I’m trying to understand a compiled theano function, which I printed with theano.printing.debugprint. The full monster is printed below, yet it is only with a couple of lines that I have some problems.
This code first computes a random yes/no vector in node 6. Node 5 is used to create the appropriate shape (resembling x)
Gemm{inplace} [id A] <TensorType(float32, matrix)> '(dcost/dW)' 23
|Dot22 [id B] <TensorType(float32, matrix)> '' 22
| |InplaceDimShuffle{1,0} [id C] <TensorType(float32, matrix)> 'x_tilde.T' 12
| | |Elemwise{Mul}[(0, 0)] [id D] <TensorType(float32, matrix)> 'x_tilde' 8
| | |RandomFunction{binomial}.1 [id E] <TensorType(float32, matrix)> '' 6
| | | |<RandomStateType> [id F]
| | | |MakeVector{dtype='int64'} [id G] <TensorType(int64, vector)> '' 5
| | | | |Shape_i{0} [id H] <TensorType(int64, scalar)> '' 1
| | | | | |x [id I] <TensorType(float32, matrix)>
| | | | |Shape_i{1} [id J] <TensorType(int64, scalar)> '' 0
| | | | |x [id I] <TensorType(float32, matrix)>
| | | |TensorConstant{1} [id K] <TensorType(int8, scalar)>
| | | |TensorConstant{0.75} [id L] <TensorType(float32, scalar)>
| | |x [id I] <TensorType(float32, matrix)>
| |Elemwise{Composite{((i0 - i1) * i2 * i1)}}[(0, 2)] [id M] <TensorType(float32, matrix)> '' 21
| |TensorConstant{(1, 1) of 1.0} [id N] <TensorType(float32, (True, True))>
| |Elemwise{Composite{scalar_sigmoid((i0 + i1))}}[(0, 0)] [id O] <TensorType(float32, matrix)> 'reduced' 15
| | |Dot22 [id P] <TensorType(float32, matrix)> '' 11
| | | |Elemwise{Mul}[(0, 0)] [id D] <TensorType(float32, matrix)> 'x_tilde' 8
| | | |W [id Q] <TensorType(float32, matrix)>
| | |InplaceDimShuffle{x,0} [id R] <TensorType(float32, row)> '' 2
| | |B [id S] <TensorType(float32, vector)>
| |Dot22 [id T] <TensorType(float32, matrix)> '(dcost/dreduced)' 20
| |Elemwise{Composite{((i0 * (i1 - Composite{scalar_sigmoid((i0 + i1))}(i2, i3)) * Composite{scalar_sigmoid((i0 + i1))}(i2, i3) * (i4 - Composite{scalar_sigmoid((i0 + i1))}(i2, i3))) / i5)}}[(0, 2)] [id U] <TensorType(float32, matrix)> '' 18
| | |TensorConstant{(1, 1) of -2.0} [id V] <TensorType(float32, (True, True))>
| | |x [id I] <TensorType(float32, matrix)>
| | |Dot22 [id W] <TensorType(float32, matrix)> '' 17
| | | |Elemwise{Composite{scalar_sigmoid((i0 + i1))}}[(0, 0)] [id O] <TensorType(float32, matrix)> 'reduced' 15
| | | |InplaceDimShuffle{1,0} [id X] <TensorType(float32, matrix)> 'W.T' 3
| | | |W [id Q] <TensorType(float32, matrix)>
| | |InplaceDimShuffle{x,0} [id Y] <TensorType(float32, row)> '' 4
| | | |B_Prime [id Z] <TensorType(float32, vector)>
| | |TensorConstant{(1, 1) of 1.0} [id N] <TensorType(float32, (True, True))>
| | |Elemwise{mul,no_inplace} [id BA] <TensorType(float32, (True, True))> '' 16
| | |InplaceDimShuffle{x,x} [id BB] <TensorType(float32, (True, True))> '' 14
| | | |Subtensor{int64} [id BC] <TensorType(float32, scalar)> '' 10
| | | |Elemwise{Cast{float32}} [id BD] <TensorType(float32, vector)> '' 7
| | | | |MakeVector{dtype='int64'} [id G] <TensorType(int64, vector)> '' 5
| | | |Constant{1} [id BE]
| | |InplaceDimShuffle{x,x} [id BF] <TensorType(float32, (True, True))> '' 13
| | |Subtensor{int64} [id BG] <TensorType(float32, scalar)> '' 9
| | |Elemwise{Cast{float32}} [id BD] <TensorType(float32, vector)> '' 7
| | |Constant{0} [id BH]
| |W [id Q] <TensorType(float32, matrix)>
|TensorConstant{1.0} [id BI] <TensorType(float32, scalar)>
|InplaceDimShuffle{1,0} [id BJ] <TensorType(float32, matrix)> '' 19
| |Elemwise{Composite{((i0 * (i1 - Composite{scalar_sigmoid((i0 + i1))}(i2, i3)) * Composite{scalar_sigmoid((i0 + i1))}(i2, i3) * (i4 - Composite{scalar_sigmoid((i0 + i1))}(i2, i3))) / i5)}}[(0, 2)] [id U] <TensorType(float32, matrix)> '' 18
|Elemwise{Composite{scalar_sigmoid((i0 + i1))}}[(0, 0)] [id O] <TensorType(float32, matrix)> 'reduced' 15
|TensorConstant{1.0} [id BI] <TensorType(float32, scalar)>
RandomFunction{binomial}.0 [id E] '' 6
Then at the second marked bold section, we see that node 16 performs the multiplication of two subnodes 14 and 13; which both are very similar except for a constant 0 or 1.
The code for node 14 reuses the same vector as node 5, but then casts it to float32 (which is node 7). And then the magic, the thing I do not understand happens. From that casted vector, a subtensor with constant 0 is selected. What does this do ?
The questions:
- Does the SubTensor (node 10 or node 9) select the first element of the tensor from node 7 ?
- Node 7 is merely a casted version of node 5. Does that vector contain the random data generated in node 6 ?
- Once the subtensors of node 7 are selected they are allowed to broadcast (node 13 and 14) to finally be multiplied with each other in node 16. Is it correct to say that node 16 thus computes the multiplication of the first random element with the second random element (from a random vector that might be quiet somewhat larger) ?
- When I print out the types of the nodes, we see that the output of the subtensor is indeed a scalar (as expected), yet the type of InPlaceDimensionShuffle and the ElementWise{mul} is (True,True). What for type is that ?
- If ElementWise{Mul} is not specifying ‘inplace’, (as happens in node 6), which of the two children is then modified ? Is it the node associated with the RandomFunction (thus node5) or does the randomFunction (node 6) provide us with another copy that can be modified ?
The image graph of the above function is given below. The yellow box is the one that confuses me because, if I read that right its output is merely a broadcastable 0.
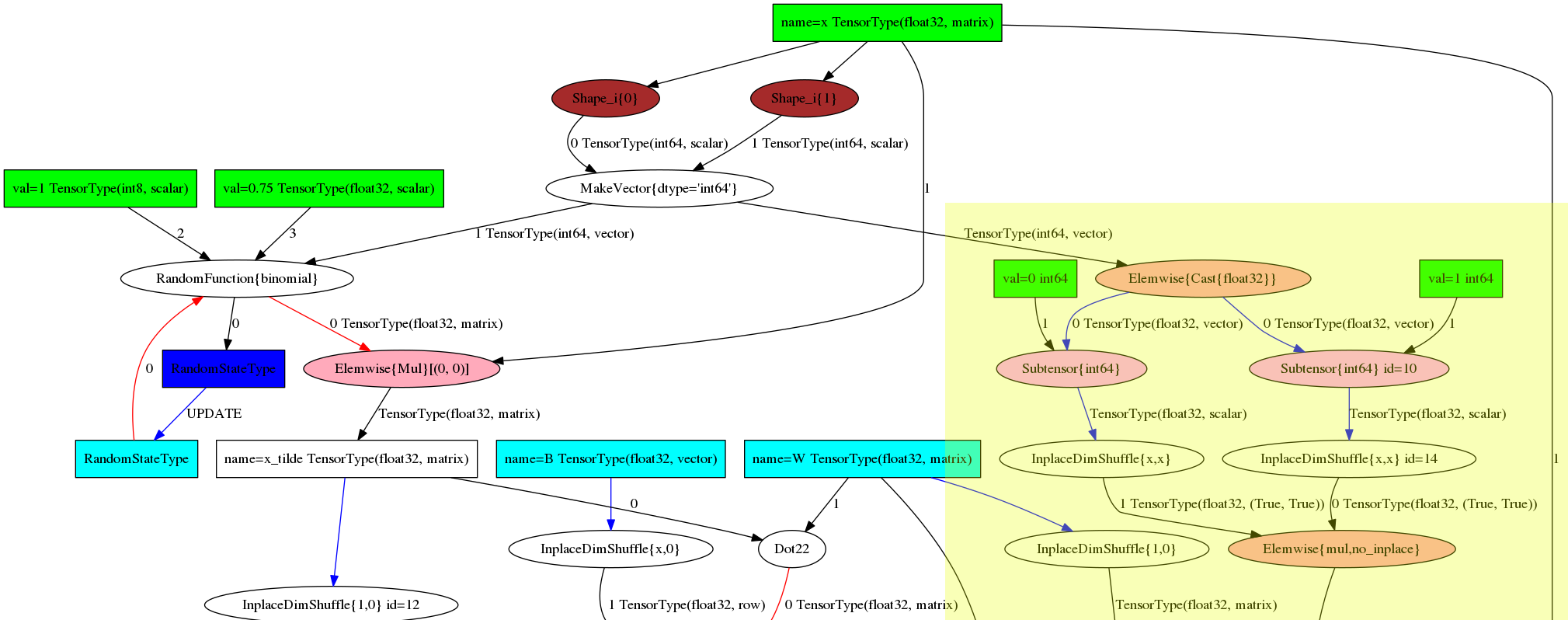
After a day bashing my head against this nonsense I fugerd out the following:
Makevector in node 5 uses the shape as input parameters and concatenates them into a small vector (See http://deeplearning.net/software/theano/library/tensor/opt.html#theano.tensor.opt.MakeVector).
Thus its output is a vector with two values: the dimensions of x. The random generator then uses that as input to generate a correctly sized vector. And the yellow box in the computation merely multiplies the two dimensions with each other to calculate the element-count of the input. Answering each of the subquestions:
- yes the subtensor selects respectively the 0th and 1st element of the intput vector.
- node 7, does indeed contain the casted data from node 5. However node 5 does not contain the random data.
- it is wrong to say that node 16 computes the multiple of the two first random values. Right is: node 16 computes the multiplication of the dimension sizes of the input vector x.
- The (True,True) type merely tells us the broadcasting pattern. See section http://deeplearning.net/software/theano/library/tensor/basic.html#all-fully-typed-constructors
- Without inplace an elementwise multiplication destroys one of its inputs. The inputs that are destroyed are marked in red. documentation on color coding http://deeplearning.net/software/theano/library/printing.html#theano.printing.pydotprint