism.experimental.skipMeshNormalComputation
false
Which driver to use
prism.order
prism.forcepowerof2
false
prism.noclamptozero
false
Try -Dprism.maxvram=[kKmMgG]
prism.allowhidpi
true
prism.maxvram
512 * 1024 * 1024
Try -Dprism.targetvram=[kKmMgG]|<double(0,100)>%
prism.targetvram
prism.poolstats
false
prism.pooldebug
false
prism.maxTextureSize
prism.minrttsize
prism.disableRegionCaching
prism.disableD3D9Ex
false
prism.disableEffects
false
prism.glyphCacheWidth
1024
prism.glyphCacheHeight
1024
Enable the performance logger, print on exit, print on first paint etc.
sun.perflog
sun.perflog.fx.exitflush
sun.perflog.fx.firstpaintflush
sun.perflog.fx.firstpaintexit
prism.supershader
true
Force uploading painter (e.g., to avoid Linux live-resize jittering)
prism.forceUploadingPainter
false
Force the use of fragment shader that does alpha testing (i.e. discard if alpha == 0.0)
prism.forceAlphaTestShader
false
Force non anti-aliasing (not smooth) shape rendering
prism.forceNonAntialiasedShape
false
Set Single GUI Threading
quantum.singlethreaded
false
Print quantum verbose
quantum.verbose
false
JavaFx framerate in FPS
javafx.animation.pulse
60
FX thread collision with Render thread ?
When running with the prism.threadcheck option I got the following error:
Of course how that related to my problem wasn’t clear, allthough maybe it could explain why the dirty flags were all ****ed up.
Overdraw and dirty draws
The option -Dprism.showoverdraw=true is interesting because it shows us which area we drew once (red), which twice (green), and so on. This showed me that the areas that didn’t update were not even marked as ‘dirty’. Suggesting that the problem was indeed with the setting and tracking of the dirty flag in the renderer. Therefore we tried the option -Dprism.dirtyopts=false and hooray all problems disappeared. Of course the app ran slightly slower, but at least it worked now.
When I was hit with startvation of some of the update threads in BpmDj, I was a bit puzzled. After all, I did use a ReentrantReadWriteLock in fair mode. A simple profiling showed that certain transaction where substantially more heavy (a writelock taking lets’ say 10 seconds), while the databasereads would merely take 1 second.
From that I concluded that because the writelock was held longer, other threads did not have the opportunity to have a fair amount of locktime themselves. E.g: the write lock is released, the longest waiting readlock is granted: that transaction is done within a second, and the writelock is granted again. And is not released for another 10 seconds.
To test this I set up a program to create 10 reader threads and 1 writer thread. Each thread would acquire a lock, wait some time (to simulate the ‘work’ done in the locked section) and then release the lock. This would be performed in a loop for about 10 seconds. Afterwards, we could measure how much time within the lock was spend for each thread and compare that with the amount of work the thread wanted to perform.
These were the results:
Unfair Lock
The unfair lock behaved, as expected, fairly unfair. If the writer had 10 times less work than the readerthreads, its locktime would be 8 times higher. If the writer had the same amount of work, it would have 16 times more locktime and if the writer had 10 times more work, then it would be granted 50 times more locktime.
That is, when the worker has 10 times less work than the readers, it has 8 times less locktime. If it has the same amount of work, it receives the same amount of locktime and if it has 10 times more work, then it is granted 9 times more locktime.
This is completely as expected, yet not something we might want, because it allows heavy tasks to block the lighter tasks.
A fair lock, prefixed with tryLock()
tryLock allows an app to check for a lock, and if it is not granted the lock to continue with something else. There are two tryLock variants. The first without parameters (tryLock()), the second with a timeout.
Trylock() screws up any scheduling that might have been in place and just barges in on anything the algorithm might be planning to do.
In this scenario, the writer thread pretty much does not get anything done. Whether it is performing 10 times less or 10 times more work, its locktime ranges from ~ /1000 to /10. This is very bad, because you might expect the tryLock to make the lock unfair, yet the results of an unfair lock (see above) are completely the opposite.
A fair lock, prefixed with tryLock(timeout)
There is a second variant of tryLock: one with a timeout; which can indeed be 0. If we apply that, we get the following results:
/10.0 /8.949334569534225
1.0 /1.0091078687281538
10.0 *9.016406673440223
which is in line with the straightforward fair lock.
In BpmDj, we used the tryLock() instead of tryLock(0), assuming that a timeOut of 0 would result in the same behavior between them.

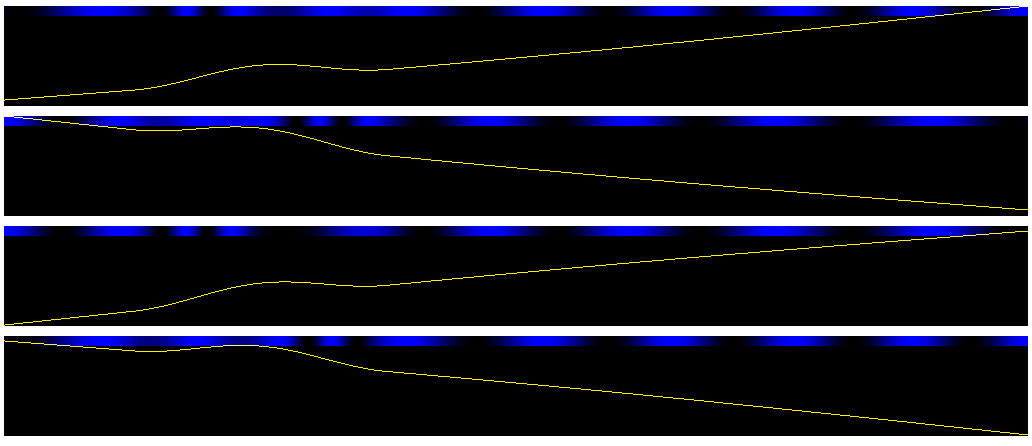 Option A & B are the concave lenses. Options C & D the convex lenses. In figure A we see the fast phase trend in front of the bulge, with a low phase trend behind it. These are not visible in the three other options. However: the difference between A & C (concave vs convex) is not necessarily easy to spot in this simulation. To figure that out very likely the 2D interferogram has to be looked at to figure out which lines are ‘pulled straight’
Option A & B are the concave lenses. Options C & D the convex lenses. In figure A we see the fast phase trend in front of the bulge, with a low phase trend behind it. These are not visible in the three other options. However: the difference between A & C (concave vs convex) is not necessarily easy to spot in this simulation. To figure that out very likely the 2D interferogram has to be looked at to figure out which lines are ‘pulled straight’