In BpmDj we load objects on demand: every time a particular object is accessed we load it from the database. This process happens automatically, and is implemented through a dictionary which maps an object id to a runtime representation.
In Java, this dictionary was a WeakDictionary, which is a dictionary from which values can be removed by the garbage collector. When when they got removed and the program accessed that object again, we would load it fresh from the database. This poor man caching is not particularly good because any garbage collect will remove all loaded (but unreferenced) objects, forcing the program to reload those object again. Even if the particular object is often used.
To solve that, we could force references to stay in memory by means of a round robin queue. Every time an object is accesed it is put in the next position in the buffer. As such, we ensure that the cache keeps X instances alive.
Sadly that strategy is unable to deal with a burst of requests. Any often used object will simply be pushed out of the buffer when a batch of new objects is loaded (like for instance when the song selector opens).
To alleviate this problem, we can, with each access, gradually increase the stickiness of a cache item. This idea turned out to be fairly efficient:
- every entry has a position in the buffer. Whenever the entry is hit, it moves to half its original position.
- every new element is placed in the middle of the buffer.
This strategy leads to a distribution where often used elements are in front of the buffer. Lesser used elements slowly walk their way out of the buffer until they are evicted. To avoid that items become too sticky (e.g: there can be items that have just enough been accessed to never leave the buffer again), it is useful to add a random element to this
- reposition an element to a random position between 0 and ratio * originalRank.
One could argue that having too many object id’s and too few actual objects would be a cause of concern, and it clearly is. Nevertheless, there often is a space tradeoff between holding on to an object and using its id.
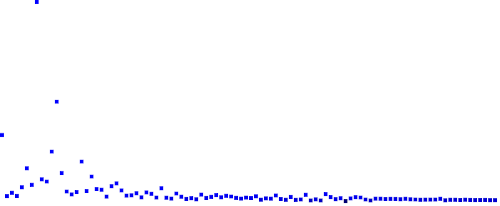
The image shows the buffer of a cache of capacity 100, with 800 distinct element randomly accessed. The access pattern was shaped according to a power law distribution. The front of the cache are those that are more sticky than the later part of the buffer. The height of each entry indicates its priority in the emitter.
The following picture shows the difference between 3 types of cache. The first is the roundrobin mentioned earlier, the second is a cache which keeps backreferences and the elevator cache is the one implemented here.
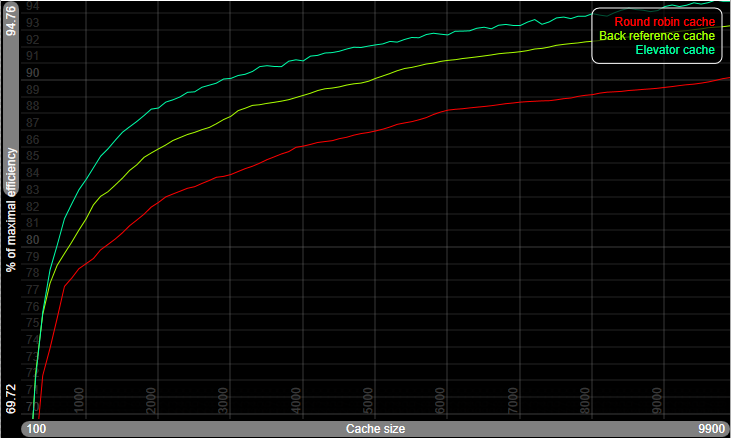
The data on which this was ran was the retrieveal of all startup objects BpmDj need, including the opening of the song selector. The total object count was 133632, of which 70291 unique ones.